 noobpwnftw
commented
6 years ago
noobpwnftw
commented
6 years ago The generation looks fine so far, as for discussion, I wish to follow the previous memory bandwidth problem of mine, I have observed via "perf top" and these are hot-spots during iteration process.
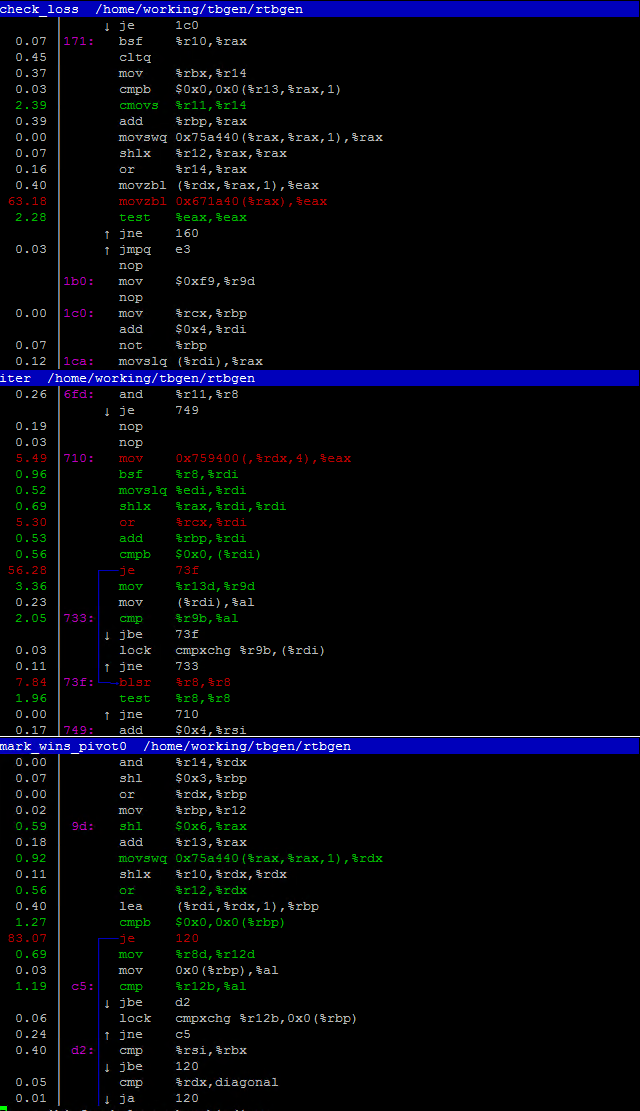
It would no longer cause slowdowns when I use less threads, but this makes me wonder how did people pull this off a few years earlier, which I could assume a magnitude slower interconnect was required to aggregate physical memory from multiple machines in order to hold the intermediate table: even if a space-optimized indexing scheme was used, it still cannot justify the performance loss between UPI vs interconnect.
Any insights?
 syzygy1
syzygy1 Saugstrahler
Saugstrahler
New thread for discussing 7-men generation.