 mratsim
commented
3 years ago
mratsim
commented
3 years ago Compiling with sanitizers
nim c -d:openmp -d:danger --cc:clang --passC:"-fsanitize=undefined" --passC:"-fsanitize=address" --passL:"-fsanitize=address" --passL:"-fsanitize=undefined" --outdir:build -r --verbosity:0 --hints:off --warnings:off --passC:"-g" benchmarks/bench_all.nim arnetheduck
arnetheduck



This adds batched multi-signature verification to the library. Both with serial or parallel backend with OpenMP. The algorithm chosen is recursive divide-and-conquer instead of the usual parallel for loop, this makes it easily portable to any threadpool that supports task spawning.
Disambiguations
Unfortunately it is very easy to get confused with BLS signatures, signature aggregation and multi signature.
BLS signature level 1
We have a triplet (pubkey, message, signature) to verify. This is the base case
verifyhttps://github.com/status-im/nim-blscurve/blob/b0a1d149e97142649bd99c4acebcf551b7b05dda/blscurve/bls_sig_min_pubkey.nim#L108-L114BLS signature level 2
We have N public keys verifying the same message (attesting for a block for example) This is
fastAggregateVerify. https://github.com/status-im/nim-blscurve/blob/b0a1d149e97142649bd99c4acebcf551b7b05dda/blscurve/bls_sig_min_pubkey.nim#L230-L253As shown in benchmark there is no use in parallelizing this case as by exploiting pairings curve properties can accelerate verification of an aggregate signature against 128 public keys only take an extra 5.6%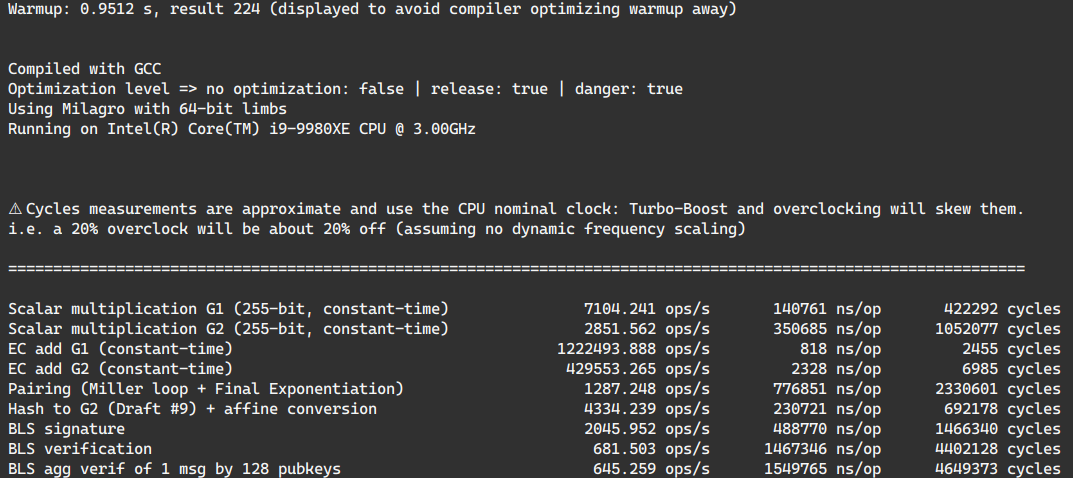
BLS signature level 3
We have N public keys verifying N messages which could be:
not counting deposits signatures which may be invalid. Furthermore we can apply that to B blocks to collect N*B signature sets.
This is the
aggregate(var Signature, Signature)procedures andaggregateVerifyprocedures: https://github.com/status-im/nim-blscurve/blob/b0a1d149e97142649bd99c4acebcf551b7b05dda/blscurve/blst/blst_min_pubkey_sig_core.nim#L141-L186 https://github.com/status-im/nim-blscurve/blob/b0a1d149e97142649bd99c4acebcf551b7b05dda/blscurve/bls_sig_min_pubkey.nim#L153-L156 https://github.com/status-im/nim-blscurve/blob/b0a1d149e97142649bd99c4acebcf551b7b05dda/blscurve/bls_sig_min_pubkey.nim#L177-L179Those appear in the spec https://github.com/ethereum/eth2.0-specs/blob/v1.0.0/specs/phase0/beacon-chain.md#bls-signatures but are never used hence as we kept almost literally to the spec we didn't use them.
The estimated perf improvement on a single block verification for the serial and parallel implementation are in the code at https://github.com/status-im/nim-blscurve/blob/b0a1d149e97142649bd99c4acebcf551b7b05dda/blscurve/blst/blst_min_pubkey_sig_core.nim#L401-L422 In summary by batching even on a single processor we have 2x faster single block verification. If batching 10 blocks, instead of a naive cost of 1000, the cost becomes
20*10 (blinding 64-bit) + 50 (Miller loop) + 50 (final exp) = 300for a 3.33x acceleration factorThe performance improvements are superlinear and increase with both the number of processors and the workload.
Batching signatures
The existing aggregateVerify functions are impractical as we need to save state for batching. Instead we can pass a collector object to collect all (publicKey(s), message, signature) triplets (called Signature Sets here, as in Lighthouse and Prysm) in a block and then run verification once everything as been collected.
We actually do not core which verification fails, if any fails we need to drop the block anyway (unless some precise attacker accountability on invalid signatures is introduced).
This PR implements such collector object
BatchBLSVerifierwith a serial and parallel backend using OpenMP.Parallel implementation
Contrary to BLST example which uses a simple parallel for loop followed by serial for loop for merging partial pairings, we use a recursive divide-and-conquer strategy, this doesn't change the cost of computing the partial pairings but significantly improve merging them (logarithmic vs linear) and merging partial pairings is a costly operation.
Reference merging code: https://github.com/supranational/blst/blob/7cda6fa09bfa9d789bd30b31dc1ae91656ee2f88/bindings/rust/src/lib.rs#L756-L759
As an example on Pyrmont 2 weeks old, 100000 blocks, a linear merge on my machine would have an estimated cost of 0.3s per 20 blocks which lead to 100000/20 * 0.3 = 1500s spent, 20 weeks would be 15000s so 4.1 hours.
With a divide-and-conquer approach on a 6 core CPU as in the code example we save half that https://github.com/status-im/nim-blscurve/blob/b0a1d149e97142649bd99c4acebcf551b7b05dda/blscurve/bls_batch_verifier.nim#L242-L245
https://github.com/status-im/nim-blscurve/blob/b0a1d149e97142649bd99c4acebcf551b7b05dda/blscurve/bls_batch_verifier.nim#L204-L262
Nimbus unknowns
A RFC will be submitted to discuss the following details
process_blockto allow batching of all signatures within a block. This only affects consensus.batch_process_blocksto batch all signatures of many blocks.We will likely need 1 or 2 nodes in our fleet to test this PR on Pyrmont and the consequent Nimbus refactoring that will likely be complex to rebase and will live in a branch for a long time.