srjoglekar246
commented
3 years ago
srjoglekar246
commented
3 years ago Its mainly the TFLite section towards the end, instead of fine-tuning a model you can just use the SSD MobileNet downloaded from model zoo
Open SukyoungCho opened 3 years ago
srjoglekar246
commented
3 years ago Its mainly the TFLite section towards the end, instead of fine-tuning a model you can just use the SSD MobileNet downloaded from model zoo
 CaptainPineapple
commented
3 years ago
CaptainPineapple
commented
3 years ago okay well that is intresting and confusing (at least to me)
the workflow you provided works as intended (as far as i can tell) and i got to a .tflite file with ~10KB.
Btw the link in your workflow description to the zoo models is broken. The url misses the "md" at the end.
I then ran the tflite_convert command for the model i created (the one that i failed to properly convert up to now) and i got a tflite model ~18KB that is loadable in python, was successfully used to create an interpreter and run inference for a testimage.
So from my understanding the code in python that i was trying to create to convert my saved_model to a tflite model was basically the way that the tflite_convert command uses just that it enables to option to add extra optimization steps as well as quantization. Is that correct?
srjoglekar246
commented
3 years ago No, that model size doesn't sound right. AFAIK, it only happens when an older version of the converter doesn't know how to handle the TFLite-friendly SavedModel - as a result, it outputs a small model with just some zeros as outputs. Any converter after version 2.4 should be able to handle it, but in your setup for some reason it doesn't :-/
CaptainPineapple
commented
3 years ago No, that model size doesn't sound right. AFAIK, it only happens when an older version of the converter doesn't know how to handle the TFLite-friendly SavedModel - as a result, it outputs a small model with just some zeros as outputs. Any converter after version 2.4 should be able to handle it, but in your setup for some reason it doesn't :-/
ah hold on i was just too stupid: its 10'000KB -> 10MB In the end as i wrote above: the tflite mode works. I can load it. I can run inference on it. At lease for me that sounds like the conversion was successful :)
srjoglekar246
commented
3 years ago Oh I just saw your code carefully again, and looks like you are using from_concrete_functions. We need to use from_saved_model for the converter to read the annotations that export_tflite_graph_t2.py puts into the model :-)
CaptainPineapple
commented
3 years ago Oh I just saw your code carefully again, and looks like you are using
from_concrete_functions. We need to usefrom_saved_modelfor the converter to read the annotations thatexport_tflite_graph_t2.pyputs into the model :-)
ah yes that makes sense as i added this as a workaround that was needed for the wrongly created saved_model file. And that apparently was the issue all along. model converts and inference returns reasonable data. Thank you so much for your support @srjoglekar246 . You really are my lifesaver here. As the basic setup now works correctly i'll try to figure out the quantization myself.
TL;DR for others up to here:
converter = tf.lite.TFLiteConverter.from_saved_model(MODEL_PATH)Load mobile-friendly model and Model Conversion from this workflow to check your setup for possible issues.srjoglekar246
commented
3 years ago Nice! and happy to help :-)
 yeshbourne
commented
3 years ago
yeshbourne
commented
3 years ago import numpy as np import tensorflow as tf
image_data = tf.data.Dataset.list_files('./quant-images/*.jpg') (HEIGHT, WIDTH) = (640, 640)
def representative_dataset_gen(): for image_path in image_data: img = tf.io.read_file(image_path) img = tf.io.decode_image(img, channels=3) img = tf.image.convert_image_dtype(img, tf.float32) resized_img = tf.image.resize(img, (HEIGHT, WIDTH)) resized_img = resized_img[tf.newaxis, :] yield [resized_img]
model_path = './exported-models/ptag-detector-model/ssd_mobilenet_v2_fpnlite_640x640/saved_model'
converter = tf.lite.TFLiteConverter.from_saved_model(model_path) # using tensorflow
converter.representative_dataset = representative_dataset_gen converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.uint8 converter.inference_output_type = tf.uint8 converter.quantized_input_stats = {'normalized_input_image_tensor': (128, 128)} converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model_quant = converter.convert()
interpreter = tf.lite.Interpreter(model_content=tflite_model_quant) input_type = interpreter.get_input_details()[0]['dtype'] print ('input: ', input_type) output_type = interpreter.get_output_details()[0]['dtype'] print ('output: ', output_type)
with open('detect_quant.tflite', 'wb') as f: f.write(tflite_model_quant)
 canseloguzz
commented
3 years ago
canseloguzz
commented
3 years ago For those who are still struggling to get the model converted here's my code for full quantization for edge-tpu compatibility
import numpy as np import tensorflow as tf
path to images
image_data = tf.data.Dataset.list_files("./quant-images/*.jpg") HEIGHT, WIDTH = 640, 640
def representative_dataset_gen(): for image_path in image_data: img = tf.io.read_file(image_path) img = tf.io.decode_image(img, channels=3) img = tf.image.convert_image_dtype(img, tf.float32) resized_img = tf.image.resize(img, (HEIGHT, WIDTH)) resized_img = resized_img[tf.newaxis, :] yield [resized_img]
model_path = './exported-models/ptag-detector-model/ssd_mobilenet_v2_fpnlite_640x640/saved_model'
import trained model from mobilenet 640 v2 fpn
converter = tf.lite.TFLiteConverter.from_saved_model(model_path) #using tensorflow
converter.representative_dataset = representative_dataset_gen converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.uint8 converter.inference_output_type = tf.uint8 converter.quantized_input_stats = {"normalized_input_image_tensor": (128, 128)} converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model_quant = converter.convert()
interpreter = tf.lite.Interpreter(model_content=tflite_model_quant) input_type = interpreter.get_input_details()[0]['dtype'] print('input: ', input_type) output_type = interpreter.get_output_details()[0]['dtype'] print('output: ', output_type)
with open('detect_quant.tflite', 'wb') as f: f.write(tflite_model_quant)
Hello, thanks for sharing code. I want to try but can you explain what is the "./quant-images/*.jpg" . I'm working with coco dataset. What ı will give there? Thanks.
yeshbourne
commented
3 years ago For those who are still struggling to get the model converted here's my code for full quantization for edge-tpu compatibility import numpy as np import tensorflow as tf
path to images
image_data = tf.data.Dataset.list_files("./quant-images/*.jpg") HEIGHT, WIDTH = 640, 640 def representative_dataset_gen(): for image_path in image_data: img = tf.io.read_file(image_path) img = tf.io.decode_image(img, channels=3) img = tf.image.convert_image_dtype(img, tf.float32) resized_img = tf.image.resize(img, (HEIGHT, WIDTH)) resized_img = resized_img[tf.newaxis, :] yield [resized_img] model_path = './exported-models/ptag-detector-model/ssd_mobilenet_v2_fpnlite_640x640/saved_model'
import trained model from mobilenet 640 v2 fpn
converter = tf.lite.TFLiteConverter.from_saved_model(model_path) #using tensorflow converter.representative_dataset = representative_dataset_gen converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.uint8 converter.inference_output_type = tf.uint8 converter.quantized_input_stats = {"normalized_input_image_tensor": (128, 128)} converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_model_quant = converter.convert() interpreter = tf.lite.Interpreter(model_content=tflite_model_quant) input_type = interpreter.get_input_details()[0]['dtype'] print('input: ', input_type) output_type = interpreter.get_output_details()[0]['dtype'] print('output: ', output_type) with open('detect_quant.tflite', 'wb') as f: f.write(tflite_model_quant)
Hello, thanks for sharing code. I want to try but can you explain what is the "./quant-images/*.jpg" . I'm working with coco dataset. What ı will give there? Thanks.
Since, I'm using a custom image set to train the folder point to the location of a my sample image set directory. In your case you can take a sample of 100 images from coco dataset and create a directory to convert. Just make sure you're setting the right dimension of the image you used for training since I'm using mobilenet v2 640x640 I'm resizing my images to that dimension.
canseloguzz
commented
3 years ago For those who are still struggling to get the model converted here's my code for full quantization for edge-tpu compatibility import numpy as np import tensorflow as tf
path to images
image_data = tf.data.Dataset.list_files("./quant-images/*.jpg") HEIGHT, WIDTH = 640, 640 def representative_dataset_gen(): for image_path in image_data: img = tf.io.read_file(image_path) img = tf.io.decode_image(img, channels=3) img = tf.image.convert_image_dtype(img, tf.float32) resized_img = tf.image.resize(img, (HEIGHT, WIDTH)) resized_img = resized_img[tf.newaxis, :] yield [resized_img] model_path = './exported-models/ptag-detector-model/ssd_mobilenet_v2_fpnlite_640x640/saved_model'
import trained model from mobilenet 640 v2 fpn
converter = tf.lite.TFLiteConverter.from_saved_model(model_path) #using tensorflow converter.representative_dataset = representative_dataset_gen converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.uint8 converter.inference_output_type = tf.uint8 converter.quantized_input_stats = {"normalized_input_image_tensor": (128, 128)} converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_model_quant = converter.convert() interpreter = tf.lite.Interpreter(model_content=tflite_model_quant) input_type = interpreter.get_input_details()[0]['dtype'] print('input: ', input_type) output_type = interpreter.get_output_details()[0]['dtype'] print('output: ', output_type) with open('detect_quant.tflite', 'wb') as f: f.write(tflite_model_quant)
Hello, thanks for sharing code. I want to try but can you explain what is the "./quant-images/*.jpg" . I'm working with coco dataset. What ı will give there? Thanks.
Since, I'm using a custom image set to train the folder point to the location of a my sample image set directory. In your case you can take a sample of 100 images from coco dataset and create a directory to convert. Just make sure you're setting the right dimension of the image you used for training since I'm using mobilenet v2 640x640 I'm resizing my images to that dimension.
Thanks. When i try as you said, i'm getting this errror. Have you got any idea for solution?
2021-09-07 10:42:39.125057: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-09-07 10:42:39.229012: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-09-07 10:42:39.230465: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-09-07 10:42:39.233353: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2021-09-07 10:42:39.235223: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-09-07 10:42:39.236955: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-09-07 10:42:39.238333: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-09-07 10:42:40.885935: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-09-07 10:42:40.887348: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-09-07 10:42:40.888663: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2021-09-07 10:42:40.889893: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 6522 MB memory: -> device: 0, name: NVIDIA GeForce RTX 2060 SUPER, pci bus id: 0000:01:00.0, compute capability: 7.5 buraya kadar ok! 2021-09-07 10:42:48.441192: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:351] Ignored output_format. 2021-09-07 10:42:48.441211: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:354] Ignored drop_control_dependency. 2021-09-07 10:42:48.441215: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:360] Ignored change_concat_input_ranges. 2021-09-07 10:42:48.441809: I tensorflow/cc/saved_model/reader.cc:38] Reading SavedModel from: /home/trio/Tensorflow/models/research/object_detection/my_train/exported/saved_model 2021-09-07 10:42:48.503227: I tensorflow/cc/saved_model/reader.cc:90] Reading meta graph with tags { serve } 2021-09-07 10:42:48.503259: I tensorflow/cc/saved_model/reader.cc:132] Reading SavedModel debug info (if present) from: /home/trio/Tensorflow/models/research/object_detection/my_train/exported/saved_model 2021-09-07 10:42:48.744661: I tensorflow/cc/saved_model/loader.cc:211] Restoring SavedModel bundle. 2021-09-07 10:42:49.202077: I tensorflow/cc/saved_model/loader.cc:195] Running initialization op on SavedModel bundle at path: /home/trio/Tensorflow/models/research/object_detection/my_train/exported/saved_model 2021-09-07 10:42:49.413967: I tensorflow/cc/saved_model/loader.cc:283] SavedModel load for tags { serve }; Status: success: OK. Took 972158 microseconds. 2021-09-07 10:42:50.216415: I tensorflow/compiler/mlir/tensorflow/utils/dump_mlir_util.cc:210] disabling MLIR crash reproducer, set env varMLIR_CRASH_REPRODUCER_DIRECTORY` to enable.
loc(callsite(callsite("Postprocessor/BatchMultiClassNonMaxSuppression/MultiClassNonMaxSuppression/ChangeCoordinateFrame/Scale/concat@__inference_call_func_10466" at "StatefulPartitionedCall@__inference_signature_wrapper_12450") at "StatefulPartitionedCall")): error: 'tf.ConcatV2' op is neither a custom op nor a flex op
error: failed while converting: 'main':
Some ops are not supported by the native TFLite runtime, you can enable TF kernels fallback using TF Select. See instructions: https://www.tensorflow.org/lite/guide/ops_select
TF Select ops: ConcatV2
Details:
tf.ConcatV2(tensor
Traceback (most recent call last):
File "quantize.py", line 30, in
srjoglekar246
commented
3 years ago @canseloguzz Can you try the instructions here to convert & run your model? Please try and see if the floating point conversion works fine first, then quantized.
 sayannath
commented
2 years ago
sayannath
commented
2 years ago @canseloguzz Can you try the instructions here to convert & run your model? Please try and see if the floating point conversion works fine first, then quantized.
Hello @srjoglekar246 I have used this tutorial and tried to do the inference in android device it failed. Any workaround for this. I used SSD MobileNet 320x320.
I trained the model on my custom dataset. Exported the model using exporter_main_v2.py
The command I used:
python exporter_main_v2.py --input_type image_tensor --pipeline_config_path=models/ssd_mobilenet_v2_320x320_coco17_tpu-8/pipeline.config --trained_checkpoint_dir=models/ssd_mobilenet_v2_320x320_coco17_tpu-8 --output_directory exported_models/my_modelAfter exporting the model, I exported the TensorFlow Inference Graph
python export_tflite_graph_tf2.py --pipeline_config_path=models/ssd_mobilenet_v2_320x320_coco17_tpu-8/pipeline.config --trained_checkpoint_dir=models/ssd_mobilenet_v2_320x320_coco17_tpu-8 --output_directory=exported_models/tflite_export/After this I converted the model into tflite
TFLITE_MODEL_PATH = "detector.tflite"
converter = tf.lite.TFLiteConverter.from_saved_model(exported_models/tflite_export//saved_model')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
with open(TFLITE_MODEL_PATH, 'wb') as f:
f.write(tflite_model)This is the floating point TF-Lite File. It's not working even after adding the metadata. I followed the steps mentioned here
Even I used this Colab Notebook, used this model but model was crashing on my android device. I downloaded a model from TF-Hub to check my app it was working fine.
I even used Netron to visualise the tflite file. There was a difference in both of them. The major difference is in the input arrays and output arrays.
The TF-Hub model accepts input as normalized_input_image_tensor and output arrays are TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1','TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3
But the tflite file which is converted doest not have this I also used this command to convert my model into tflite.
tflite_convert \
--saved_model_dir=exported_models/tflite_export/saved_model \
--output_file=exported_models/tflite_export/saved_model/detect.tflite \
--input_shapes=1,320,320,3 \
--input_arrays=normalized_input_image_tensor \
--output_arrays='TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1','TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3' \
--inference_type=FLOATThe tflite I got after conversion is 2KB and I have used neutron to view it does not have any layers.
srjoglekar246
commented
2 years ago @sayannath You don't have you use exporter_main_v2.py is you are using export_tflite_graph_tf2.py.
Also, avoid providing any output_arrays & input_arrays params to tflite_convert. The actual model may have different different names for the tensors.
 judahkshitij
commented
2 years ago
judahkshitij
commented
2 years ago @srjoglekar246 & Others, I have been trying to run inference after converting few models from TF2 obj detection zoo to TFLite using the process described in this guide, but getting wrong results from the tflite model (I am trying basic tflite model without doing any quantization or any other optimization as a first step).
The models I have tried are:
ssd_mobilenet_v2_320x320_coco17_tpu-8 ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8 ssd_mobilenet_v1_fpn_640x640_coco17_tpu-8 ssd_resnet101_v1_fpn_640x640_coco17_tpu-8
The inference code I am using is similar to that posted by OP in this thread: https://github.com/tensorflow/models/issues/9287.
Do we still need to export checkpoint using export_tflite_graph_tf2.py first and then convert resulting saved model to tflite(to be able to leverage various levels of quantization), or can we now (in April 2022) directly convert to tflite the saved model that gets downloaded when we download a model from TF2 detection zoo? Any help is appreciated.
judahkshitij
commented
2 years ago @SukyoungCho Were you able to successfully convert (by successfully convert, I mean not only able to convert to tflite models but also got decent/expected results) models from TF2 object detection zoo to tflite format while taking advantage of various types quantizations? Any help is appreciated. Thanks.
 Petros626
commented
2 years ago
Petros626
commented
2 years ago @srjoglekar246 finally found a way to do it? seems that only @CaptainPineapple was successful
sayannath
commented
2 years ago Can you share the process @Petros626 ?
Petros626
commented
2 years ago @sayannath I have no process to share, only asking before I do the wrong thing. I converted in TF1 my model to a TFLite model successfully, but I know TensorFlow is sometimes difficult, so I wanted to ask first, if someone converted FPNLite 320x320 or 640x640 to a TFLite Model
Hi, I was wondering if anyone could help how to convert and quantize SSD models on TF2 Object Detection Model Zoo. It seems like there's a difference in converting to .tflite in TF1 and TF2. To the best of my knowledge, in TF1, we first frozen the model using exporter and then quantized and converted it into .tflite. And, I had no problem in doing it in TF1. The models I tried was
However, when I followed the guideline provided on the github repo 1.(https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/running_on_mobile_tf2.md#step-1-export-tflite-inference-graph) and 2. (https://www.tensorflow.org/lite/performance/post_training_quantization#full_integer_quantization). I was not able to convert them into .tflite.
Running "Step 1: Export TFLite inference graph", created saved_model.pb file in the given output dir {inside ./saved_model/} However, it displayed the skeptic messages below while exporting them, and not sure if it's run properly.
Running "Step 2: Convert to TFLite", is the pain in the ass. I managed to convert the model generated in the step 1 into .tflite without any quantization following the given command, although I am not sure if it can be deployed on the mobile devices.
But, I am trying to deploy it on the board with the coral accelerator and need to conver the model into 'uint8' format. I thought the models provided on the model zoo are not QAT trained, and hence they require PTQ. Using the command line below,
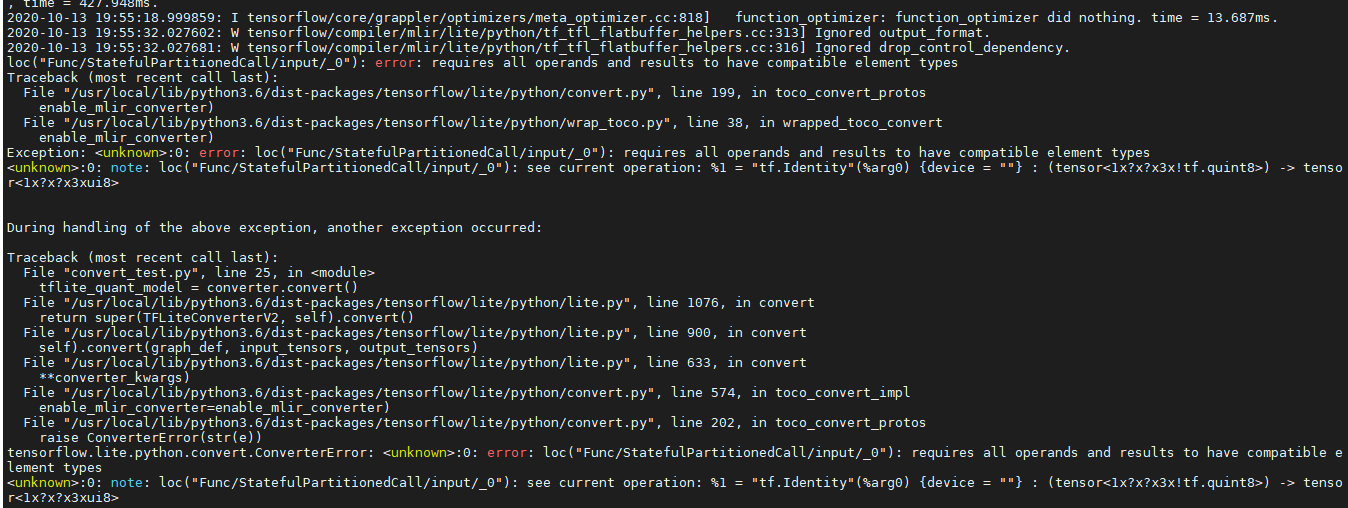
It shows the error message below, and i am not able to convert the model into .tflite format. I think the error occurs because something went wrong in the first step.
Below, I am attaching the sample script I used to run "Step 2". I have never train a model, and i am just trying to check if it is possible to convert SSD models on TF 2 OD API Model Zoo into Uint8 format .tflite. That is why, i dont have the sample data used to train the model, and just using MNIST data in Keras to save the time and cost to create data. (checkpoint CKPT = 0)
The environment description. CUDA = 10.1 Tensorflow = 2.3, 2.2 (both are tried) TensorRT = ii libnvinfer-plugin6 6.0.1-1+cuda10.1 amd64 TensorRT plugin libraries ii libnvinfer6 6.0.1-1+cuda10.1 amd64 TensorRT runtime libraries
It would be appreciated if anyone could help to solve the issue, or provide a guideline. @srjoglekar246 Would you be able to provide the guideline or help me to convert models into uint8? Hope you documented while you were enabling SSD models to be converted into .tflite. Thank you so much.
**_
_**