 char0n
commented
3 years ago
char0n
commented
3 years ago No sure if PSI is something that will help us:
An essential feature of PsiBuilder is its handling of whitespace and comments. The types of tokens which are treated as whitespace or comments are defined by the methods getWhitespaceTokens() and getCommentTokens() in the ParserDefinition class. PsiBuilder automatically omits whitespace and comment tokens from the stream of tokens it passes to PsiParser and adjusts the token ranges of AST nodes so that leading and trailing whitespace tokens are not included in the node.

More info here: https://jetbrains.org/intellij/sdk/docs/reference_guide/custom_language_support/implementing_parser_and_psi.html
 CST
CST LST
LST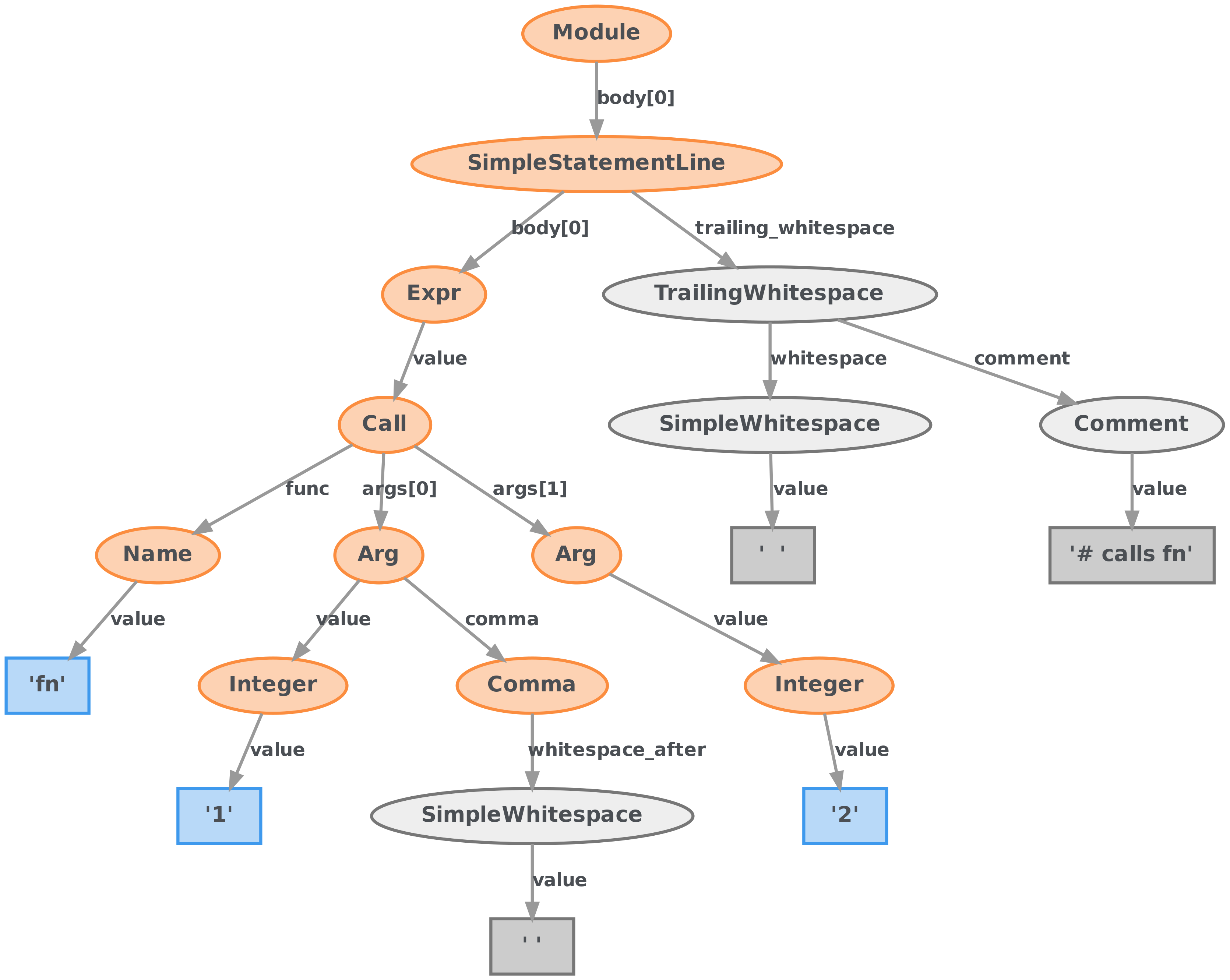
 frantuma
frantuma
Resources:
Our current YAML and JSON ASTs holds non-significant literals like
:or---but not the whitespace literals. Whitespace literals are consumed by the parser while creating CSTs. Whitespaces are not reconstructible even from CSTs because we don't know if the whitespace was represented by two" "(space) or\t(tab) characters.Possible solutions
1.) Store original text fragments from YAML document within ApiDOM
Apart from original YAML text fragments we have to somehow extract whitespaces (as our parser doesn't support exposing whitespaces into CST) from the YAML document and transform them into AST nodes. We need to write an algorithm that folds whitespace AST nodes into appropriate ApiDOM nodes as attributes called
whitespaceandwhitespaceBefore. Complexity of this solution is going to be medium.2.) Store whole original YAML document inside ApiDOM
Every ApiDOM document will be associated with it's original JSON/YAML document and this document will be encoded directly inside ApiDOM as a big string value (no fragmentation). Original JSON/YAML document will be easily stored and retrieved from ApiDOM. Later this solution can be progressively adopted into solution 1.). We would use original document along sourcemap to retrieve whitespace needed for lossless serializaton, and in case of update the same mechanism would be used to update original doc. Complexity of this solution is low.
3.) Store representation information along with all presentation information
Original YAML/JSON document will be decomposed into Lossless Syntax Tree and all presentation information will be folded as metadata or attributes of appropriate ApiDOM nodes. This requires us to implement custom JSON/YAML serializers and the same mechanism for
whitespacesas described in 1.) though. The benefit of this is that we should be theoretically able to reconstruct original document without any loss. Additional advantage will be possibly lower payload size if we assume that ApiDOM encoded presentation information have lesser size than the original document (but that assumption may be wrong). Complexity of this solution is high.There is an additional question of programmatic manipulation of ApiDOM. 1.) and 2.) solutions suffer from similar problem: how to change the original document/fragment if we programmatically manipulate the ApiDOM? Only solution 3.) seems to give us clear answer for that.
Refs https://github.com/swagger-api/oss-planning/issues/231