 kubu4
commented
9 years ago
kubu4
commented
9 years ago I can't figure out how to annotate my files. Assume I don't provide the Ensembl GTF file when processing with TopHat (I could do this, but I'm trying to avoid re-running everything I've already done), how can I use downstream GTF files that are generated by cufflinks and/or cuffmerge for annotation?
I'm looking through BEDtools, but can't figure out how to proceed.
 sr320
sr320 jheare
jheare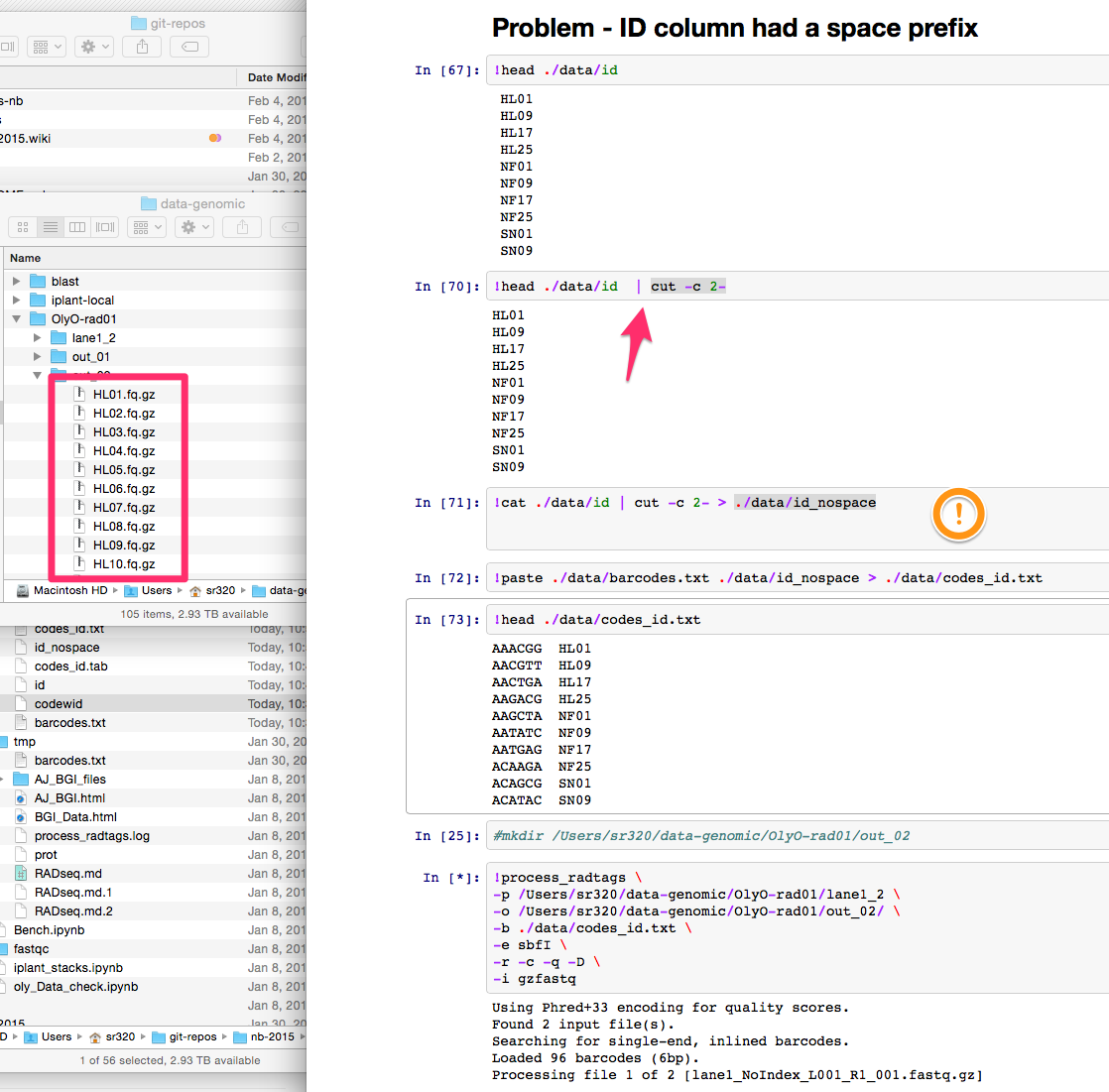
 willking2
willking2 jldimond
jldimond lisa418
lisa418
What is one thing you are having trouble with, that if solved would have the greatest impact on your analysis workflow?