 stlehmann
commented
2 years ago
stlehmann
commented
2 years ago from my testing of large amounts of data, the acatual ADS read of all the bytes is super quick but can take seconds to unpack it into the right format
That is interesting. I agree, looking at the code there could be some room for improvement in regards of speed. @chrisbeardy you're welcome to tackle on some improvements here 👍
Also we now have WSTRING support in pyads and I just see that it is not supported for structures, yet. I'll open an issue for that.
 chrisbeardy
chrisbeardy
The current implementation of dict_from_bytes loops over all the items in an array, both of each array in the structure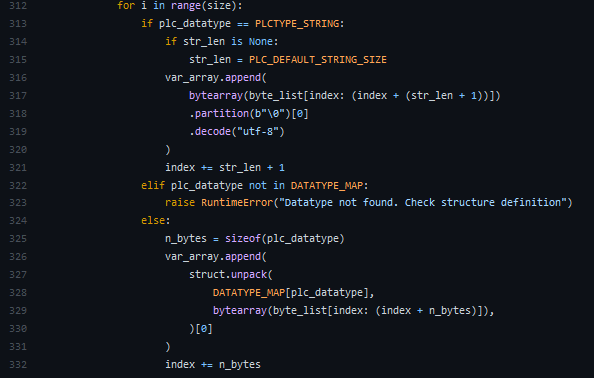
for i in range(size)and of structure if an array of structuresfor structure in range(0, array_size):When reading large arrays this is slow, can this be optimised better use of struct.unpack?
Instead of unpacking one item of the array at a time, can this function be refactored to struct.unpack the whole array at once.
for i in range(size)and changefrom:
to:
I'm also unsure if it is the unpack which is slow too so we could build up an unpack string, then unpack in one go, this would also benefit if
for structure in range(0, array_size)?I've been meaning to tackle this for a while and often when reading large amounts of data I use multiple read_by_names instead as this is actually faster, but you then have to workaround the fact that the data is being read over multiple ADS cycles. I raise this now as could be thought about when refactoring for #288.
Happy to look at other alternatives too to decrease the time taken to go from bytes to the dictionary, from my testing of large amounts of data, the acatual ADS read of all the bytes is super quick but can take seconds to unpack it into the right format