 csarven
commented
4 years ago
csarven
commented
4 years ago In that context I meant "replace the representation" as to the intention over the wire. I've already said "affect a resource" prior to that.
re affects/effects, I was trying to make the point that "pure RDF" is irrelevant because the "target" is intended to be the resource, not the representation. Manipulating the graph.
I'm not aware of a definition where HTML+RDFa is an LDP-NR. A representation can be "fully" stated in "pure RDF" in HTML+RDFa, therefore it can be an LDP-RS.
 kjetilk
kjetilk TallTed
TallTed acoburn
acoburn elf-pavlik
elf-pavlik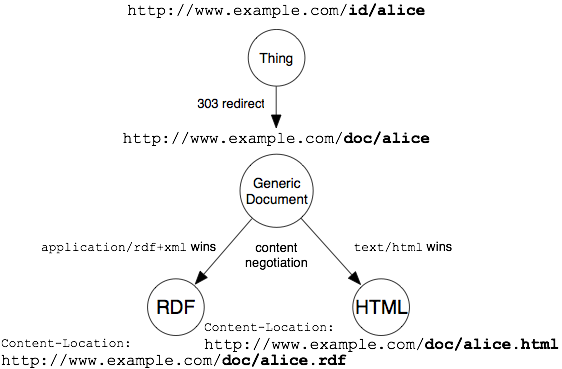

 RubenVerborgh
RubenVerborgh justinwb
justinwb
A topic that causes a lot of implementor and app-developer confusion is the handling of default resources for Containers -
index.htmland/orindex.ttl.Questions:
In either case, we should either add it to spec or provide non-normative text advising devs what to do.
Related issues: