Documents how to write a great liveblog post and how to submit your post for the GopherCon 2018 liveblog hosted by Sourcegraph at https://sourcegraph.com/gophercon
1
stars
2
forks
source link
From Prototype to Production: Lessons from Building and Scaling Reddit's Ad Serving Platform with Go #24
How Reddit built its ad-serving system using Go, and the lessons learned from the process.
Summary
The Reddit engineering team recently introduced Go into their stack to write a new ad-serving system to replace a third party system. Deval Shah talks us through the architecture of the new service, the Reddit team's experience using Go for the first time, and all the lessons they've learned from using Go to build this ad server.
Introduction to Reddit
Reddit is the frontpage of the internet. It's a social network with tens of thousands of interest communities, where people go to discuss the things that matter to them.
Reddit by the numbers:
5th/18th (US/World) Alexa rank
330M+ MAU
138K active communities
12M posts per month
2B posts per month
Any system that Reddit builds must scale to handle this level of traffic.
Ads Architecture Overview
The ads server handles the entire ads flow. Everything from the selecting advertisements to show to any post-processing after the ad is shown to the user, is handled by the ads server.
Ad Serving @ Reddit
There are several requirements for the Reddit ad server:
Scale: every single request on Reddit finds its way into the ad system, so it must deal with massive scale.
Speed: the ad server must be quick. They did not want ads to be a performance bottleneck that degrades the user experience. They set a requirement to respond with an ad in under 30ms.
Auction: make sure that the server is able to select the best ad based on the bid.
Pacing: the server must be able to allocate ads optimally.
Ad Serving @ Reddit before:
Before, whenever a user went to reddit.com, the reddit monolith backend would send a request to a third-party ad server. The third-party server would respond with one or more ads that it selected, and that gets returned to the user.
After a while, they realized that continuing to use the third-party ad server wouldn't work for them moving forward because it was:
Slow
Less customizable: many changes they wanted to make weren't supported by the third party.
Operationally opaque: they weren't able to know how certain things were implemented, couldn't control the quality of ads, etc.
decided to build an ad server, built a team of 3 people.
started with infra, then wrote the services, and then rolled it out to prod.
the system it is now in production.
Ad Serving Infrastructure:
apache thrift for all RPCs - around since 2007, one of the first rpc protocols. been using this since the very beginning. every system we build must be able to talk thrift
rocksDB for datastorage - OSS keyvalue store bt facebook. embeddable data store, avoids network hop otpimizd for highreads and writes.
decided to use Go as the main backend language. - quite obvious in hindisght. was the first time in REddit to use Go in prod. mostly python adn java in reddit. wanted to make sure Go would ea first class citizen in the languages reddit had, and supported everything reddit needed.
Ad Server Architecture:
This is the architecture of the new ad server:
A brief overview of how it works:
Reddit.com makes a call to a service called ad selector. This is the first service in the ad serving infrastructure. It is a thrift service, and receives the requests from reddit.com. It then calls a function called getAds, which handles getting and returning the ads to be shown to the user. The ad selector then calls the enrichment service.
Enrichment service is responsible for getting more data and information about the request, user, and other information it needs to find and select the most relevant ad. It collects all this information and returns it back to the ad selector.
After receiving the response from the enrichment service, ad selector selects the add, and returns the ad to reddit.com to be shown to the user. It also sends the response to Kafka.
Once the ad is shown to users, some post-processing needs to occur. The client sends an event HTTP request to the event tracker service. This event serves as confirmation that the ad got served. This event notification also gets shelled out to Kafka.
Kafka provides data to two Apache Spark jobs:
The Event Stats streaming job is always running, and it writes to the enrichment service to provide infromation that is used for learning to select better ads.
There is also the Pacing loop, which involves the Pacing Spark job. This involves a streaming job that counts how many ads have been shown for each advertiser, and and another job that makes sure advertisements are shown optimally.
In this architecture, the Go services are:
The ad selector:
has a 30ms P99 requirement
involves complex business rules for targeting and selection
runs an auction: all ads that the business logic rules, are in contention to get the ad shown, and ad selector handles this
Event tracker:
1ms P99 requirement
acknowledges logs and events
needs to be highly reliable
Enrichment service:
a Thrift service,
returns data to the ad selector,
has an embedded RocksDB database,
4ms P99,
for every request, it makes a prefix scan in Go, and gets a bunch of data and does computation and aggregation. The idea is to avoid network hops to get information, to make sure we serve the response quicky.
Some other Go tools and services at Reddit that won't be covere in-depth:
Reporting Service
Vault administration tool
Ad event generation service
Our experience with Go
This is the first experience Reddit has had with Go. Deval says the experience has been great so far. The effort started with two to three engineers using Go, and it has now grown to around a dozen engineers working on Go.
The main advantages they've seen with Go are:
Increased developer velocity: new engineers are onboarded and get familiar with the code very quickly. Go's emphasis on simplicity, and quick deploy and compile times mean tight feedback loops, which help a lot.
Great performance out of the box: there is not much tooling or optimization needed to makes Go fast, besides following best practices. Compared to his past experiences tuning JVM, and dealing with garbage collection, this is a nice experience for Deval.
Easy to focus on business logic: business logic is the hard part, and Go's simplicity and out-of-the-box performance helps the team focus on it.
Finally, Ad serving latency decreased drastically: response times dropped from 90ms to under 10ms.
Lessons learned
This is a set of 5 problems faced, how Reddit dealt with them, and the learnings from these challenges.
Problem 1: How to build production ready microservices?
Reddit had prior experience doing this for Python, but not in Go.
The initial prototype worked, by way of lots of StackOverflow reading and Googling, but it was clearly not going to scale with developers.
Some issues they saw were:
Logging, metrics, etc were all over the place
Changing the transport layer was hard
We needed repeatable patterns
They realized the Go community had solved these problems, so they looked at existing frameworks that had solved these problems. Some options they encountered:
They decided that Go-Kit made the most sense. The main reasons Reddit picked Go-Kit were that it:
Supports thrift
Is flexible, and not very descriptive. If Reddit wanted to move to gRPC, they want to be able to move over easily.
Has tools for logging, metrics, rate-limiting, tracing, circuit breaking, etc., which are standard requirements when running microservices in production.
Go-Kit @ Reddit. This is a diagram of the enrichment service using Go-Kit:
There are some things to note about this architecture. The center service has 2 implementations: an in-memory implementation (this was good and used for the prototype), and a RocksDB implementation which was used in the production implementation. The in-memory implementation still exists for local development.
There are several middleware layers: tracing, logging, and metrics. Finally, the Thrift transport is at the top level. This structure makes it easy to make changes. For example, if they wanted to change the transport layer from Thrift to gRPC, they'd only need to change the top layer.
Using Go-Kit was beneficial because it gave the team a good exmaple on how to structure Go code. They didn't have experience in this before, so using Go-Kit was helpful for understanding the typical structure for Go services.
Lesson 1: Use a framework/toolkit. Not neccesarily for everything you use Go for, but for production services that require metrics, logging, and so on, use libraries that have solved the problem rather than trying to do it yourself.
Problem 2: How to roll out the new system safely and quickly?
The ultimate goal was to roll out the new ad server with minimal impact to Reddit users, paying advertisers, other internal teams reliant on the ads team. The third party ad server was a black box, and Reddit needed a way to iterate rapidly, learn, and get better.
It was like changing airplanes mid-flight. They slowly added the new infrastructure around their third-party service, and when it was ready, they would rip it out.:
They started by injecting the ad selector into the request path, having it purely as a proxy. The system did the same thing it was doing before, but with the ad selector in place. This allowed them to scale up requests through the ad selector without without actually doing anything.
Then, instead of just being a proxy, they implemented and rolled out native ad selection in the ad selector service. Now, the ad selector would process the requests internally, but still act as a proxy and pass the request to the third party. The system would still use the third party response.
Then, they added Event Logger to implement logging for native responses, and set up Kafka.
They continued building out the rest of services, starting with stub services, and added logic along the way.
Eventually, once everything was in place, they cut off the third party ad server.
How did Go help with this? Go allowed them to make the move to the new ad server safely and easily, aided by these Go characteristics:
Go compiler is fast
Cross platform compilation support
Self-contained binary
Strong concurrency primitives
Lesson 2: Go makes rapid iteration easy & safe.
Problem 3: How to debug latency issues?
Once the new ad server was deployed, they did see some slowness, network glitches, bad deploys etc.
pprof is great if you know exactly which service is having issues. Distributed tracing, on the other hand, gives you visibility across services. They didn't have support for distributed tracing on the ads side, but they did have support for it elsewhere on Reddit's stack.
Why is tracing useful?
Identifies hotspots that cause high overall latency
Helps find other errors/unexpected behavior
Tracing is usually easy. You have a client and server. On the client side, you extract trace identifiers, and inject them into the request youre sending to the server. On the server side, when you get a request and identifiers, you put them into a context object and pass them around. This is very straightforward using HTTP and gRPC, and there's no reason not to do this.
But, reddit was dealing with Thrift, so they ran into some problems.
They took a look at Thrift alternatives, Facebook Thrift and Apache Thrift. The two key features they were looking for were support for headers and context objects:
They tried using FB thrift but there were some issues, mainly that the lack of a context object required messy workarounds, leading to messy code and complications. In Apache thrift, the context object was supported, but it doesnt have support for headers. So, the solution: add headers to Apache Thrift. This has been done for other languages, but not for Go. So, they added THeader to Apache Thrift. This means context objects are now supported, and headers can store trace identifiers.
If you want to see these changes, you can check out https://github.com/devalshah88/thrift. Deval hopes to get the changes through the contributing process and merge it upstream.
Here's a look the tracing code. The client wrapper just extracts out trace information from the context object, and adds it to the headers:
The server wrapper takes information from the headers and injects it into the context object so it can be passed around:
Having done all this work, distributed tracing proved to be very useful in debuggging latency issues. The takeaway, however, is lesson 3: Distributed tracing with Thrift and Go is hard.
Problem 4: How to handle slowness/timeouts?
At Reddit, they want systems to handle slowness gracefully. They never want users to suffer, so if there is slowness, Reddit would rather not show ads than degrade the user experience.
The two goals they had are:
Don't make users wait for too long
Don't waste resources doing unnecessary work
Use the context object to enforce timeouts within a service:
This is the code from the enrichment service of adding a deadline to context object, passing it through, and exiting early if deadline expires.
This result of this is good, but not enough:
The first graph shows how long it took to get responses from the enrichment service. This particular time frame had some slowness, but it did not let users wait longer than 25ms.
The second graph shows that on the server side, the enrichment service was processing the request for up to 70ms, so the server was wasting resources doing work after the client had already timed out and didn't need a response anymore.
What typically would be done is to propagate deadlines with HTTP. This code adds a timeout, which is passed to the server through the context object:
Thrift makes this hard. There is no context object used here. If the client times out, the goroutine doesnt know that and doesnt exit:
This is not great, but there are ways of fixing this:
One option is to add a deadline to the request payload. The client needs to include the deadline in the request. The server would inject deadline into the context object, and use it. This wasn't great because this change had to be made in all endpoints.
Instead, they passed the deadline as a thrift header. This is similar to how they pass trace identifiers. After this change, on the enrichment server side, they saw latencies similar to client side:
Lesson 4: Use deadlines within and across services.
Problem 5: How to ensure new features don't degrade performance?
Rapid iteration and complex business logic can lead to performance issues. The ad service team needed processes and tools to ensure they could move fast without violating the latency SLA. To do this, they made use of load testing and benchmarking.
This is what using you'd get in repsonse from Bender:
Load testing is really useful for testing changes under heavy load, and lets developers optimize new features for high load before pushing to production.
They also make use of benchmarking for all critical systems. This benchmarking code:
Gets you this output:
Benchmarking helps by:
preventing degradation by making changes that slow things down
giving visibility into how things have changed over time
informing developers about the tradeoffs that exist for different implementations
Lesson 5: Benchmarking and load testing is easy. Do it!
Recap:
Use a framework/toolkit
Go makes rapid iteration easy and safe
Distributed tracing with Thrift and Go is hard
Use deadlines within and across services
Use load testing and benchmarking
Conclusion:
Go has been instrumental in helping reddit build and scale the new ad serving platform - was easyto build and quick
We shared 5 important lessons we learned along the way
Try to use at least one of them in your next Go project.
 ryan-blunden
commented
6 years ago
ryan-blunden
commented
6 years ago
Presenter: Deval Shah
Liveblogger: Farhan Attamimi
How Reddit built its ad-serving system using Go, and the lessons learned from the process.
Summary
The Reddit engineering team recently introduced Go into their stack to write a new ad-serving system to replace a third party system. Deval Shah talks us through the architecture of the new service, the Reddit team's experience using Go for the first time, and all the lessons they've learned from using Go to build this ad server.
Introduction to Reddit
Reddit is the frontpage of the internet. It's a social network with tens of thousands of interest communities, where people go to discuss the things that matter to them.
Reddit by the numbers:
Any system that Reddit builds must scale to handle this level of traffic.
Ads Architecture Overview
The ads server handles the entire ads flow. Everything from the selecting advertisements to show to any post-processing after the ad is shown to the user, is handled by the ads server.
Ad Serving @ Reddit
There are several requirements for the Reddit ad server:
Ad Serving @ Reddit before:
Before, whenever a user went to reddit.com, the reddit monolith backend would send a request to a third-party ad server. The third-party server would respond with one or more ads that it selected, and that gets returned to the user.
After a while, they realized that continuing to use the third-party ad server wouldn't work for them moving forward because it was:
decided to build an ad server, built a team of 3 people. started with infra, then wrote the services, and then rolled it out to prod. the system it is now in production.
Ad Serving Infrastructure: apache thrift for all RPCs - around since 2007, one of the first rpc protocols. been using this since the very beginning. every system we build must be able to talk thrift rocksDB for datastorage - OSS keyvalue store bt facebook. embeddable data store, avoids network hop otpimizd for highreads and writes. decided to use Go as the main backend language. - quite obvious in hindisght. was the first time in REddit to use Go in prod. mostly python adn java in reddit. wanted to make sure Go would ea first class citizen in the languages reddit had, and supported everything reddit needed.
Ad Server Architecture:
This is the architecture of the new ad server:
A brief overview of how it works:
getAds, which handles getting and returning the ads to be shown to the user. The ad selector then calls the enrichment service.In this architecture, the Go services are:
Some other Go tools and services at Reddit that won't be covere in-depth:
Our experience with Go
This is the first experience Reddit has had with Go. Deval says the experience has been great so far. The effort started with two to three engineers using Go, and it has now grown to around a dozen engineers working on Go.
The main advantages they've seen with Go are:
Finally, Ad serving latency decreased drastically: response times dropped from 90ms to under 10ms.
Lessons learned
This is a set of 5 problems faced, how Reddit dealt with them, and the learnings from these challenges.
Problem 1: How to build production ready microservices?
Reddit had prior experience doing this for Python, but not in Go.
The initial prototype worked, by way of lots of StackOverflow reading and Googling, but it was clearly not going to scale with developers.
Some issues they saw were:
They realized the Go community had solved these problems, so they looked at existing frameworks that had solved these problems. Some options they encountered:
Go-Kit @ Reddit. This is a diagram of the enrichment service using Go-Kit:
There are some things to note about this architecture. The center service has 2 implementations: an in-memory implementation (this was good and used for the prototype), and a RocksDB implementation which was used in the production implementation. The in-memory implementation still exists for local development.
There are several middleware layers: tracing, logging, and metrics. Finally, the Thrift transport is at the top level. This structure makes it easy to make changes. For example, if they wanted to change the transport layer from Thrift to gRPC, they'd only need to change the top layer.
Using Go-Kit was beneficial because it gave the team a good exmaple on how to structure Go code. They didn't have experience in this before, so using Go-Kit was helpful for understanding the typical structure for Go services.
Lesson 1: Use a framework/toolkit. Not neccesarily for everything you use Go for, but for production services that require metrics, logging, and so on, use libraries that have solved the problem rather than trying to do it yourself.
Problem 2: How to roll out the new system safely and quickly?
The ultimate goal was to roll out the new ad server with minimal impact to Reddit users, paying advertisers, other internal teams reliant on the ads team. The third party ad server was a black box, and Reddit needed a way to iterate rapidly, learn, and get better.
It was like changing airplanes mid-flight. They slowly added the new infrastructure around their third-party service, and when it was ready, they would rip it out.:
How did Go help with this? Go allowed them to make the move to the new ad server safely and easily, aided by these Go characteristics:
Lesson 2: Go makes rapid iteration easy & safe.
Problem 3: How to debug latency issues?
Once the new ad server was deployed, they did see some slowness, network glitches, bad deploys etc.
pprof is great if you know exactly which service is having issues. Distributed tracing, on the other hand, gives you visibility across services. They didn't have support for distributed tracing on the ads side, but they did have support for it elsewhere on Reddit's stack.
Why is tracing useful?
Tracing is usually easy. You have a client and server. On the client side, you extract trace identifiers, and inject them into the request youre sending to the server. On the server side, when you get a request and identifiers, you put them into a context object and pass them around. This is very straightforward using HTTP and gRPC, and there's no reason not to do this.
But, reddit was dealing with Thrift, so they ran into some problems.
They took a look at Thrift alternatives, Facebook Thrift and Apache Thrift. The two key features they were looking for were support for headers and context objects:
They tried using FB thrift but there were some issues, mainly that the lack of a context object required messy workarounds, leading to messy code and complications. In Apache thrift, the context object was supported, but it doesnt have support for headers. So, the solution: add headers to Apache Thrift. This has been done for other languages, but not for Go. So, they added THeader to Apache Thrift. This means context objects are now supported, and headers can store trace identifiers.
If you want to see these changes, you can check out https://github.com/devalshah88/thrift. Deval hopes to get the changes through the contributing process and merge it upstream.
Here's a look the tracing code. The client wrapper just extracts out trace information from the context object, and adds it to the headers:
The server wrapper takes information from the headers and injects it into the context object so it can be passed around: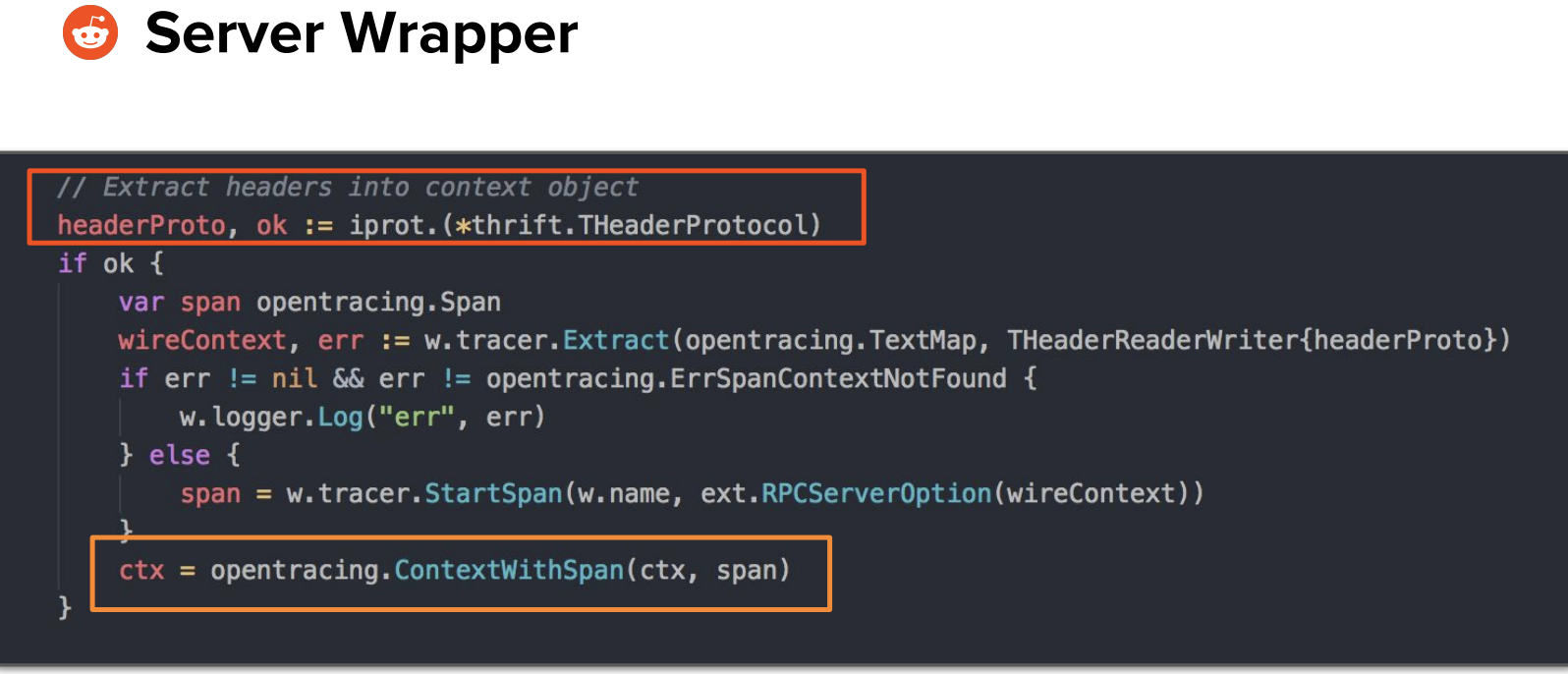
This code is from https://github.com/devalshah88/thrift-tracing.
Having done all this work, distributed tracing proved to be very useful in debuggging latency issues. The takeaway, however, is lesson 3: Distributed tracing with Thrift and Go is hard.
Problem 4: How to handle slowness/timeouts?
At Reddit, they want systems to handle slowness gracefully. They never want users to suffer, so if there is slowness, Reddit would rather not show ads than degrade the user experience.
The two goals they had are:
Use the context object to enforce timeouts within a service: This is the code from the enrichment service of adding a deadline to context object, passing it through, and exiting early if deadline expires.
This result of this is good, but not enough: The first graph shows how long it took to get responses from the enrichment service. This particular time frame had some slowness, but it did not let users wait longer than 25ms.
The first graph shows how long it took to get responses from the enrichment service. This particular time frame had some slowness, but it did not let users wait longer than 25ms.
The second graph shows that on the server side, the enrichment service was processing the request for up to 70ms, so the server was wasting resources doing work after the client had already timed out and didn't need a response anymore.
What typically would be done is to propagate deadlines with HTTP. This code adds a timeout, which is passed to the server through the context object: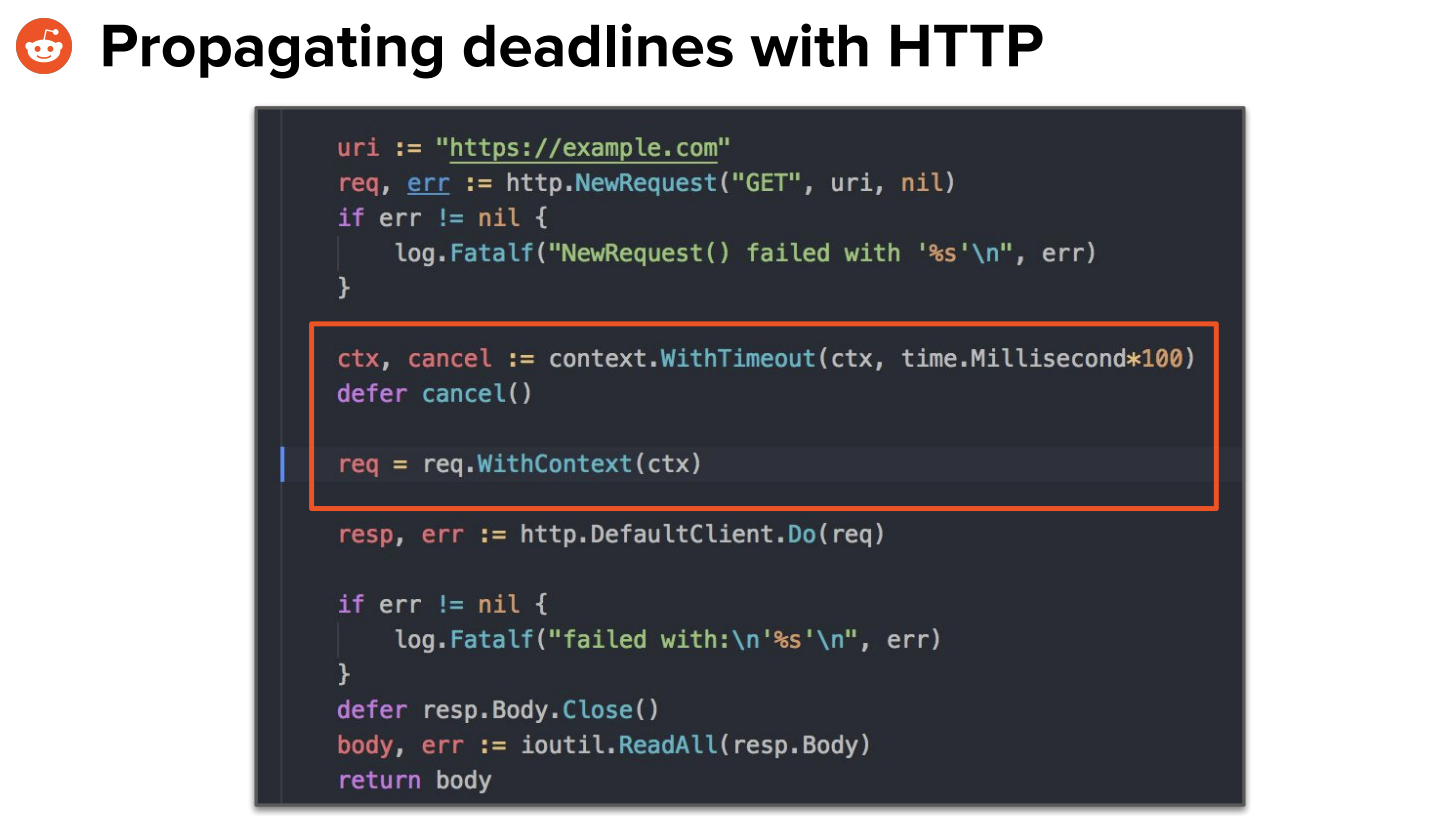
Thrift makes this hard. There is no context object used here. If the client times out, the goroutine doesnt know that and doesnt exit:
This is not great, but there are ways of fixing this:
One option is to add a deadline to the request payload. The client needs to include the deadline in the request. The server would inject deadline into the context object, and use it. This wasn't great because this change had to be made in all endpoints.
Instead, they passed the deadline as a thrift header. This is similar to how they pass trace identifiers. After this change, on the enrichment server side, they saw latencies similar to client side:
Lesson 4: Use deadlines within and across services.
Problem 5: How to ensure new features don't degrade performance?
Rapid iteration and complex business logic can lead to performance issues. The ad service team needed processes and tools to ensure they could move fast without violating the latency SLA. To do this, they made use of load testing and benchmarking.
Load testing using bender: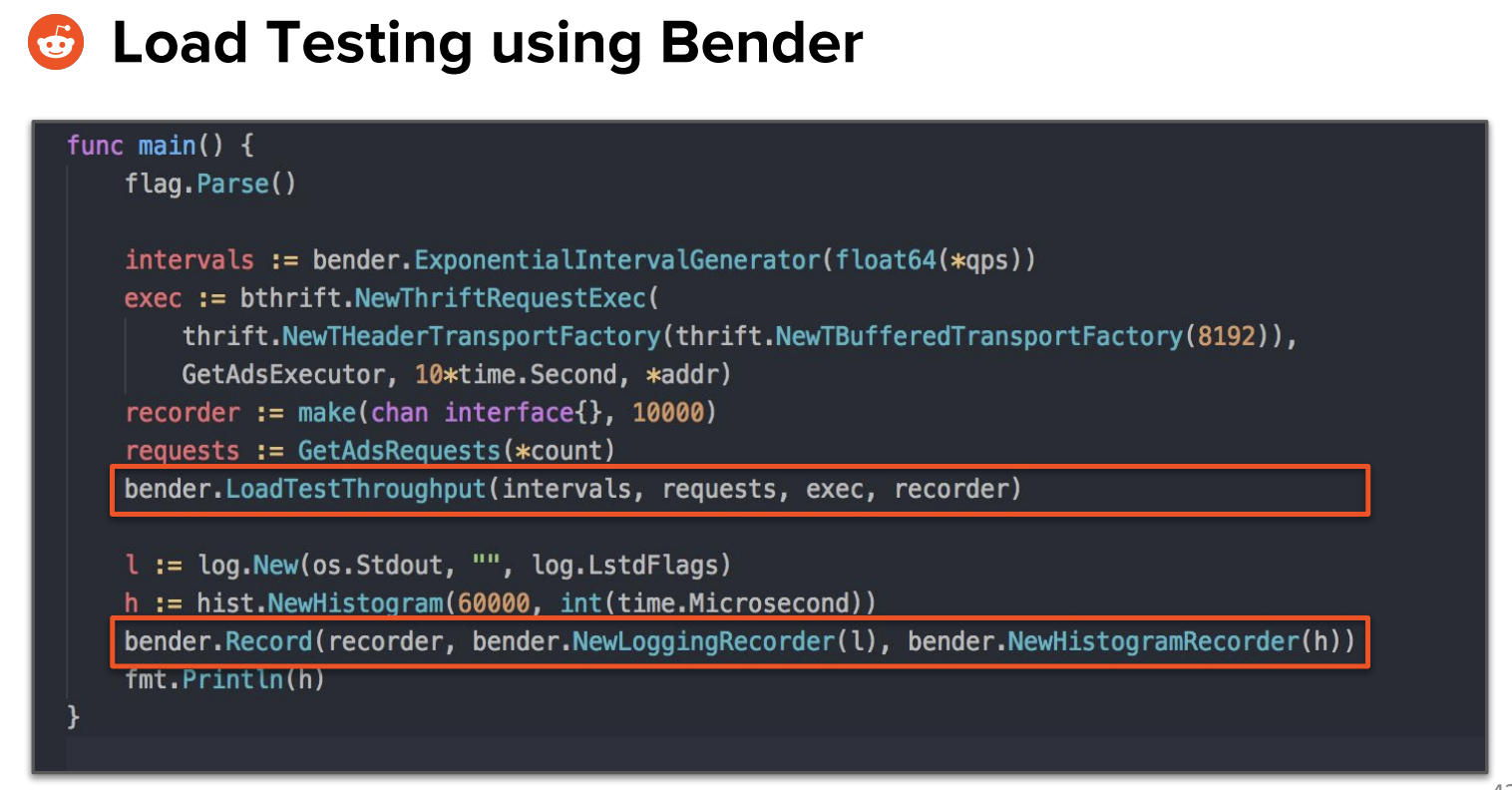
This is what using you'd get in repsonse from Bender:
Load testing is really useful for testing changes under heavy load, and lets developers optimize new features for high load before pushing to production.
They also make use of benchmarking for all critical systems. This benchmarking code: Gets you this output:
Gets you this output:

Benchmarking helps by:
Lesson 5: Benchmarking and load testing is easy. Do it!
Recap:
Conclusion: