 babakfp
commented
3 years ago
babakfp
commented
3 years ago @Rich-Harris Hi, How can I contact you on Discord or Twitter? I couldn't find any way so I decided to message you here.
Open Rich-Harris opened 3 years ago
babakfp
commented
3 years ago @Rich-Harris Hi, How can I contact you on Discord or Twitter? I couldn't find any way so I decided to message you here.
 pago
commented
3 years ago
pago
commented
3 years ago Could you clarify this part a little bit?
This extends to parameters (which I think should be positional), for messages that need them
The part I'm wondering about is whether that could result in changes to the translation messages invalidating existing code due to a shift of parameter order. Apart from that potential risk I also feel like having an object with keys and values might actually add to the readability of the code.
Quick example:
$t.clicked_n_times(n);
// compared to
$t.clicked({times: n});Everything else sounds outstanding and I can't wait to start using it. Thank you for tackling this issue.
 tempo22
commented
3 years ago
tempo22
commented
3 years ago Hi,
Allow me to jump into the discussion here. I'm planning a new project and a robust i18n is a must-have on it.
I have worked in the past with Drupal and Wordpress websites, both using po file format. It seems to be made for this purpose. We may use JSON but it would be nice to see how they handle the pluralization and other translation workflows.
But as you said, selecting a locale is an important step that should be done before loading translation.
 floratmin
commented
3 years ago
floratmin
commented
3 years ago I have just written something to extract translation functions calls into .po files. Currently, I am integrating it into a rollup plugin. My idea is to use the tooling of gettext for managing the translation lifecycle. I think that we could even use ICU messageformat strings inside .po files. The advantage of .po files is that it is easy to provide a lot of extra context, which is often very important for translators. You can check my repository out at gettext-extractor-svelte.
Then there is the package gettext-to-messageformat which converts .po files with gettext format to messageformat. If instead ICU messageformat strings are used in .po files, the conversion is trivial. An option to use json with ICU messageformat instead of .po files should also be easy to implement, but for this, I have to investigate how comments are provided to translators.
Then the messageformat project can compile the translated strings into pure functions which can then be injected when building the application and replace the translation function and function calls.
The actual translation function could be changed according to the needs of the project. Simple projects would only go with the message string, while other projects could provide unique context and detailed comments for each message string.
 zwergius
commented
3 years ago
zwergius
commented
3 years ago Hey,
Here is what I use for selecting the initial language
import { supportedLanguages } from '$lib/constants';
const DOCUMENT_REGEX = /^([^.?#@]+)?([?#](.+)?)?$/;
export function getContext({ headers, path }) {
const isDocument = DOCUMENT_REGEX.test(path);
if (!isDocument) return;
let language = path.split('/')[1];
// language not in url
if (supportedLanguages.indexOf(language) === -1) {
language = supportedLanguages[0];
if (headers['accept-language']) {
const headerLang = headers['accept-language'].split(',')[0].trim().slice(0, 2);
if (headerLang && headerLang.length > 1) {
if (supportedLanguages.indexOf(headerLang) !== -1) language = headerLang;
}
}
}
return { language };
}
export function getSession({ context }) {
const { language } = context;
return { language };
}
export async function handle({ request, render }) {
const rendered = await render(request);
if (rendered.headers['content-type'] === 'text/html') {
const { language } = request.context;
return {
...rendered,
body: rendered.body.replace('%lang%', language)
};
}
return rendered;
}I use the accept-language header and then in my src/routes/index.svelte I have
<script context="module">
export async function load({ session }) {
return {
status: 303,
redirect: `/${session.language}`
};
}
</script>I then in src/routes/[lang]/$layout.svelte check if the lang param is supported and if not 404
I than have a static yaml file that holds all translations
This works fairly well for static pages which is what I do mostly... I put this together after reading a whole bunch of issues, initially trying svelte-i18n which I then decided was overkill...
 kobejean
commented
3 years ago
kobejean
commented
3 years ago I've used svelte-i18n before and one big reason I prefer the $t('text') format over $t.text is that it is supported in this vs code plugin: i18n-ally . It's a great way to manage your translations, have translation reviews/feedback and it even allows machine translation.


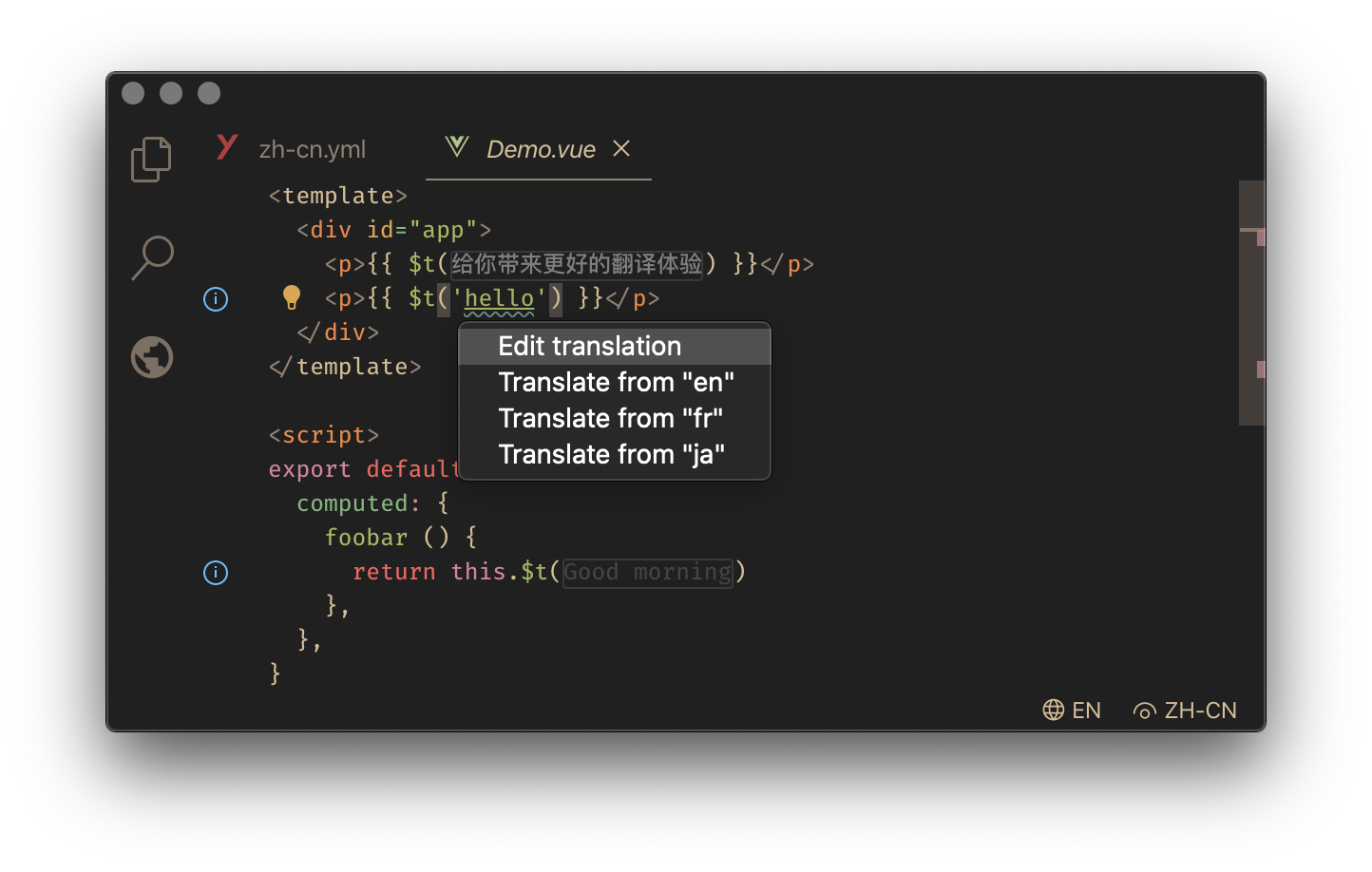
babakfp
commented
3 years ago svelte-i18nAn example from svelte-i18n
<script>
import { _ } from 'svelte-i18n'
</script>
<h1>{$_('page.home.title')}</h1>
<nav>
<a>{$_('page.home.nav', { default: 'Home' })}</a>
<a>{$_('page.about.nav', { default: 'About' })}</a>
<a>{$_('page.contact.nav', { default: 'Contact' })}</a>
</nav>I think this is a 100% bull sheet. Look at all of the work that you need to do, just to set a default value for a translateable value. You are not done, you also need to create a .json file and write you all strings there. Also, you need to pick a name for your translatable string as a reference. for example:
// en.json
{
"hello_world": "Hello, World!"
}$ character is here too!!. I hate this, but no worries, because of my PHP background experience I'm immune :stuck_out_tongue_winking_eye:I know that this was the best possible way for them to create this library. I know that they put in a lot of work and they did what they were possible of doing it.
I explained what I expect from a layout system here and nothing, we are going to experience the same problems in the SvelteKit too. Now I want to explain what I expect from a translation system because I need to say what I think about it and how I think it needs to be solved because if I don't, I think it's gonna be really bad :disappointed:.
Also, I want to say that I get banned (2 of my accounts) from the community discord group. Admins were like "Nah, I don't like this guy, clicking on the ban button". (The person that reading this, if you get banned from the discord channel, knows that there was no problem with you). If you didn't like what I explain here, you can stick with this subject that 2 of my accounts get banned, instead of saying what you don't agree with :smile:. I wanted to complain about it with Mr. Rich Harris but, it seems he is so busy. Oh God, now I feel like I complaining like a baby :laughing:
Let's keep going
Exactly the same that we are using in the current tools. For example Wordpress:
<?php echo __('Hello, World!'); ?>I sawed the same syntax in Laravel but I don't have a lot of information about it. Any Laravel developers here to explain to us about how it worlds and how was the experience?
With this, you don't need to write all of those svelte-i18n junk you sowed above!.
Automatically the strings inside the functions get write inside the .pot file. You insert the .pot file inside a software called Poedit. You select the language and then Poedit will show you the all translatable strings. Translate the strings that you see and much more features, that will make life easier for you, rather than creating a .json file and blah blah blah.
You are gonna have 3 files
.pot: Your all strings live here (input). translatable-strings.pot..po: Translated string (output). [language].po..mo Same as the .po but the file isn't editable!. [language].mo.You are just gonna write your string inside the __() function. All of the other work going to take care of by the system it selves.
$t(), oh my brain :worried:Hello world and after: Hello World.Hello string and the hello string are treated as different strings.$t()$t(), oh my brain :worried:Welcome instead of greeting. https://github.com/sveltejs/kit/issues/1274#issue-871199686$ kvetoslavnovak
commented
3 years ago
kvetoslavnovak
commented
3 years ago Big THANK YOU to all dealing with the translation topic. i18n is a huge “must” for all non-US regions. E.g. for us in EU especially.
 Kapsonfire-DE
commented
3 years ago
Kapsonfire-DE
commented
3 years ago @babakfp i disagree with the point of you have to define keys and default translations you can directly use
{$_('Won {n, plural, =0 {no awards} one {# award} other {# awards}}', { values: { n: 2}})}no need to define a key and define a default translation - same behaviour as gettext
tempo22
commented
3 years ago @babakfp i disagree with the point of you have to define keys and default translations you can directly use
{$_('Won {n, plural, =0 {no awards} one {# award} other {# awards}}', { values: { n: 2}})}no need to define a key and define a default translation - same behaviour as gettext
The plural handling in your example will create a mess where the sentence order is totally different depending on the language:
I won 1 award -> J'ai gagné 1 prix
I won 2 awards -> J'ai gagné 2 prix
I won no awards -> Je n'ai gagné aucun prix
In PO files, the plural is handled with the following syntax
msgid "I won {n} trip"
msgid_plural "I won {n} trips"
msgstr[0] "J'ai gagné {n} voyage"
msgstr[1] "J'ai gagné {n} voyages"The number of plural variant depend on the language, read this for more informations
Using a more complex example:
{#if n == 0 }
{$t('Hello {firstname}, you have no new messages', {firstname: user.firstname})}
{:else}
{$t('Hello {firstname}, you have {n} new message', 'Hello {firstname}, you have {n} new message', n, {n: n, firstname: user.firstname})}
{/if}we could have the translation function with the following definition:
function t(msgid: string, replacements?: object): string
function t(msgid: string, msgidPlural: string, count: number, replacements?: object): string@tempo22 it's the ICU MessageFormat You gonna create a fitting translation string for french in your translation files.
floratmin
commented
3 years ago @Kapsonfire-DE ICU messageformat can get very similar to gettext:
{
$_(
`{
n, plural,
=0 {I won no awards}
one {I won one award}
other {I won # awards}
}`,
{ n: 2 }
)
}This is also the recommended way for writing messageformat strings. Otherwise, an external translator can get confused.
I think that some have the perspective of translating their app/page on their own or in house. But we should not forget, that there are also many use cases where we need professional translations and where we need to provide as much context to the translators as possible. Because of this, I like gettext (.po, .pot, .mo) very much. There are a lot of editors, there is an established workflow and many translators know this system.
But messageformat is sometimes more flexible, especially you can use the Intl functions directly, which avoids a lot of bloat. And because messageformat are strings we can put these strings also into .po files and use the gettext workflow and infrastructure. If the context is not needed, we can put these strings still into JSON or YAML files and use simpler functions.
An other case is when there is already a project which is based on gettext. Then it can make very much sense to use gettext instead of messageformat, because all translations from before can be reused. So it would be nice if there is some flexibility.
 johnnysprinkles
commented
3 years ago
johnnysprinkles
commented
3 years ago More important than the specific syntax is that we understand the typical flow of translations... I can describe how it works at Google for example, which is probably similar to other large tech companies.
Translations are a continuous and ongoing process. Commits land constantly and most of them have new strings, then in a periodic process we extract all the untranslated strings and send them off for translation. Google and Amazon I know have "translation consoles" that manage it for you. So say weekly you pull the strings and send them off, then they come back a week or more later, you check that data in and it's available after your next deployment.
One thing to note is that, if you're using human translators, you must have a description. The English text alone isn't enough to get a good translation. Not sure how this changes as we move more and more to machine translation. Early on at Google I worked on a GWT project where the translations were declared in code like this:
<ui:msg description="Greeting">Hello, world</ui:msg>But most stuff at Google uses goog.getMsg(), i.e.
@desc Greeting
const MSG_GREETING = goog.getMsg('Hello, world');What Rich is describing with a key and all versions of the text including the primary English version located elsewhere in a data file, that sounds good for the "glossary of well known terms you want to use across the site" scenario, but the vast majority of strings we use are translated per instance, since their meaning and context varies. Trying to share strings to save on translation costs would just slow down development too much. Maybe smaller projects have different priorities of course though.
So I'd push for the English text (or whatever the primary language is) and the description located in the Svelte component itself. That way it works immediately and works even if you lose your translation data, and you don't have the Svelte component author having to hand fill-in a data file for one language while all the other languages come from an automated process.
 Rich-Harris
commented
3 years ago
Rich-Harris
commented
3 years ago Thanks @johnnysprinkles — I haven't experienced this sort of translation workflow so that's useful.
I'm not wholly convinced that including the primary language in the component alongside a description is ideal though:
<ui:msg description="Greeting">Hello, world</ui:msg> is one thing, but if you want to be able to refer to translations in JavaScript as well, you have to have some way of associating descriptions with variables, and the whole thing has to be amenable to static analysis. This would likely involve non-trivial changes to Svelte itself, even if we could come up with a design that made sense<h1>{t.greeting}</h1> is nicer than <h1><ui:msg description="Greeting">Hello, world</ui:msg></h1>. The latter adds a lot of distracting visual noise that I probably don't want when I'm building a UIAn example that I love to use is the term “Get started.” We use that in our products in a lot of places and, in American English, it’s pretty standard. It’s so understandable that people don’t even think of the fact that it can be used in three or four ways. It could be a call to action on a button. Like, “Get started. Click here.” It could be the title of the page that’s showing how you get started. It can be the name of a file: a Get Started guide PDF. All of those instances need to be translated differently in most other languages.
So that leaves the question 'how do we associate descriptions with keys'? I think that's actually quite straightforward, we just have a descriptions.json or whatever in the same places as the translations themselves:
// en.json
{
"brand": {
"name": "SvelteKit",
"tagline": "The fastest way to build Svelte apps",
"description": "SvelteKit is the official Svelte application framework"
},
"greeting": "Welcome!",
"clicked_n_times": "{n, plural,=0 {Click the button} =1 {Clicked once} other {Clicked {n} times}}"
}// description.json
{
"brand": {
"name": "The name of the project",
"tagline": "The tagline that appears below the logo on the home page",
"description": "A description of SvelteKit that appears in search engine results"
},
"greeting": "A message enthusiastically welcoming the user",
"clicked_n_times": "The number of times the user has clicked a button"
}I'm envisaging that we'd have some way to convert between this format and those used by common translation workflows (.po as mentioned above, etc), so that the descriptions are colocated with the primary language as far as translators are concerned. These descriptions would also become part of the type signature:
declare module '$app/i18n' {
import { Readable } from 'svelte/store';
/**
* A dictionary of translations generated from translations/*.json
*/
export const t: Readable<{
brand: {
/** The name of the project */
name: 'SvelteKit';
/** The tagline that appears below the logo on the home page */
tagline: 'The fastest way to build Svelte apps';
/** A description of SvelteKit that appears in search engine results */
description: 'SvelteKit is the official Svelte application framework'
};
/** A message enthusiastically welcoming the user */
greeting: 'Hello!',
/** The number of times the user has clicked a button */
clicked_n_times: (n: number) => string;
}>;
}Hi I have a question, how long it will take to implement it in this way? There are pros and cons of doing something right? What are the pros of doing it this way ".pot, .po, .mo"?
.pot way.Is it possible to know about those tools and features status? like a daily blog or something? Maybe a Discord channel that just the maintainers can send voices, details, pulls, and etc? By the way, I created a fake account to join the Discord server😂 (feels like admitting the crimes to the cops😄). Thanks again for banning me👏, "You are the best" MR. pngwn#8431(if I'm not mistaken)😀
Rich-Harris
commented
3 years ago @babakfp you're describing https://github.com/sveltejs/kit/issues/1274#issuecomment-838810969, which is what I just responded to, except that you don't suggest a way to provide descriptions. Putting the primary language inline comes with a number of problems, and in terms of implementation/complexity, this...
It's going to be implemented sooner and easier
...couldn't be more wrong, I'm afraid. To reiterate, the expectation isn't that translators would edit JSON files directly. The goal would be to support existing translation workflows.
Rich-Harris
commented
3 years ago Is it possible to know about those tools and features status?
Yep, by subscribing to this issue tracker
johnnysprinkles
commented
3 years ago I mean this is just one perspective on it. We do optimize for frictionless development and happily translate the English string multiple times. We've probably translated 'Name' a thousand times, e.g.
['Name', 'Name of a virtual machine in the table column header']
['Name', 'Name of a virtual machine in the text input placeholder']
['Name', 'Name of a database table in the table column header']
['Name', 'Name of a database table in the text input placeholder']Now that I look at it, the context probably isn't necessary, a specific type of "Name" should translate the same way whether it's in a table column header or a text input. But types of names certainly could translate differently, like the name of a person being different that the name of an entity. Sounds like we agree about that and a separate description.json sounds good to me.
One nice thing about having the English text and description hashed together as the key is that it's inherently reactive. Those are the two inputs that affect what the translation is, and if either change it needs to be retranslated (generally speaking).
I'm realizing now I might have muddled the issue with two totally different examples. In the GWT
What we have with Closure Compiler may be more relevant. It's a constant that starts with MSG_ so we can sniff out which strings you're actually using at build time. I'm thinking about how hard it would be to graft this onto SvelteKit. We'd add a compilation pass either before or after Vite/Rollup. Of course I'd rather use native SvelteKit i18n if that turns out to work for us!
In a large enough app this module could get very large. We could theoretically use static analysis to determine which translations are used by which routes, and only load the translations needed for the current route, but I don't think that's necessary as a starting point.
I think it's pretty critical to have this split up per route from day 1, for those who are obsessed with the fastest possible initial page load and hydration.
So I guess I'd just say that Rich's proposal sounds good to me if we can make per-route translation string modules and if referencing a key with no primary language translation present fails the build right away.
johnnysprinkles
commented
3 years ago Of course, the tooling that extracts the untranslated strings could pass along a key it derives however it wants. It could use the developer created name, or it could hash together the primary language/description pair. Maybe it could be a preference which way to go, but if set to the former there would need to be some way to manually invalidate, maybe a third parallel json file full of booleans.
Also regarding forcing developers to be copywriters, mostly what I've seen is a simple two stage pipeline where the initial version has the final English text, typically read off a mockup. I could certainly see also offering the option of a three stage pipeline where the initial text is blank or has placeholder text, then the copywriter fills in the English, then it goes off to the translators. Maybe that would be a feature that comes later.
johnnysprinkles
commented
3 years ago Oh what about this -- two layers. A "stable" layer which is the hand written json you mentioned, and a fallback layer that's english/description hashcode based. So you'd start with your svelte file
{$t.click}And add the stable English version:
// en.json
{
click: 'Click',
}
// en.description.json
{
click: 'Call to action, to do a mouse click'
}But there's also an "unstable" data file that's keyed by hash:
// en.hashed.json
{}To find $t.click in French, you'd first look in fr.json, then if not found there hash the English version with the description and use that key to look in fr.hashed.json. If not there it's untranslated and will be included in the next extract.
Once you get the French version back, you'd normally fill in fr.hashed.json, but you'd also have to option to put it directly in the more stable fr.json if you never want to worry about having to retranslate it.
This would cover the case of people who don't use tooling at all, maybe they have a Russian friend and a Japanese friend and just say "hey can you translate this handful of strings for me" and manually plug those into the xx.json files. But for the heavyweight production setups, the incoming translations would only ever go in an xx.hashed.json file. Your file would end up looking like:
// fr.hashed.json
{
123: 'cliquer',
}Later if you change the English to click: 'Click here' that would hash to 456 and you'd end up with:
// fr.hash.json
{
123: 'cliquer', // obsolete
456: 'cliquez ici', // or whatever, I don't speak French
}Hello @Rich-Harris, I am working on a rollup plugin that works on .svelte files (including typescript) but also on .ts or .js files. It should even work on .jsx files, but I did not test it. The advantage is, that this solution is not restricted to svelte/kit and that there is much more flexibility regarding different requirements. I want to share some thoughts/replies on your points:
gettext-extractor-svelte library. The whole translation functionality depends only on one javascript function, which can be used in all files anywhere The only point is to use the plugin before any other plugin if file references including line numbers in the extracted messages are needed. For special use cases, more than one translation function can be provided.t (and $t if a store should be used).key completion in the editor. But on the other side organizing and maintaining a hierarchy of keys can get also quite complicated. Therefore I prefer the actual text, just set it and forget it.import { t } from './t/translations';
// If the same message string is used multiple times, than it will be extracted into one msgid
t('Message String');
// add context to prevent messages with the same messagestring to be treated as same, if the same message
// string with the same context is used multiple times, than it will be extracted into one msgid/msgctxt
t('Message String', 'Message Context');
// add comment for the translator
t('Message String', 'Message Context', 'Message Comment');
// unneeded parts can be ommited
t('Message String 2', null, 'Message Comment');
// add messageformat string and supply properties for the string
t(
'Message {FOO}',
'Message Context',
{comment: 'Message Comment', props: {FOO: 'Type of foo'}},
{FOO: getFoo()}
);
// add language for live translations
t('Message String', 'Message Context', 'Message Comment 2', null, getLanguage());The translation function can be defined in a flexible way. If needed the position of all arguments can be changed however it fits the translation function. If gettext should be used instead of messageformat we add an argument for textPlural to the translation function and set the useGettext option.
Let's say we have defined a translation function as:
import MessageFormat from '@messageformat/core';
const mf = new MessageFormat('en');
export function t(
text: string | null,
id?: string | null,
comment?: {props?: Record<string,string>, comment: string, path: string} | string | null,
props?: Record<string, any>
): string {
const msg = mf.compile(text);
return msg(props);
}Than the function calls will be replaced with:
'Message String';
'Message String';
'Message String';
'Message String';
'Message String 2';
((d) => 'Message ' + d.FOO)({FOO: getFoo()});
'Message String';In this case, the translation function would completely disappear.
Additional we would get the following .pot file (omitting the header):
#: src/App.js:3
msgid "Message String"
#. Message Comment
#. Message Comment 2
#: src/App.js:6, src/App.js:8, src/App.js:19
msgctxt "Message Context"
msgid "Message String"
#. Message Comment
#: src/App.js:10
msgid "Message String 2"
#. Message Comment
#. {FOO}: Type of foo
#: src/App.js:12
msgctxt "Message Context"
msgid "Message {FOO}"If somebody does not need .pot files, I can also emit simple JSON objects connecting the function properties to the message strings. But then we can not use the context and comment properties. If there is a need for putting comments into a separate JSON file, this functionality can be easily added.
A more complicated example
// in App.svelte
<script lang="ts">
import { t } from './t/translations';
export let res: number;
</script>
// later
<p>
{t(
'{RES, plural, =0 {No foo} one {One foo} other {Some foo}}',
'Foo Context',
{comment: 'Foo Comment', props: {RES: 'Foo count'}},
{RES: res}
)}
</p>// in Page.svelte
<script lang="ts">
import { t } from './t/translations';
export let d: Date;
export let res: number;
</script>
// later
<p>
{t(
'{ D, date }',
'Date Context',
'Date Comment',
{D: d}
)}
</p>
<p>
{t(
'{RES, plural, =0 {No bar} one {One bar} other {Some bar}}',
'Bar Context',
{comment: 'Bar Comment', props: {RES: 'Bar count'}},
{RES: res}
)}
</p>This would extract the following .pot file:
#. Foo Comment
#. {RES}: Foo count
#: src/App.js:8
msgctxt "Foo Context"
msgid "{RES, plural, =0 {No foo} one {One foo} other {Some foo}}"
#. Date Comment
#: src/Page.js:9
msgctxt "Date Context"
msgid "{ D, date }"
#. Bar Comment
#. {RES}: Bar count
#: src/Page.js:17
msgctxt "Bar Context"
msgid "{RES, plural, =0 {No bar} one {One bar} other {Some bar}}"If we assume that we have translation files for English and German and the translations for german in the file App.svelte are missing and falling back to English we get the following files:
// in App.svelte (engish and german version)
<script lang="ts">
import { t } from './t/t2';
export let res: number;
</script>
// later
<p>
{((d) => t.plural(d.RES, 0, t.en , { "0": "No foo", one: "One foo", other: "Some foo" }))({RES: res})}
</p>// in Page.svelte english version
<script lang="ts">
import { t } from './t/t0';
export let d: Date;
export let res: number;
</script>
// later
<p>
{((d) => t.date(d.D, "en"))({D: d})}
</p>
<p>
{((d) => t.plural(d.RES, 0, t.en , { "0": "No bar", one: "One bar", other: "Some bar" }))({RES: res})}
</p>// in Page.svelte german version
<script lang="ts">
import { t } from './t/t1';
export let d: Date;
export let res: number;
</script>
// later
<p>
{((d) => t.date(d.D, "de"))({D: d})}
</p>
<p>
{(
(d) => t.plural(d.RES, 0, t.de , { "0": "Kein bar", one: "Ein bar", other: "Ein paar bar" })
)({RES: res})}
</p>// ./t/t0.js
import {t as __0} from './t2.js';
import { date } from "@messageformat/runtime/lib/formatters";
export const t = {
...__0,
date
};// ./t/t1.js
import { plural } from "@messageformat/runtime";
import { de } from "@messageformat/runtime/lib/cardinals";
import { date } from "@messageformat/runtime/lib/formatters";
export const t = {
plural,
de,
date
};// ./t/t2.js
import { plural } from "@messageformat/runtime";
import { en } from "@messageformat/runtime/lib/cardinals";
export const t = {
plural,
en
};I have almost finished my plugin up to this point. Some refactoring has to be done and some additional tests written. I think that I will publish the first beta version at the end of this week. I am also thinking to offer a very different approach where all translation strings per file will be in a store. This would give the possibility for 'live' translations. To put pre-compiled translation functions into JSON files, I have first to look into how to serialize them. This would give the possibility to live-load additional translation files on demand.
The workflow would be to leave everything in place when developing the application. Maybe there could be some functionality to load already translated strings into the app and/or provide some fake text per language. Then there is the extraction phase where all strings are extracted into .pot files and merged with the .po files from previous translations. When we have all translations back we build in the third step the actual translation functions and integrate them into our files. If necessary we can also define fallback languages to each language when some translation strings are missing.
The only missing link is now how to get the actual language at build time. For this, I would need svelte kits multi-language routing functionality.
johnnysprinkles
commented
3 years ago I can say from experience it is nice for the development flow to be able to put your string data right inline. Rich thinks it adds visual noise but I tend to think it orients the code author, and is less cryptic.
I replace all message strings with the translated and pre-compiled version directly in the source file when building
Is this talking about both the pre-rendered HTML (as from utils/prerender) and the JS artifacts?
johnnysprinkles
commented
3 years ago Actually never mind, prerender happens after JS building so of course it would apply the translations there.
johnnysprinkles
commented
3 years ago We have a list of features, I wonder if something like this would be helpful https://docs.google.com/spreadsheets/d/1yN03V04RI8fBE9ppDkEf2-d9V3f4fHFwekteRNiJskU/edit#gid=0 If @floratmin is suggesting a kind of macro replacement, like t('greeting') swapped out with a string literal 'Hello' at build time, that would be incompatible with client-side language swapping.
 filsanet
commented
3 years ago
filsanet
commented
3 years ago Google and Amazon I know have "translation consoles" that manage it for you. So say weekly you pull the strings and send them off, then they come back a week or more later, you check that data in and it's available after your next deployment.
Just FYI, I encountered a "translation console" recently via the Directus project - they use a system called Crowd-In. Directus is using vue-i18n and .yaml files for translations, but Crowd-In supports many formats.
 dominikg
commented
3 years ago
dominikg
commented
3 years ago I think using separate translation keys instead of the primary language string is both more stable and flexible.
It allows for namespacing and translation of generated keys, and should make it easier to implement tooling around extraction / missing translations checks etc.
I also think providing context for translators should not be done in the template part of a .svelte component as that would be very verbose and detrimental to quickly understanding a components structure.
Svelte is in a kind of unique position here as with svelte-preprocess, the compiler, language-tools and sveltekit we have all the tools at hand to build a system that allows to use a wide array of possible input formats, ( eg. an extra <translations></translations> element in .svelte components consumed by a markup preprocessor, trees imported from json or yaml, .po,... to different output formats based on the applications needs (static precompiled, static + language-store bundle for switching, fully clientside dynamic/runtime) and provide developers and translators the information to efficiently do their jobs.
floratmin
commented
3 years ago @johnnysprinkles I think that in many use cases the language is switched mostly only one time. This holds also for my use case. So I developed this part first. But I am thinking to implement two other use cases. The first would be to have per page a store with all translation strings of all languages so that switching to any other language is immediate. The second would be to serialize the functions and fetch them on demand. This would give the possibility to store fetched translation strings. For these two solutions, you have to keep in mind, that a lot of language-specific cardinals could be included in the package.
Page.svelte from the second example in my previous comment could e.g. be like// in Page.svelte (only one version)
<script lang="ts">
import { t } from './t/t2';
export let d: Date;
export let res: number;
</script>
// later
<p>
{$t.a7o({D: d})}
</p>
<p>
{$t.a7n({RES: res})}
</p>
// t2.js
import { writable, derived } from 'svelte/store';
import { plural } from "@messageformat/runtime";
import { date } from "@messageformat/runtime/lib/formatters";
import { en, de } from "@messageformat/runtime/lib/cardinals";
export const language = writable('en'); // set initial language
const fallbacks = {
de: 'en'
};
// we can merge more functions from shared modules here
const _0 = {
plural,
date,
de,
en,
};
// we could also import shared message functions and merge them here
const languageStrings = {
'en': {
a7n: m =>
(
(d) => _0.plural(d.RES, 0, _0.en , { "0": "No bar", one: "One bar", other: "Some bar" })
)(m),
a7o: m => ((d) => _0.date(d.D, "en"))(m)
},
'de': {
a7n: m =>
(
(d) => _0.plural(d.RES, 0, _0.de , { "0": "Kein bar", one: "Ein bar", other: "Ein paar bar" })
)(m),
a7o: m => ((d) => _0.date(d.D, "de"))(m)
}
};
// we could also implement some fetch functionality and deserialization here
// some fallback for missing strings can also be implemented here
export const t = derived(language, ($a, set) => {
set(languageStrings[$a] ? languageStrings[$a] : languageStrings[fallbacks[$a]])
});
Some thoughts regarding your list of features:
#| msgid previous-untranslated-string and #| msgctxt previous-context which is not well supported in most implementations and editors. This could allow a fallback to the previous version and could also provide previous translations of the message string for translators. I wanted to include this functionality, but gettext-extractor depends on pofile and there this feature is not implemented. A problem with this approach is that we have to mark a message string explicit to be a new version of some older message string. This puts more work on the programmer. Also it makes the code more verbose. Some of the connections to a previous version could get lost if strings are changed more than one time per translation cycle.fuzzy entry in gettext which matches strings with little differences, but I did not look into it.floratmin
commented
3 years ago @dominikg I think using the primary language string (and some context if necessary) to be the better option. When a project is fresh and small, creating a hierarchy of keys is easy. But after some refactorings or some new developers on the project, the maintenance of this hierarchy gets quickly more and more hard. If I use only the string it is more like set it and forget it. If I have to differentiate, I simply add some context. See also this comment and the entire discussion on StackOverflow. I think also that retranslating one string is often cheaper than creating and maintaining a system for avoiding retranslation.
I see also that providing the context/comments directly in the source code not to be a big problem. Most strings in applications are trivial and don't need a lot of context or comments. And keeping context/comments separated in another part of the file makes the maintenance harder.
 mabujaber
commented
3 years ago
mabujaber
commented
3 years ago Do you put Right to left in consideration or you consider it as a different feature?
floratmin
commented
3 years ago @mabujaber Right to left can be almost completely solved with CSS. You have only to set dir on the body element to rtl or ltr with svelte to match the direction of the language. Then you can use body[dir="rtl"] and body[dir="ltr"] as selectors. If you use tailwind.css, have a look at tailwindcss-rtl.
johnnysprinkles
commented
3 years ago When a project is fresh and small, creating a hierarchy of keys is easy.
I have to agree with @floratmin on this one. It reminds me of CSS, when we were all young and doing small projects, we had a global CSS file that was well organized and fully factored and you'd put your abstractions in there, but we soon learned that nobody knows what your abstractions are and vice versa and nobody knows what's being used and the CSS file just grows monotonically. Then React and CSS-in-JS came along and it was way, way better. Instead of <div class="status-message> your abstraction is at the React component level with<StatusMessage>.
Translations in code in .svelte works for me -- or -- more in line with Rich's original idea, what about translations in data but that data can be in the .svelte component as well, like:
// Menu.svelte
<ul>
<li><a href="/home">{$t.home}</a></li>
<li><a href="/about">{$t.about}</a></li>
</ul>
<svelte:translations>
{
home: 'Home',
about: 'About',
}
</svelte>Where these home/about names are scoped so you can have other Svelte components with their own separate "home" and "name" i18n values.
Maybe you'd have a different $t function for global translations that are used site-wide.
I'm also thinking more and more that this data should be an object instead of simple string. It comes down to how many pieces of data per string. When it was just "English text" then yeah, string is fine. When we added "description", sure having a parallel structure is ok. But any more things and it seems like an object is the way to go. I've often seen translation systems that have two description fields, like a "description" and a "meaning" or a "context" or a "comment." This does seem like it's overgeneralizing things, but then also if we had "fallback ID", it's starting to seem like for extensibility we'd want these JSON structures to be a level deeper than just a string. And also I really hate duck typing, but maybe it would be worth it for conciseness to have string|object.
So might be more like this for the non-duck typing case:
<svelte:translations>
{
home: {
primary: 'Home',
description: 'Home as the navigational location of the website',
},
about: {
primary: 'About',
},
}
</svelte>Edit: I guess this would make the namespaced nesting of strings a problem. Needs a little more thought, because I really like the idea of namespacing to arbitrary depth.
johnnysprinkles
commented
3 years ago Oh, I overlooked this Rich Harris bullet point:
It forces you to use descriptions even if they're unnecessary for your workflow, because otherwise two strings that are the same in one language but context-dependent in another rely on the description for disambiguation:
Maybe the key comes from a 3-part hash including the English text, description if present, and namespace/ID.
dominikg
commented
3 years ago I still don't get why you would want to put all this metadata and complexity deep down into the template code. That code is read/maintained by software developers and thinking in variables and what their values are going to be at runtime is embedded into our dna and tools to look up the values exist.
I don't like <div>{t('A very long description that gets changed on a bi-weekly basis because someone cant make up their mind about it')}</div> and a commit histories cluttered with "updated translation again".
i'm perfectly fine with <div>{t('description')}</div>
When the translation keys are strings, you can still use the primary language as keys if you prefer to read it that way, this is even suggested in the stackoverflow thread @floratmin linked earlier.
In the end all languages should be treated equal, and having the primary language values defined inline and other languages outside is not equal.
Apart from the key format i'd like to suggest 2 more things.
1) interpolation values as keyd objects t('USER_GREETING',{user}), maybe even with a global store of interpolation values to pick from (eg. user.name, user.email) make it easier to read translation values eg {USER_GREETING: 'Hello, {user.name}'}
2) recursive translations: eg t('FOO') === Hello, World! with {FOO:'Hello, {BAR}', BAR: 'World!'}
johnnysprinkles
commented
3 years ago @dominikg Let me just ask, do you consider this to be a problem for the non-translation use case as well? Like does this bother you:
<div>A very long description that gets changed on a bi-weekly basis because someone cant make up their mind about it</div>It doesn't bother me.
dominikg
commented
3 years ago It would bother me if frequent text changes would start to bog down the development workflow. I may even be tempted to suggest using a translation framework with just the primary language as input just to get the text changes separated from the code changes. But this issue here is about how to build such a framework for sveltekit and i feel like continuing the discussion here would not add more value to that. Feel free to hit me up on discord https://svelte.dev/chat
johnnysprinkles
commented
3 years ago Had a nice chat with @dominikg on Discord. I was telling him about how my old co-worker at Google who's fluent in German was reviewing the translations we get from the contractors, and that some were definitely not good. They had "over translated" whereas in typical usage many of the terms would just be left in English. Actually come to think of it, he's on Github, hey @mprobst.
The point is that, even if you have well written descriptions (which you generally won't), it's hard to have the courage to just not translate a string if that's what you're getting paid to do. I imagine it's a lot easier to do so if you have more context, like a screenshot of the page. And actually just in general, page screenshots seem super helpful for having more confidence in your translations.
If translations are a kind of multi-stage pipeline (maybe actually up to 4 stages: creation, copywriter, translation service which is generally machine-based, human review), I can imagine screenshots potentially being useful at every stage. And, pretty easy to provide using the same mechanism as pre-rendering, like we do with the kit.prerender.pages array.
Might look something like:
{
greeting: {
primary: 'Hello',
screenshotUrl: '/welcome',
},
item_page_title: {
primary: 'Details about your item',
screenshotUrl: '/items/1', // an item ID that will exist in this environment
},
}This might just be a chance to go above and beyond on this. It is kind of heading toward "integration test" territory though, maybe not something that belongs right in SvelteKit. Just some thoughts.
floratmin
commented
3 years ago @dominikg if the change is only in the primary language, then you would not change it in code, but in the .po file for the primary language. If you like to use some keys, you are free to use these keys. But I think even thinking up these keys is extra work for the developer. The only advantage of using a strong hierarchy of keys is to have key completion, but I doubt that the advantages outweigh the disadvantages. @johnnysprinkles I was thinking that it could be easier to generate links for each message string as a comment and to set up a live system for the translators. Maybe even some system that would automatically highlight the message string?
 UltraCakeBakery
commented
3 years ago
UltraCakeBakery
commented
3 years ago What about translated route aliases? This might be a nice way of implementing that:
<script context="module">
export const aliases = [
'/blog/history/[page]',
{
url: '/blog/archief/[page]',
locale: 'nl-NL'
},
{
url: '/blog/archivo/[page]',
locale: 'es-ES'
}
]
</script>
<script>
import { t, locale } from '$app/i18n'
import { page } from '$app/stores'
</script>
<a href={$page.aliases.find( alias => alias.locale === locale )}>{ $t.links.example_one.label}</a>
<a href={$page.aliasesLocalized[locale]}>{ $t.links.example_two.label}</a>(for future reference: #269 #1459)
 dkzlv
commented
3 years ago
dkzlv
commented
3 years ago To me svelte-i18n is perfect. Kudos to @kaisermann, awesome work.
There's one thing that makes the whole experience not ideal, and it is nested tags. It's super typical to have tags inside strings, like this string from this very page:
Remember, contributions to this repository should follow our <a href='...'>GitHub Community Guidelines</a>.And right now it is super unsafe to recreate in Svelte. You either need to keep the tags in the translation files or interpolate them as variables.
<p>
{@html $_('example', {
values: {
linkO: '<a href="..." rel="..." _target="...">',
linkC: '</a>'
},
})}
</p>and use it like this in the strings:
{
"example": "Visit this {linkO}page{linkC}"
}It is very unsafe because of @html, and can break the whole app if a translator forgets to add closing tag variable. And generally the experience is somewhat awkward. It would be super interesting if we had any solution to this embedded into the framework, as it is not something that can be dealt with in the userland.
Would also be cool if we found a way to split JSON-files and only load the portion that is needed for current page. Currently svelte-i18n will just load all the strings for the language, which can be a lot in big apps.
 nosovk
commented
3 years ago
nosovk
commented
3 years ago currently @cibernox created great library - https://github.com/cibernox/svelte-intl-precompile It intended to work more like i18n in Angular (where it totally compile time, with different localized bundles). @Rich-Harris pointed before that Svelte is about compiling, and approach in svelte-intl-precompile allows to create all ICU calculation during build.
 cibernox
commented
3 years ago
cibernox
commented
3 years ago @nosovk Thanks for mentioning it.
Yes, I think that any official attempt to bake in i18n in svelte/sveltekit in an opinionated way must, at least optionally, take an approach at least similar to the one I took in https://github.com/cibernox/svelte-intl-precompile.
I have a lighting talk last Svelte Summit, but the tl;dr; is that much like svelte being a compiler results in minimal bundles and fantastic performance, the same has proven true for precompiling the translations at build time. I have some real world apps that add in which adding internationalization barely added 2kb to the final bundle and perform much faster specially for SSR and initial render.
Some other upsides of this approach:
gettext if that's their jam and the app code shouldn't be any different.Some downsides of this approach:
My library just shamelessly copied the public API (and some of the code) of svelte-i18n because it's very well thought out and IMO the best to copy from. @kaisermann did indeed a fantastic job there.
Having a tighter integration with sveltekit could open the door to even more optimizations. The first one that comes to mind is that, right now all the translations of the app are a single bundle, and all the nice code-splitting of sveltekit cannot be leveraged for translations. With some tighter integration we could load only the translations and helpers (like formatters for dates/numbers) that the route being loaded needs, and nothing more.
Another nice feature would be translated URLs. @pz-mxu has been working on that for sveltekit and it would be A-MA-ZING.
Also some things that right now are possible with the library but a bit cumbersome, like autodetecting the user's locale from the accept-lang HTTP header of the request could be zero-config with a tighter integration in sveltekit.
I am happy to help with my learnings, and I'm pretty confident my employer would be on board to allocate 20% of my week to work on this, as we're more and more invested in svelte every day. Ping me if you want to create some sort of strike team to work on that.
johnnysprinkles
commented
3 years ago @cibernox Have a link or a timestamp for that talk?
cibernox
commented
3 years ago @johnnysprinkles https://www.youtube.com/watch?v=fnr9XWvjJHw&t=10004s
cibernox
commented
3 years ago Some technical checkboxes I think the ideal i18n implementation should check:
svelte-i18n could be a bit better by not requiring to pass translations arguments nested in a values key.Intl api this is not a big deal.johnnysprinkles
commented
3 years ago Thanks for that talk link, great talk!
I agree with all these, although regarding "splitting translations by route" that's a must have for me, and for anyone who's app is fairly broad i.e. has lots of pages.
Today's apps and sites have huge JS bundles. Facebook gives you 10MB on the first page load, Google's Cloud Console gives you 15MB, seems to be par for the course. All while I'm over here making pages for 200kb in Svelte -- and I'm talking about rich complicated pages, with modals and little sub-experiences popping out of the side. Adding another 20k, 50k, 100k to the first load because that's all the strings across your site seems un-Sveltey to me.
cibernox
commented
3 years ago @johnnysprinkles I know, I've created a few >2mb pages myself.
Splitting translations by route is probably not too complicated as long as you don't invoke them dynamically like
<button type="submit">{$t(`save.${model.type})}</button>`But if you don't do things like that it should be possible. Even if you do it might be even be partially possible, but the bundle would have to conservative and include all translations that can possibly match.
 huevoncito
commented
3 years ago
huevoncito
commented
3 years ago There is also a need to internationalize routes. For example, /fr/search doesn't make sense to a francophone. We need /fr/recherche. However the file structure of src > routes > search.svelte is fine. We just need to make sure that /fr/recherche hits that route.
This is achievable on first load by simply reassigning request.path in the handle hook.
const pageMap = new Map();
map.set('/recherche', '/search');
export const handle = async ({request, resolve}) => {
if ( lang === "fr" ) {
request.path = pageMap.get(request.path); //changes path from '/recherche' to '/search'
}
return await.resolve(request);
};But after first load we have a problem. if you navigate away from the page and then use the back button, it will throw a 404 since the server isn't hit again and the client side router only has a file called /search to refer to.
Any ideas for this? It's a major barrier to adoption for me.
nosovk
commented
3 years ago There is also a need to internationalize routes. For example,
/fr/searchdoesn't make sense to a francophone. We need/fr/recherche. However the file structure ofsrc > routes > search.svelteis fine. We just need to make sure that/fr/recherchehits that route.This is achievable on first load by simply reassigning
request.pathin thehandlehook.const pageMap = new Map(); map.set('/recherche', '/search'); export const handle = async ({request, resolve}) => { if ( lang === "fr" ) { request.path = pageMap.get(request.path); //changes path from '/recherche' to '/search' } return await.resolve(request); };But after first load we have a problem. if you navigate away from the page and then use the back button, it will throw a 404 since the server isn't hit again and the client side router only has a file called
/searchto refer to.Any ideas for this? It's a major barrier to adoption for me.
providing different urls for translated content will cause lots of problems that are not trivial (like generating sitemap, providing special store with maps to connected routes etc.). Probably it should be out of scope for kit.
huevoncito
commented
3 years ago There is also a need to internationalize routes. For example,
/fr/searchdoesn't make sense to a francophone. We need/fr/recherche. However the file structure ofsrc > routes > search.svelteis fine. We just need to make sure that/fr/recherchehits that route. This is achievable on first load by simply reassigningrequest.pathin thehandlehook.const pageMap = new Map(); map.set('/recherche', '/search'); export const handle = async ({request, resolve}) => { if ( lang === "fr" ) { request.path = pageMap.get(request.path); //changes path from '/recherche' to '/search' } return await.resolve(request); };But after first load we have a problem. if you navigate away from the page and then use the back button, it will throw a 404 since the server isn't hit again and the client side router only has a file called
/searchto refer to. Any ideas for this? It's a major barrier to adoption for me.providing different urls for translated content will cause lots of problems that are not trivial (like generating sitemap, providing special store with maps to connected routes etc.). Probably it should be out of scope for kit.
@nosovk that's reasonable. However it is a primary use case for internationalizing a site. We could probably run a bash script to create routes in the new language by copying directories at build but that doesn't feel right.
kobejean
commented
3 years ago @huevoncito @nosovk We actually have a PR with a way to implement translated alternative routes in #1130 but it might take a while before it's merged. You can try it out though and provide some feedback.
Is your feature request related to a problem? Please describe. Translations are largely an unsolved problem. There are good libraries out there, like svelte-i18n and svelte-intl-precompile, but because they are not tightly integrated with an app framework, there are drawbacks in existing solutions:
{$_("awesome", { values: { name: "svelte-i18n" } })}) from the svelte-i18n docsWithout getting too far into the weeds of implementation, what follows is a sketch for what I think the developer experience could and should look like for using translations in SvelteKit. It builds upon the aforementioned prior art (using ICU MessageFormat, precompiling translations etc) while leveraging SvelteKit's unique position as an opinionated app framework. It follows the discussion in #553, but doesn't address issues like picking a locale or handling canonical/alternate URLs, which overlap with translations but can be designed and implemented separately to a large extent.
Describe the solution you'd like In the
translationsdirectory, we have a series of[language].jsonfiles with ICU MessageFormat strings:Regional dialects inherit from the base language:
These files are human-editable, but could also be manipulated by tooling. For example, the SvelteKit CLI could provide an editor along the lines of this one or this one out of the box.
SvelteKit watches these files, and populates an
ambient.d.tsfile that lives... somewhere (but is picked up by a default SvelteKit installation) with types based on the actual translations that are present (using the default locale, which could be specified insvelte.config.cjs, for the example strings):As well as generating the types, SvelteKit precompiles the strings into a module, similar to svelte-intl-precompile:
This module is using for server-rendering, and is also loaded by the client runtime to populate the
tstore. (Because it's a store, we can change the language without a full-page reload, if necessary. That might be overkill, but if Next can do it then we should too!)A relatively unique thing about this approach is that we get typing and autocompletion:
This extends to parameters (which I think should be positional), for messages that need them:
Because everything is just JSON files, it's trivial to build tooling that can e.g. identify untranslated phrases for a given language. I don't know what common translation workflows look like, but it would presumably be possible to convert between the file format used here and the output of translation software that uses ICU.
Describe alternatives you've considered
How important is this feature to you? It's time. Though we need to solve the problem of selecting a locale before we can make much of a start on this; will open an issue in due course.