 nus-se-bot
commented
2 years ago
nus-se-bot
commented
2 years ago Team's Response
This is definitely not a feature flaw, as modern complex library management softwares also used the same design as us. The screenshot below shows an example of National Library Board's Catalogue when I searched for Harry Potter. As you can see below, the UI for NLB Catalogue shows each book copy individually. All the books can have different status, and in the case of our app, the UI should show different borrowers for each of the copy.
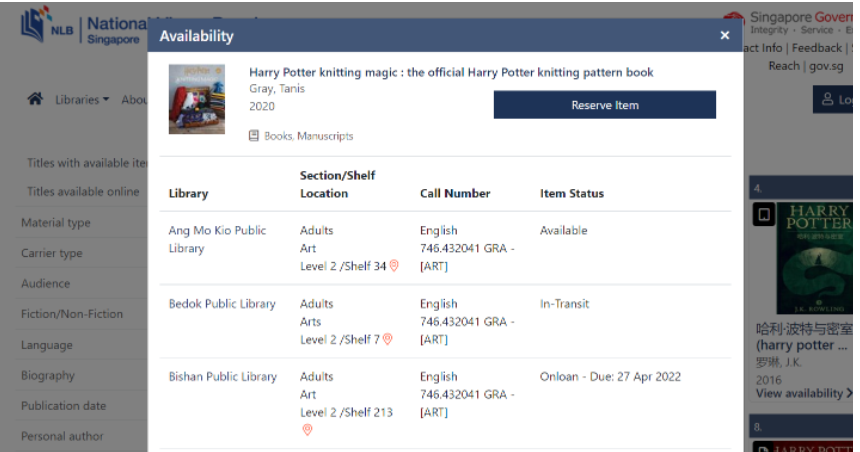
We have considered your suggested approach of including a counter for books with same ISBN (this would mean something like showing only BookCard UI to represent all the copies of the book, with a tag labelling number of copies). By doing so, our app becomes very restrictive (we cannot show all the borrowers and their respective return dates without making the UI even messier and confusing).
You also mentioned that an alternative expectation is to include some unique book identifier aside from ISBN. Our team did in fact used such a unique identifier in our implementation, you can refer to the "Extension of Model component and non-unique nature of BookList" subsection of the "Efforts" section of our DG to see how we tackle this non-unique nature of our books. However, this is an implementation detail and should not be mentioned in the UG.
If the librarian wants to track which book is exactly which, as what you suggested, he/she can always use the index of the book (i.e. copies of "Harry Potter" at different indexes). This is why your previous suggestion to add a counter and combine all book copies into one is not a good idea, because if this is implemented then books cannot be uniquely tracked with indexes (of course you can add another unique identifier field, but that would be a waste of implementation time). Furthermore, tags can also sometimes use to distinguish different copies of books with the same ISBN. In your example of having some books being damaged and others not damaged, the librarian can simple add a "damaged" tag to the damaged books. This is exactly why we design that books with the same isbn must have the same name and authors, but can have different tags. This is made very clear in the User Guide. We even included an example under edit command (page 23-24 of UG) with screenshots to show that, when you edit a book's tag, only that book copy has it's tag edited, but not other copies.
In summary, our team is rejecting this bug because
- The alternatives suggested by the tester does not fit well, and some are even contradictory, and can result in a more confusing user interface.
- Our design is well thought, as shown above, and is consistent with what modern library management softwares do (as shown in the screenshot above).
Items for the Tester to Verify
:question: Issue response
Team chose [response.Rejected]
- [x] I disagree
Reason for disagreement: A fair point is made by the team that "If the librarian wants to track which book is exactly which, as what you suggested, he/she can always use the index of the book (i.e. copies of "Harry Potter" at different indexes). "
This is a circular point, since that is precisely the feature flaw I am reporting.
I mentioned that "So a library with multiple copies of the same book, which is often the case, will require a librarian to track which of each book with the same ISBN is borrowed or returned by first doing a search for all those with that author/title etc., then processing that list."
The team is justifying their design by:
- NLB uses this design. This is disputable.
The screenshot provided shows a different design - a high-level shared header (indicating it is the same book), and then specific instances OF the book. This is intuitive.
- My alternative proposals are ineffective. This is also disputable, and also not the point.
The point I am making is not that my design is better, but that the current implementation requires the user to filter by a certain ISBN/title, and then operate from there, which runs counter to their stated aim of helping librarians complete their tasks quickly.
Summary
In summary, I believe this is a feature flaw, as the current design can be confusing for identical books and requires extra steps for processing, when a high-level expandable view (as with the screenshot from NLB's UI they have provided) would be faster to use and easier to read.
If anything, the screenshot they have provided by NLB is exactly what works best! A high level list that expands into specific instances of copies, and their details. It fits in with the tagging, etc. features they have mentioned in their response, and works with my point here that their current implementation requires an extra, possibly tedious, and possibly hard to read step.
:question: Issue severity
Team chose [severity.Low]
Originally [severity.Medium]
- [x] I disagree
Reason for disagreement: Consider the following screenshot, where there are 13 copies of Harry Potter (which is very normal for a library, for any book!)
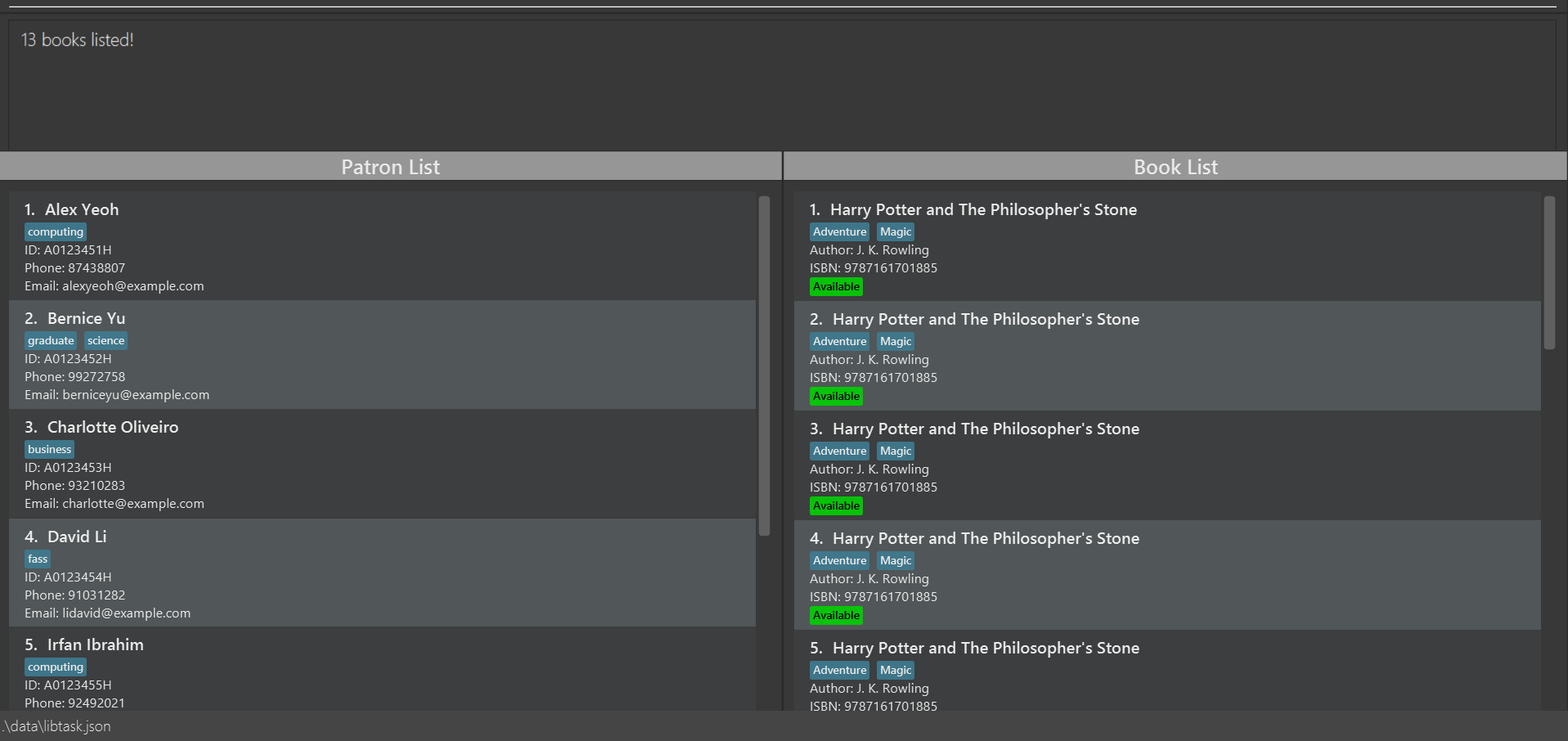
Now to argue that this isn't confusing, or hard to use, or easy to use with indices, would be highly debatable. Considering that any book would have at least 10 copies, to manage it at a high level without some sort of unifying header (as in the NLB UI) or some other implementation, would be highly debatable.
The website defines severity as follows.

To make the claim that this is rare and minorly inconvenient, again, would be debatable. Imagine there were 10 book types, 10 copies of each - that's a 100 rows! Even filtering to a single book type, that's 10 rows to scan manually.
The purpose of the application is indicated as "a desktop application for librarians to manage book loans and requests by patrons.It is specially made to improve the overall efficiency of librarians when processing bookloans and requests, helping them to complete their daily tasks quickly."
However, the addition of identical books is permitted. See 1 & 8.
So a library with multiple copies of the same book, which is often the case, will require a librarian to track which of each book with the same ISBN is borrowed or returned by first doing a search for all those with that author/title etc., then processing that list.
A more intuitive and expected behaviour would be the inclusion of a counter for books with the same ISBN, and who are its borrowers. An alternative expectation would be the inclusion of some unique book identifier aside from ISBN, so that librarians can track which book is exactly which (e.g. application for a case where there are two identical books, but one is water damaged, so we can remove that from the library to be tracked).