 yanwii
commented
5 years ago
yanwii
commented
5 years ago In your registered problem, there is a function name generate_encoded_samples
@registry.register_problem
class TranslateEnzhSub50k(translate.TranslateProblem):
...
def generate_encoded_samples(self, data_dir, tmp_dir, dataset_split):
generator = self.generate_samples(data_dir, tmp_dir, dataset_split)
encoder = self.get_vocab(data_dir)
target_encoder = self.get_vocab(data_dir, is_target=True)
return text_problems.text2text_generate_encoded(generator, encoder, target_encoder,
has_inputs=self.has_inputs)
def get_vocab(self, data_dir, is_target=False):
vocab_filename = os.path.join(data_dir, self.target_vocab_name if is_target else self.source_vocab_name)
if not tf.gfile.Exists(vocab_filename):
raise ValueError("Vocab %s not found" % vocab_filename)
return text_encoder.SubwordTextEncoder(vocab_filename, replace_oov="UNK")The function text2text_generate_encoded used for encoding your inputs. So, you problem should be change to:
def text2text_generate_encoded(sample_generator,
vocab,
targets_vocab=None,
has_inputs=True):
"""Encode Text2Text samples from the generator with the vocab."""
targets_vocab = targets_vocab or vocab
for sample in sample_generator:
if has_inputs:
# call the function
sample["inputs"] = vocab.encode_without_tokenizing(sample["inputs"])
sample["inputs"].append(text_encoder.EOS_ID)
sample["targets"] = targets_vocab.encode_without_tokenizing(sample["targets"])
sample["targets"].append(text_encoder.EOS_ID)
yield sample
@registry.register_problem
class TranslateEnzhSub50k(translate.TranslateProblem):
...
def generate_encoded_samples(self, data_dir, tmp_dir, dataset_split):
generator = self.generate_samples(data_dir, tmp_dir, dataset_split)
encoder = self.get_vocab(data_dir)
target_encoder = self.get_vocab(data_dir, is_target=True)
# call local encoding generator
return text2text_generate_encoded(generator, encoder, target_encoder,
has_inputs=self.has_inputs)
def get_vocab(self, data_dir, is_target=False):
vocab_filename = os.path.join(data_dir, self.target_vocab_name if is_target else self.source_vocab_name)
if not tf.gfile.Exists(vocab_filename):
raise ValueError("Vocab %s not found" % vocab_filename)
return text_encoder.SubwordTextEncoder(vocab_filename, replace_oov="UNK")
 yourSylvia
yourSylvia
Description
I came across with some trouble in generating training data using t2t-datagen. The tokenizes are messy.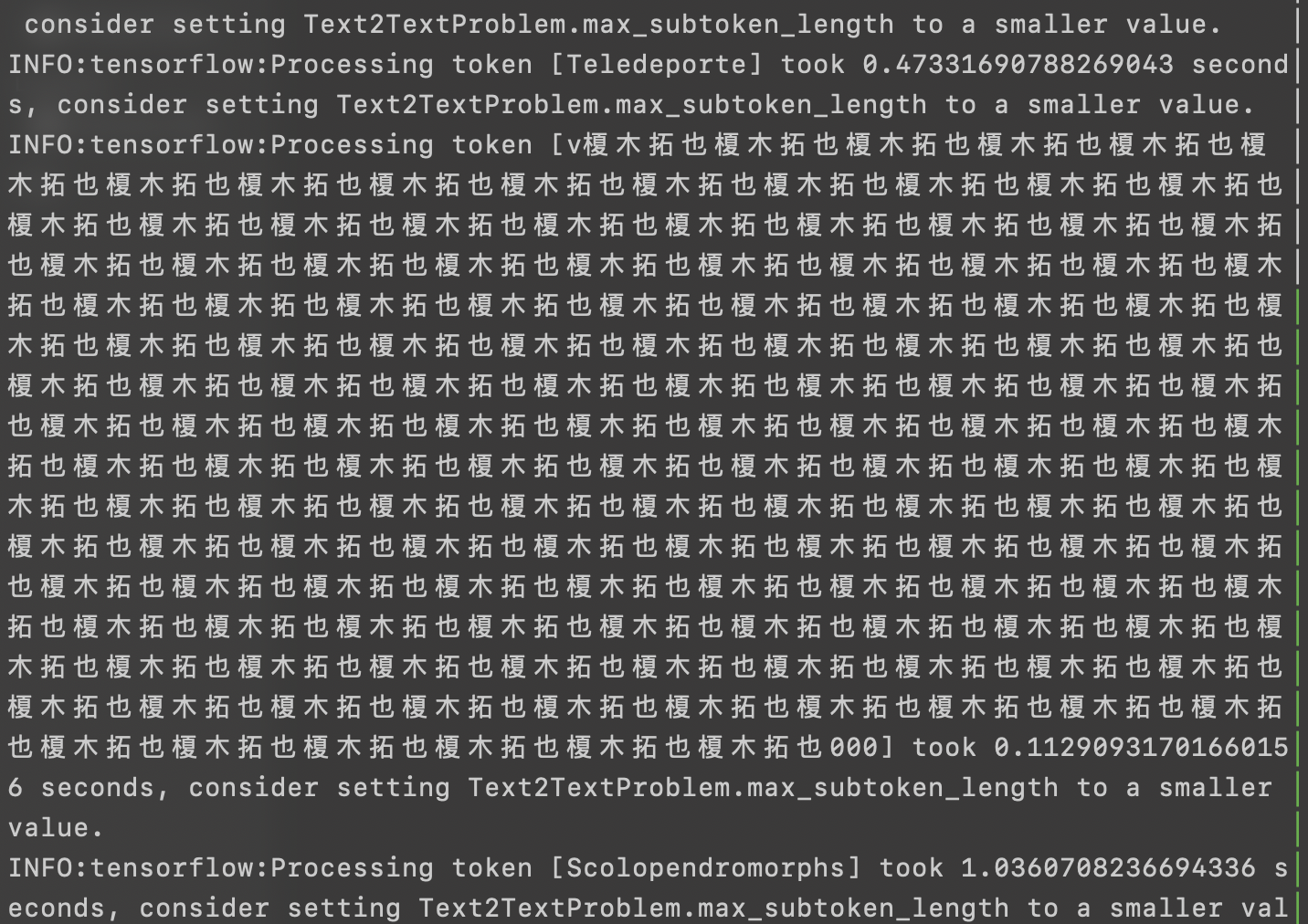
I found a function in tensor2tensor/tensor2tensor/data_generators/text_encoder.py, which can be used to generate data without tokenize. How to use it with my own registered problem? I have no idea where to put it...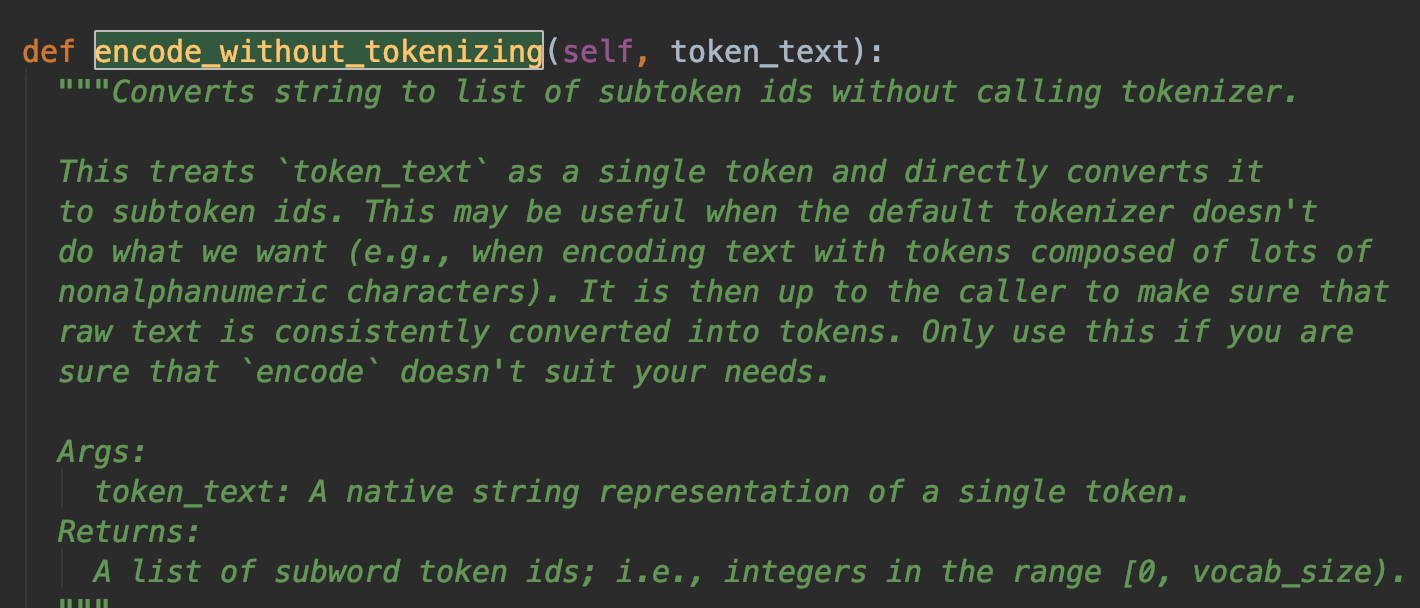
Anyone can help?
Environment information
tensorflow-gpu 1.13.1 tensor2tensor 1.13.0