 lbgws2
commented
1 year ago
lbgws2
commented
1 year ago Suggested items for tags need to be generated anywhere, including body text, attributes, and search box
The label suggestions provided in the main text and attributes are divergent, label groups containing any one tag meet the conditions. The results are arranged according to their frequency of occurrence,
The tag suggestions in the search box are filtering based on the input tags in the tag group. Only tag groups containing all input tags meet the criteria, and the results are then aggregated
SELECT
Count (1), tag as count
From Record
Where note_ Id in
(
SELECT
Note_ ID
From Record
Where
Tag in ({query})
)
And tag not in ({query})
Group BY tag
Order BY count (1) desc, tag asc
 tadashi-aikawa
tadashi-aikawa
Personal Knowledge Management Plan
Here are some of my thoughts on personal knowledge management.
Organizational structure of knowledge management
Tree shaped knowledge management
Knowledge management organizational structure, usually people use the concept of "folders" to manage knowledge. The "folder" is a tree structure, typically represented by the Dewey decimal book classification system. However, this structure has the following main drawbacks
Classification is too simple to effectively distinguish information
Classification is too complex, with up to hundreds of classifications difficult to remember
The operation steps are cumbersome, and you need to locate the file location before creating it
Disadvantageous in inspiring and discovering interesting connections between notes
MECE is difficult to implement because the ambiguity of information (knowledge) is not clear in which category to place it in
The first three points may hinder 90% of people, which is also the reason why many people's computer data is disorderly. Of course, efficiency can also be improved through some software tools or operational paradigms. Methods such as automatic search, prompt classification, and automatic jump to corresponding positions are implemented. However, the last point is that classification attribution has strong subjectivity. For multiple classification nodes, if you don't know how to choose, choose one randomly or simply place it in the root directory. There is an open source knowledge management software,
TriliumExplorations have been made in this regard. The method is to create a document on one of the classification nodes, and then create a pointer like directional copy on other possible classification nodes. The edits made can be instantly synchronized to each copy. But there is still a problem of information redundancyLabel management
Express knowledge and information as a block, which may correspond to a folder, file, or paragraph of text. Label this block, which can have multiple labels, and search for them. On this basis, sub labels have also been derived, essentially a tree structure.
Anti chain
In recent years, the popularity of Roam has brought the previously limited academic method of Zettelkasten into the public eye, and has also led to the emergence of double chain notetaking. However, there are also the following limitations
The association diagram established between notes looks very beautiful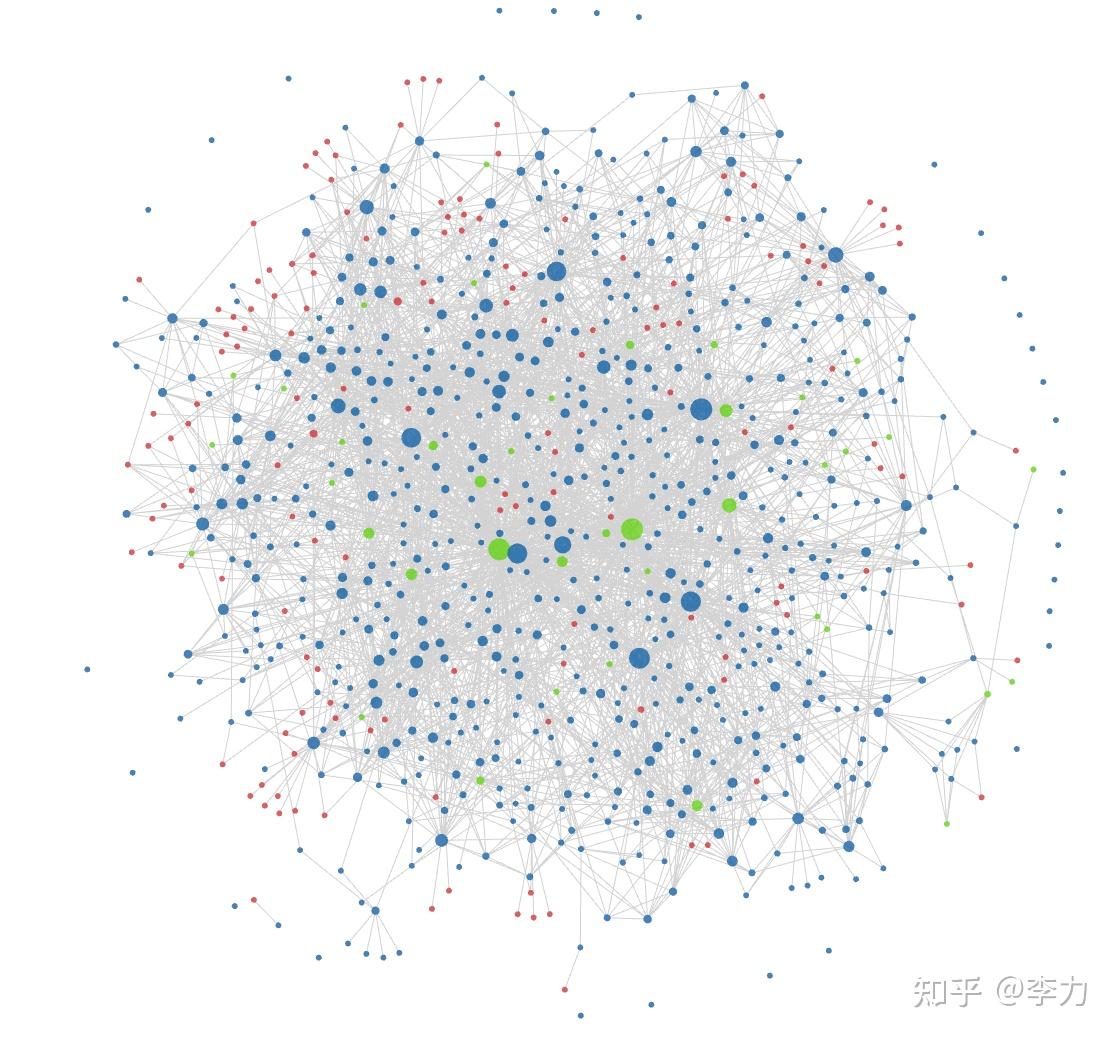
This is essentially a mutual attraction network. If you think about it for a moment, you will find that in order to obtain such a graph, you first need to establish many relationships between the notes. This is a very time-consuming operation, and the semantics that backlinks can express also depend heavily on their level of refinement. This is why some people can promote it to the sky, but it has little effect in the hands of another group of people
The semantic network sounds very tall, but in fact, if not properly planned, the resulting network may look like this.
This mess, if you use visual networks, will quickly become lost in the network structure. If you completely embrace the hierarchical structure and only establish more connections between notes, you will eventually find that the structure has not spontaneously grown, and it is more likely to be chaotic and disorderly
My solution
Label Overview
First of all, after a long period of consideration, I have decided to use tags to organize knowledge. However, the usage of tags is different from existing solutions, and at least there are no mature tools on the market to implement this solution
I solved this problem from the semantic relationship of labels. The existing tools on the market have a tag system, and many tools can search for corresponding matches from the tag library when you enter a tag, but that's all. When you want to input another label, you still need to start from scratch. Why do you want to input multiple labels? It is because there are implicit semantic relationships in multiple labels, pointing to the current semantic block from different dimensions. In a tree structure, the entire structure is supported by a parent-child relationship. For example, an editor under Linux can be expressed as:,
-Linux
|->Editor
|->Vim
|->Emacs
At the same time, the concept of an editor can also serve as a parent node, and its children can contain the following structures
-Editor
|->Linux
|->Windows
|->Mac
|->Android
Simply using a parent-child relationship can lead to such conflicts, which are fundamentally unavoidable. How to solve the problem of using labels? The method is very simple
Tag: # Linux, # Editor, # VimThis already implicitly includes the parent-child relationship. Of course, there may be thousands of relationships between things, which is not a problem for labels at all. Just label multiple labels. The semantic relationship between tags is so important, but existing tools on the market completely ignore this. After you enter a tag, there is no automated prompt for the next possible tag**
Improvement in labeling methods
Define multiple labels within the same row as a label group
Label List Generation
The more tags in the tag group, the stronger the directionality, and even when facing a million level knowledge structure, it can be easily controlled. The method is to establish an index for all label groups and establish a unique identifier for each label group. After entering a label, search for the label group containing the label in the background, and then merge the labels within the eligible label groups, arrange them according to their frequency of occurrence, to generate a list of label suggestions. When there are more than two labels, the label group containing any one label meets the conditions, and then it is arranged according to the label frequency. The list of tag suggestions generated in this way has strong correlation.
Tag search
In past experience, as long as the scale of the knowledge base reaches over a thousand, ordinary keyword searches will result in a lot of search results, making it difficult to quickly find the corresponding items. The current plan includes the following
Need to learn regular grammar, and more importantly, have a certain impression of the search content, otherwise the accuracy of the results will be low
This is search engine technology that improves the accuracy of results through techniques such as indexing and word segmentation. But there is not a good solution for local search. The construction of open-source Elasticsearch is very cumbersome, and the system resource consumption is also very high.
How to use tag groups for high-precision search? After entering a label in the input box, the backend will search for the label group containing this label. When there are more than two labels, only label groups that all contain multiple labels meet the criteria. Then aggregate the eligible label groups and arrange the relevant labels according to frequency
Simply put, label group generation is divergent, while search is filtering and reverse operation
Other advantages
The generation and filtering of tag groups may be tedious to describe in language, but using SQL statements to implement them is very simple. Because the query statement is simple, it can have very efficient execution efficiency, and the hit rate of search results is also very high. The engineering implementation is very simple and easy to deploy in large-scale systems, providing external services.
With the support of a backend system, individual users do not have to struggle to establish their own tag library. With the support of massive data, the label suggestions provided will be very reliable
It can to some extent solve the problem of "one meaning multiple words", and after inputting the "measure" tag, the correlation degree of the "plan" tag is also high
It is possible to flatten the knowledge base and stream input content. Namely, create a new document ->input tags ->input content, without considering where the document should be stored. A more advanced approach includes creating templates for new documents for quick input. Based on the basic framework of year month day, the corresponding folder is automatically established, and documents are automatically included in the corresponding folder.