dansuh17
commented
2 years ago
dansuh17
commented
2 years ago Hi @thaink , I think this is a question about quantizing the UpSampling2D layer. Could you take a look?
Open touristourist opened 2 years ago
dansuh17
commented
2 years ago Hi @thaink , I think this is a question about quantizing the UpSampling2D layer. Could you take a look?
 thaink
commented
2 years ago
thaink
commented
2 years ago Jaehong is better in QAT and Keras-related things. @Xhark Could you take a look?
 Xhark
commented
2 years ago
Xhark
commented
2 years ago I think there's two possibilities:
Quantize model highly recommended to use nearest because bilinear has some gap between TF and TFLite at this moment. (we quantize output of the layer on TF QAT model, but it moved to input side after convert to TFLite model.)
The model itself can contains some redundant fake-quant. Would you please try to convert that model as float without quantization (to see how many quant-dequant in that model.) and show the TFLite graph result to check it properly quantized?
Thanks!
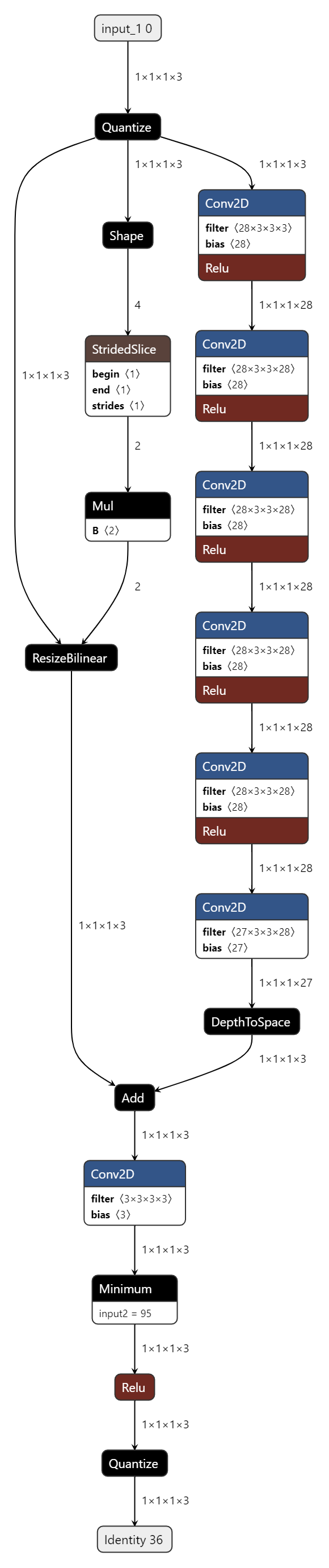
Describe the bug
Hello, I want to do full 8-bit quantization(input, weight all 8-bit) to the network with a bilinear upsampling layer. The fake QAT result in validation set is closed to FP32 result, but when I converted the QAT model to full 8-bit tflite model, the result in validation set decreased significantly, almost no accuracy. So I wonder whether I made a mistake or tflite doesn't support int8 bilinear upsampling correctly.
System information
TensorFlow version (installed from source or binary): 2.5.0
TensorFlow Model Optimization version (installed from source or binary): 0.7.2
Python version: 3.7.13
Describe the current behavior
I aim to do 8-bit quantization to the network below, which has a bilinear upsample branch
I had done FP32 training before, then I loaded FP32 checkpoint and did Quantization-aware training like below
the QAT model was correct, and the performance in validation set was closed to FP32's. Then I converted QAT model to tflite
I loaded tflite model and evaluated as below, but the performance decrease significantly.
Describe the expected behavior I thought the wrong behavior was due to blinear upsampling layer, because when I removed upsample layer(just plain net without skip connection), or replaced upsample skip connection with a conv3x3 skip, I could get the right int8 tflite performance closed to the QAT performance. So I want to know how to quantize bilinear upsampling layer correctly?
other info The tflite model is below