 Tkrauss
commented
11 years ago
Tkrauss
commented
11 years ago At first, thanks for the image-version of the diagram:). It's almost what we had in mind. Just some remarks:
- Do we really need the nested blocks / conditional blocks? Since a block is just a stmt, it should be enough to have the block class referencing statements and declarations.
- imho, the role of the token should be replaced by a Class "Node" with an attribute Token. In this case, it' s a less coupled system concerning the lexer and parser modules.
- Using this, we need also a Token class. I propose a simple class with a Position ( Line in Code, byte num in Code etc), a enum attribute ( the enum should be like {"num","real","id","add","sub","neg"...}) and a string wich is the string at the pos in the source code ( with reference to the example enum: "23","2.3","MyInt","+","-","-" --- a NonTerminal).
- The AST is a result of the semantic analysis, isn't it? If we want to modularize the parser/semantic analysis, we should also introduce parseTree-classes as a direct mapping from the Grammar Symbols to Classes.
 fub-frank
fub-frank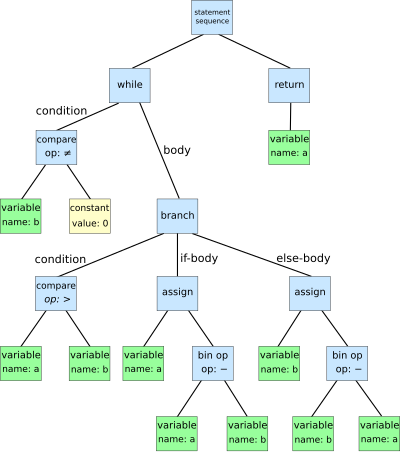
 fb13
fb13 swpcom-heydu
swpcom-heydu flofreud
flofreud EsGeh
EsGeh ghost
ghost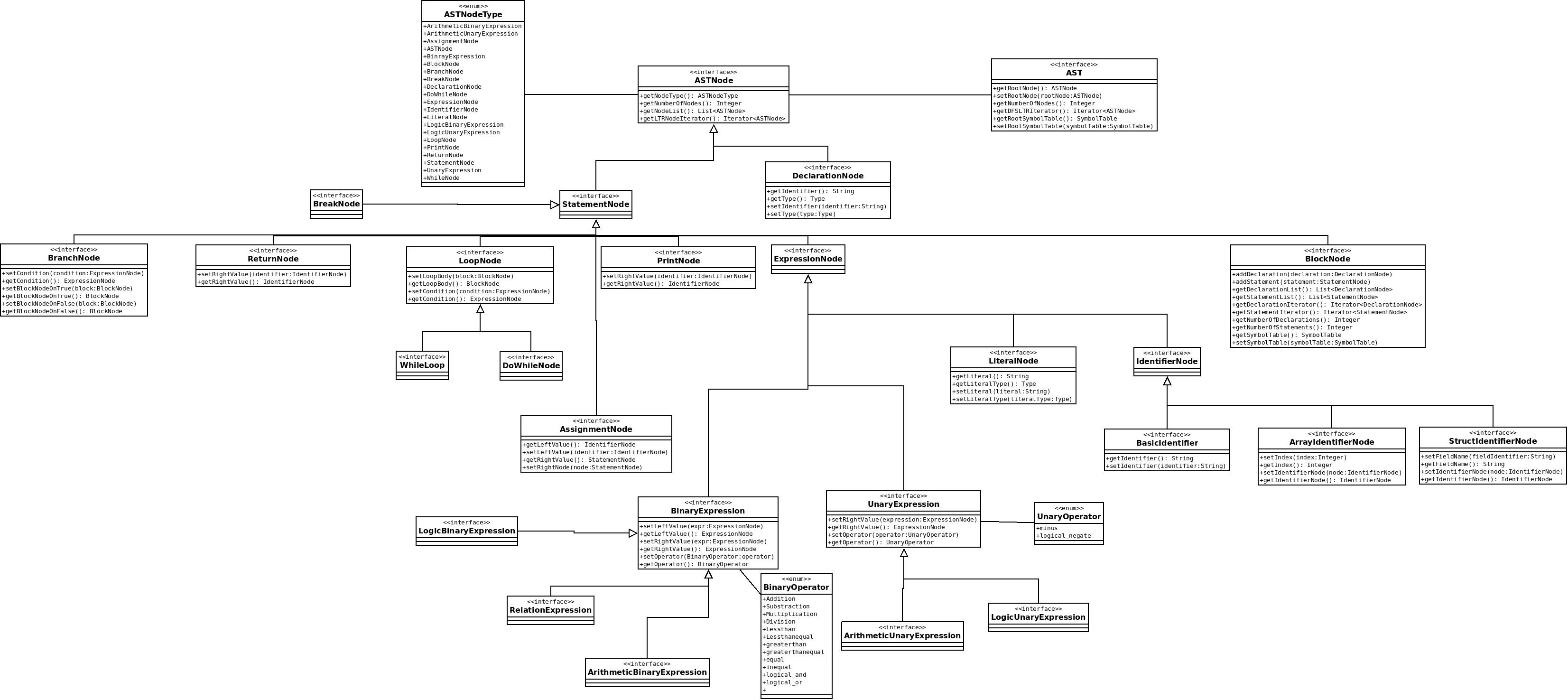

 SWP-Comp-Deathk
SWP-Comp-Deathk EdwarDDay
EdwarDDay
Comments and Discussion for Abstract Syntax Tree See Wiki page: Abstract Syntax Tree