 mgod
commented
5 years ago
mgod
commented
5 years ago I'm surprised it's working at all - when creating a CharacterTokenizer, you must set a non-empty token terminator and you're using "". I would recommend setting that to "," or ";". I think this will resolve issue 1.
I'm not sure what you're describing in the second issue. The tokenizer does allow the user to continue to type in the field if the token limit is met because otherwise you would not be able to delete tokens. I'm pretty confused by your configuration in general. What input are you trying to get from the user? It looks like maybe you're trying to get a single email address?
 micaelomota
micaelomota


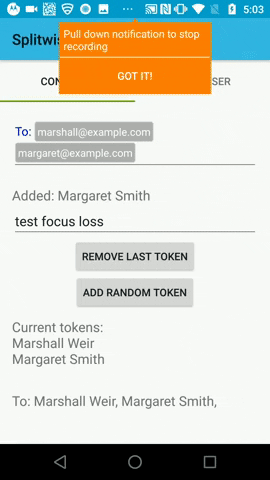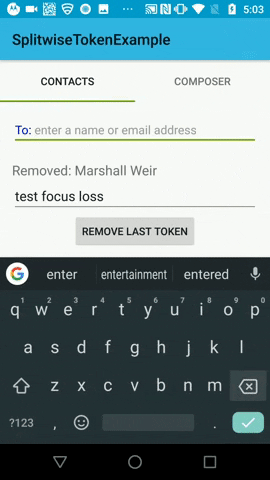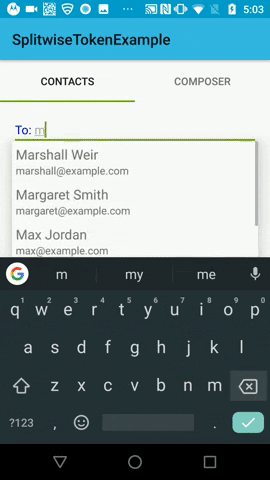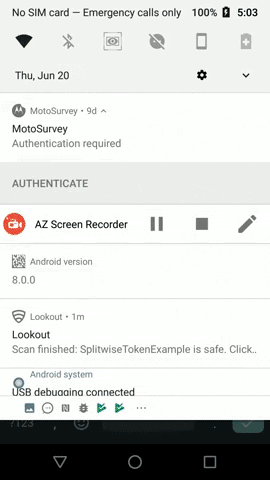
Using the latest version 'com.splitwise:tokenautocomplete:3.0.1@aar' in my application.
And used below method for the edit field
But It is having some issues in Samsung and OnePlus Android devices, which are given below. Issue No 1. - This issue produced by below steps:-
"pabi", it is resetting to the first letter"p"only.Issue No 2. - There is another issue like it is allowing to enter the text from keyboard after created one token (as it should not allow, because - fieldView.setTokenLimit(1) is applied to the field. And entered text is shown the keyboard suggestions, not in the tokenise field.) So there is issue for deleting/removing the tokenise field.
can you reply the solution or make a new release with the fixes? Thanks.