MichaelBroughton
commented
4 years ago
MichaelBroughton
commented
4 years ago I'm having a hard time following exactly what's going on here. It looks like there might be several different issues at play. With regards to:
I have tried to input a tensor into cirq and gotten this: place = tf.compat.v1.placeholder(tf.float32, shape=(4,1)) placeholder = cirq.ry(place)(cirq.GridQubit(0,0)) placeholder ## -> cirq.ry(np.pi*<tf.Tensor 'truediv_25:0' shape=(4, 1) dtype=float32>).on(cirq.GridQubit(0, 0)) When it is embedded inside of a circuit and called like this it gives an error: circuit1 = cirq.Circuit() circuit1.append(cirq.ry(place)(cirq.GridQubit(0,0))) circuit1 ## ->TypeError: int() argument must be a string, a bytes-like object or a number, not 'Tensor' When it is called inside of the layer using
tfq.convert_to_tensorthe error shows: TypeError: can't pickle _thread.RLock objects
This is caused by misuse of TensorFlow and Cirq together. Cirq does not support using or operating on tf.Tensor objects (otherwise we wouldn't need TensorFlow Quantum). In order to understand how to create and evaluate parameterized circuits in TensorFlow Quantum I would recommend checking out: https://www.tensorflow.org/quantum/tutorials/hello_many_worlds
This tutorial showcases some examples of how upstream tf.Tensors can be passed into the variables in quantum circuits that are downstream in the compute graph like you want to do with your ASDF2 layer.
Does this help clear things up ?
 m0tela01
m0tela01

 zaqqwerty
zaqqwerty
Hello
Is there a way to pass a tensor in a form that is usable by cirq when it is passed from an upstream layer during training?
I have a tensor from a Dense layer. I want to run it through a custom layer and perform some tensor operations. This layer then outputs/returns a cirq circuit I designed. We can remove the functions in the layer or the layer entirely to make the problem more clear. Is there a way to pass a tensor into a cirq circuit using tfq/tf/cirq so that it can be trained?
I was assuming that since tensorflow is graph based none of the values would be accessible for training (i.e. you cannot
get_weights()or evaluate the network in the middle of training to produce a numpy array/float value to pass into the circuit. Is there any way to go about this from any of the packages inside of tfq/tf/cirq/keras? I have tried using antfq.layers.Expectation()by passing the tensor as the initializer. I have tried to find a solution to this using cirq functions as well but have not had success. Was thinking of also posting this in the cirq issues but (at least right now) believe this is more related to tfq than cirq.Please let me know if there is anything below that is unclear or needs further explanation. Thanks in advance.
Code
I have tried to input a tensor into cirq and gotten this:
place = tf.compat.v1.placeholder(tf.float32, shape=(4,1))placeholder = cirq.ry(place)(cirq.GridQubit(0,0))placeholder ## -> cirq.ry(np.pi*<tf.Tensor 'truediv_25:0' shape=(4, 1) dtype=float32>).on(cirq.GridQubit(0, 0))When it is embedded inside of a circuit and called like this it gives an error:
circuit1 = cirq.Circuit()circuit1.append(cirq.ry(place)(cirq.GridQubit(0,0)))circuit1 ## ->TypeError: int() argument must be a string, a bytes-like object or a number, not 'Tensor'When it is called inside of the layer usingtfq.convert_to_tensorthe error shows:TypeError: can't pickle _thread.RLock objectsThe functions from the layer: GetAngles3(weights): creates tensors with shape=(4,) CreateCircuit2(x): creates a cirq circuit using tfq.convert_to_tensor ` following the documetation
Here is the layer itself:
class ASDF2(tf.keras.layers.Layer): def __init__(self, outshape=4, qubits=cirq.GridQubit.rect(1, 4)): super(ASDF2, self).__init__() self.outshape = outshape self.qubits = qubits def build(self, input_shape): self.kernel = self.add_weight(name='kernel', shape=(int(input_shape[1]), self.outshape), trainable=True) super(ASDF2, self).build(input_shape) def call(self, inputs, **kwargs): try: x = GetAngles3(inputs) y = CreateCircuit2(x) return y except: x = tf.dtypes.cast(inputs, tf.dtypes.string) return tf.keras.backend.squeeze(x, 0)
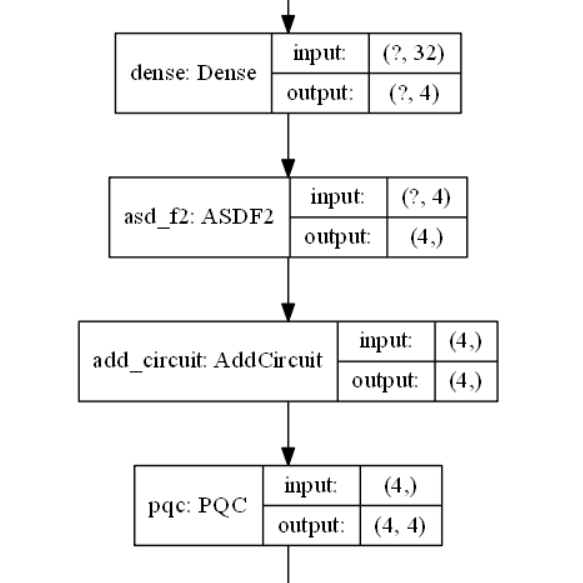
Here is the output when the model runs:
Train on 78 samples, validate on 26 samplesEpoch 1/25****************inputsTensor("model/dense/Sigmoid:0", shape=(None, 4), dtype=float32)****************GetAnglesTensor("model/dense/Sigmoid:0", shape=(None, 4), dtype=float32)[<tf.Tensor 'model/asd_f2/Asin:0' shape=(None, 4) dtype=float32>, <tf.Tensor 'model/asd_f2/mul:0' shape=(None, 4) dtype=float32>, <tf.Tensor 'model/asd_f2/mul_1:0' shape=(None, 4) dtype=float32>, <tf.Tensor 'model/asd_f2/mul_2:0' shape=(None, 4) dtype=float32>, <tf.Tensor 'model/asd_f2/mul_3:0' shape=(None, 4) dtype=float32>]****************createCircuitWARNING:tensorflow:Gradients do not exist for variables ['conv1d/kernel:0', 'conv1d/bias:0', 'dense/kernel:0', 'dense/bias:0', 'asd_f2/kernel:0'] when minimizing the loss.****************inputsTensor("model/dense/Sigmoid:0", shape=(None, 4), dtype=float32)****************GetAnglesTensor("model/dense/Sigmoid:0", shape=(None, 4), dtype=float32)[<tf.Tensor 'model/asd_f2/Asin:0' shape=(None, 4) dtype=float32>, <tf.Tensor 'model/asd_f2/mul:0' shape=(None, 4) dtype=float32>, <tf.Tensor 'model/asd_f2/mul_1:0' shape=(None, 4) dtype=float32>, <tf.Tensor 'model/asd_f2/mul_2:0' shape=(None, 4) dtype=float32>, <tf.Tensor 'model/asd_f2/mul_3:0' shape=(None, 4) dtype=float32>]****************createCircuitWARNING:tensorflow:Gradients do not exist for variables ['conv1d/kernel:0', 'conv1d/bias:0', 'dense/kernel:0', 'dense/bias:0', 'asd_f2/kernel:0'] when minimizing the loss.Here is a plot of the model where ASDF2 is the layer I created: