 quaeler
commented
6 years ago
quaeler
commented
6 years ago Installing from binary ( https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.4.1-cp27-none-linux_x86_64.whl ) on Ubuntu 17.10, Python 2.7.14, i also see the moire-style pattern evolution.

 Gemesys
Gemesys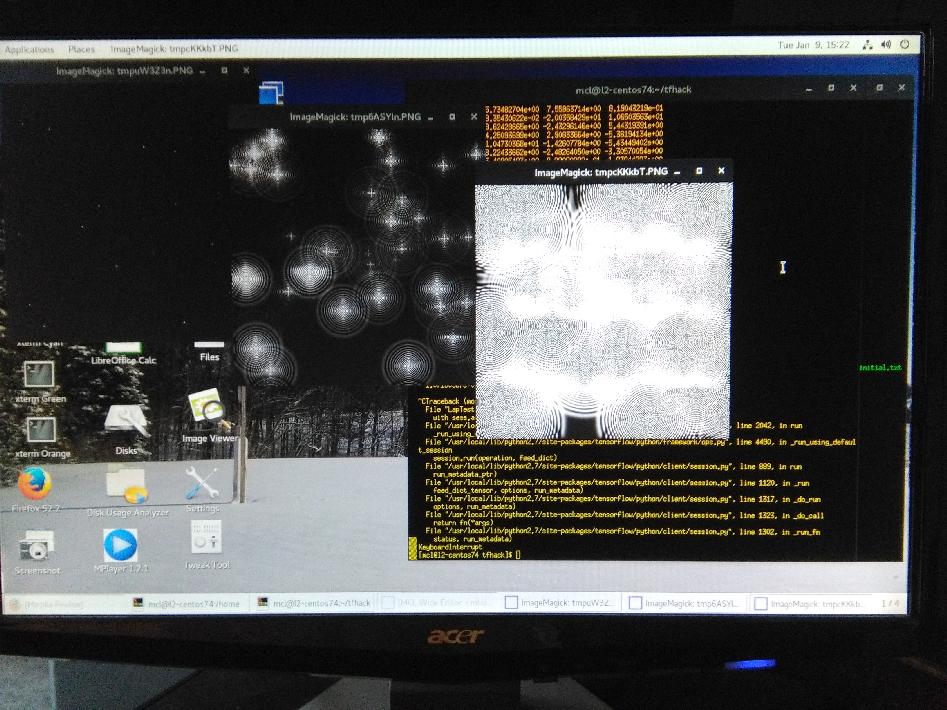

 cy89
cy89



 And now, what is particularly annoying, is that I cannot re-install my built-from-source version of TensorFlow-1.4.1, despite having pointed to and started the locally-built Python without problem.
There is a wrapper file in the /usr/local/lib/python2.7/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so which is failing on a "Symbol not found: _PyUnicodeUCS_AsASCIIString" Arrgh!
What looks to have happened, is that installing the binay Tensorflow (with it's unicode=ucs2 default) has trashed the local-built Python 2.7 library. I have the ucs4 Python in the path, any attempt to import my local built TensorFlow in Python is failing. I will have to resolve this before I can determine what is wrong with the TensorFlow math under Yosemite.
And now, what is particularly annoying, is that I cannot re-install my built-from-source version of TensorFlow-1.4.1, despite having pointed to and started the locally-built Python without problem.
There is a wrapper file in the /usr/local/lib/python2.7/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so which is failing on a "Symbol not found: _PyUnicodeUCS_AsASCIIString" Arrgh!
What looks to have happened, is that installing the binay Tensorflow (with it's unicode=ucs2 default) has trashed the local-built Python 2.7 library. I have the ucs4 Python in the path, any attempt to import my local built TensorFlow in Python is failing. I will have to resolve this before I can determine what is wrong with the TensorFlow math under Yosemite.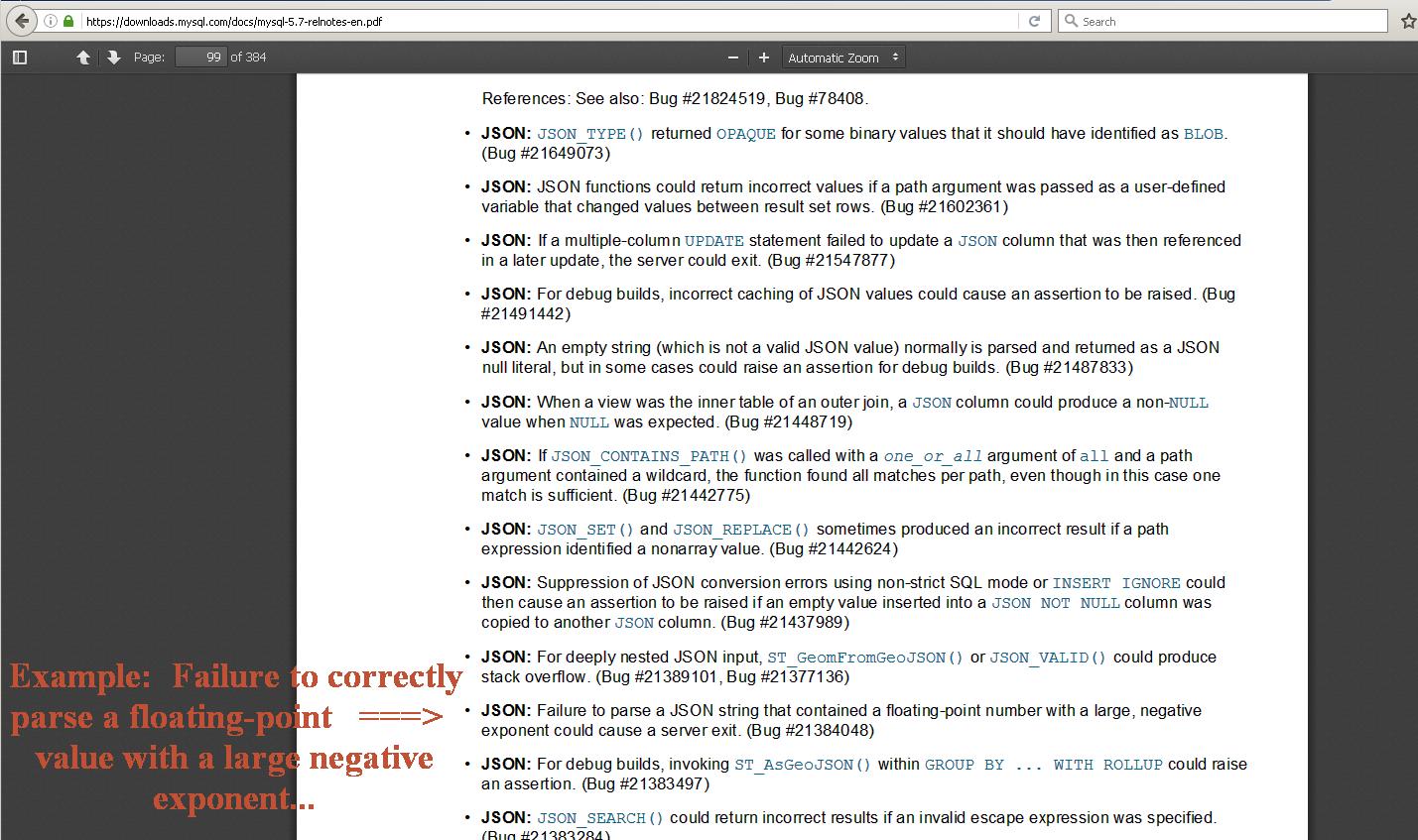
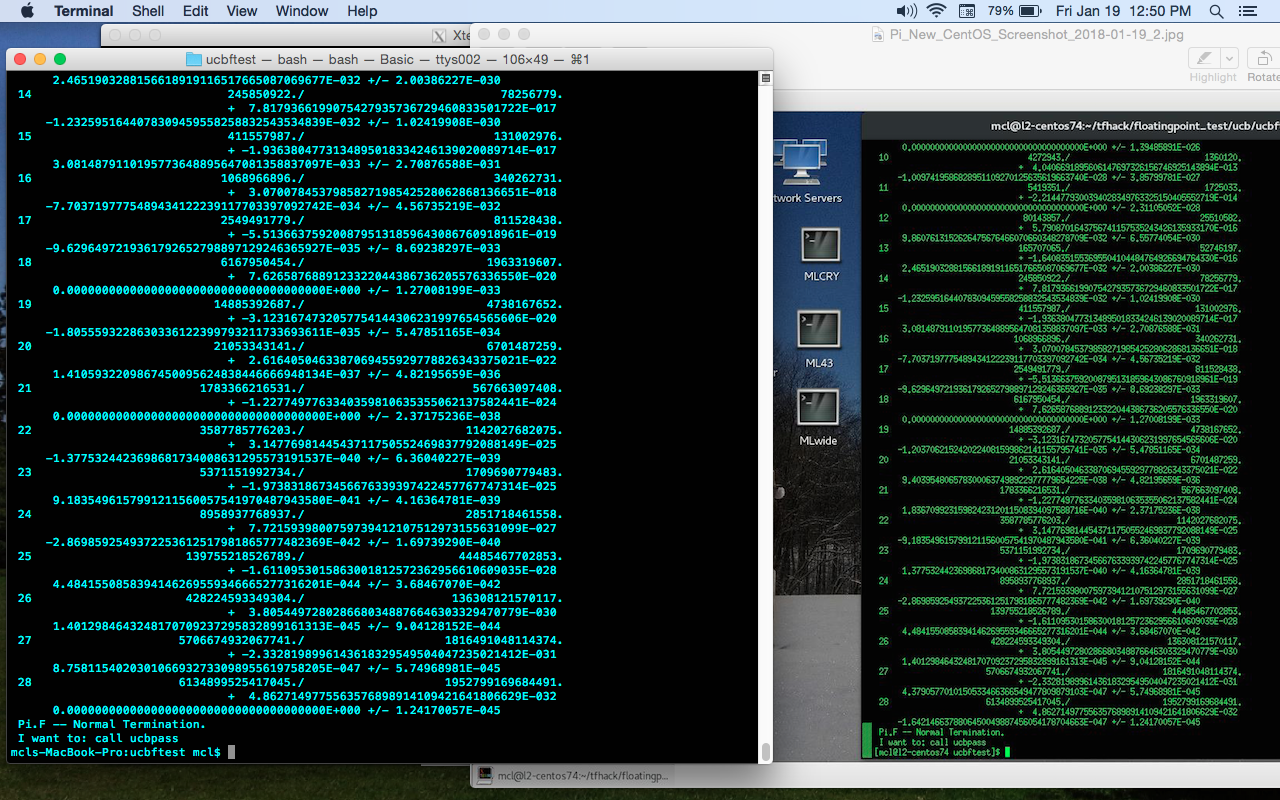 tests for internal consistancy, which both platforms pass. At iteration 8, the remainders are different. And at iterations 19 to 24 show serious divergence in the remainder values. The remainder on iteration 23 on the Macbook, is the value for the the remainder for iteration 22 on the CentOS box, but with the sign flipped. The remainder for iteration 22 on the Macbook (-1.37753244... E-40), is the value for the remainder for iteration 23 on the CentOS box, but again, with the sign flipped to positive. But by iterations 24, 25 and 26, the results are exactly the same, only to diverge again for iterations 27 and 28. To me, this seems to indicate a rather serious issue, which appears to be independent of TensorFlow. The MacBook is giving different results than the 64-bit Linux box.
tests for internal consistancy, which both platforms pass. At iteration 8, the remainders are different. And at iterations 19 to 24 show serious divergence in the remainder values. The remainder on iteration 23 on the Macbook, is the value for the the remainder for iteration 22 on the CentOS box, but with the sign flipped. The remainder for iteration 22 on the Macbook (-1.37753244... E-40), is the value for the remainder for iteration 23 on the CentOS box, but again, with the sign flipped to positive. But by iterations 24, 25 and 26, the results are exactly the same, only to diverge again for iterations 27 and 28. To me, this seems to indicate a rather serious issue, which appears to be independent of TensorFlow. The MacBook is giving different results than the 64-bit Linux box. 
 lewisl
lewisl

 tensorflowbutler
tensorflowbutler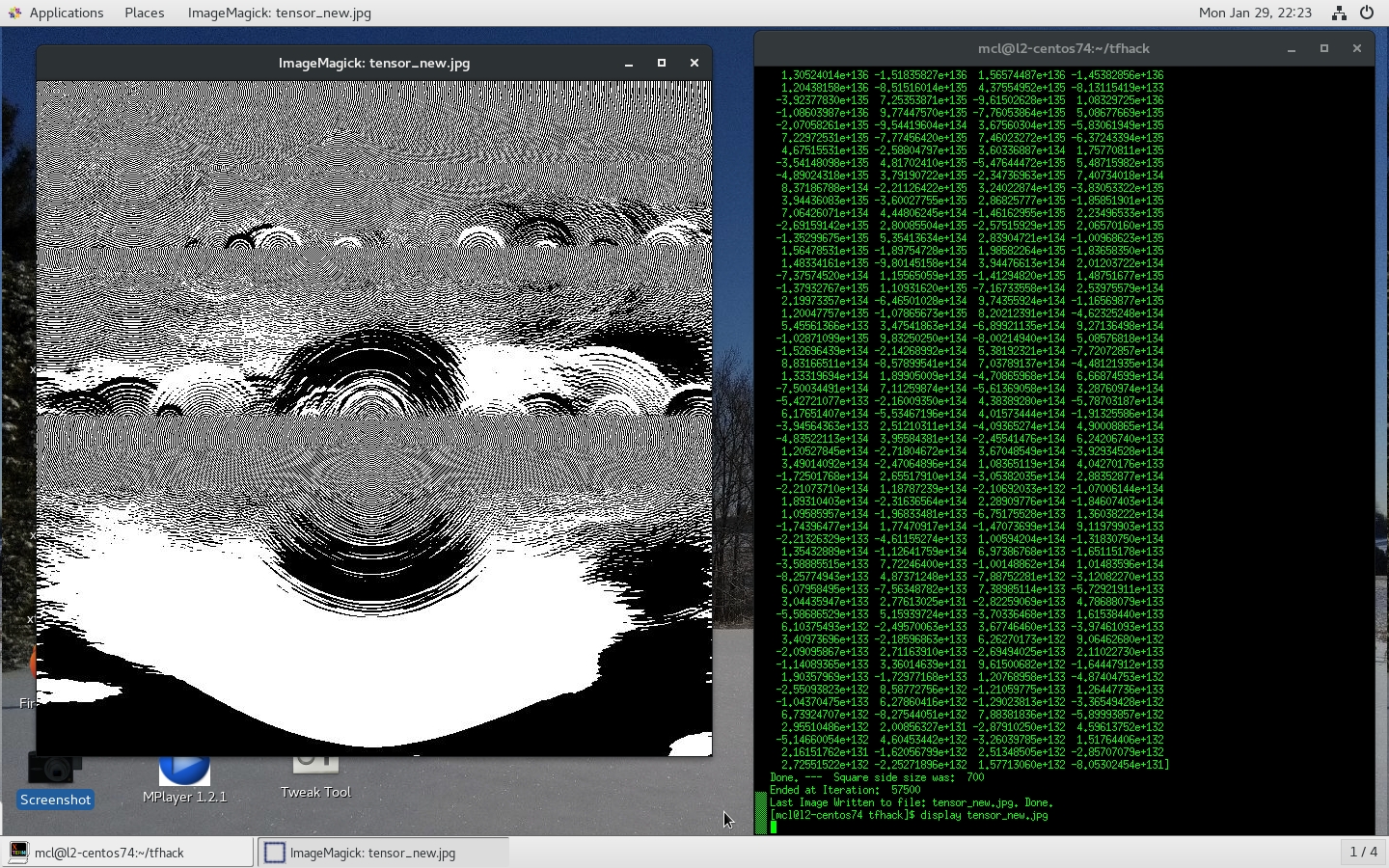
 skye
skye MarkDaoust
MarkDaoust martinwicke
martinwicke bjacob
bjacob bignamehyp
bignamehyp
System information
Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No.
OS Platform and Distribution (e.g., Linux Ubuntu 16.04):
Linux CentOS-7.4 and MacOSx 10.10.5
TensorFlow installed from (source or binary): Both; Installed from binary, then, built and installed from source. Same behaviour on each install.
TensorFlow version (use command below): Tensorflow 1.4.0 and Tensorflow 1.4.1
Python version: 2.7.14 (installed from binary, and then built and installed from source
Bazel version (if compiling from source): Bazel 0.9.0. Source built and installed successfully, Python .whl file built & installed successfully.
GCC/Compiler version (if compiling from source): Xcode7.2.1 and the Gnu gFortran, 5.2. (needed gFortran for SciPy install. All installs OK.)
CUDA/cuDNN version: N/A - compiled and running CPU versions only for now.
GPU model and memory:
Exact command to reproduce: (See supplied test program - based on the Laplace PDE ("Raindrops on Pond") simulation example from Tensorflow Tutorial)
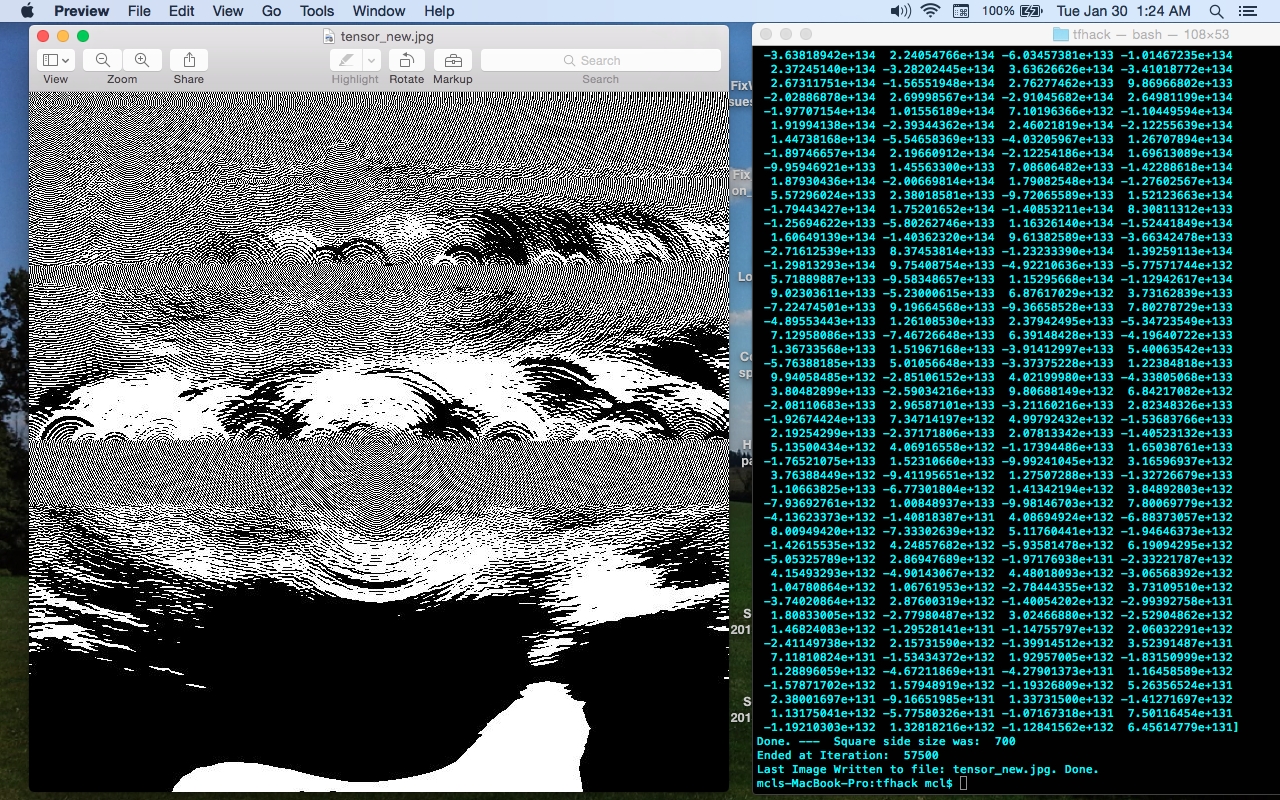
Description of Problem: I've run into a curious situation. I am getting very different behaviour in Tensorflow 1.4.1 on Linux and Tensorflow 1.4.1 on MacOSX, in straightforward image-generation simulation, based on the "Raindrops on a Pond" (Laplace PDE) example from the Tensorflow Tutorial.
I must stress that both Tensorflow installations seem to be 100% correct, and operate other tests correctly, producing the same numeric results for simple models.
I have also built Tensorflow 1.4.1 completely from source, and the Python 2.7.14 as well, on the MacOSX (MacBook) machine, in order to build the Python using "--enable-unicode=ucs4", since that was one difference I was able to find, between the two version. But even with the Macbook now running exactly the same Python 2.7.14 as the Linux box, I am still getting wildly divergent evoluationary behaviour as when I iterate the simple simulation. The numbers just zoom off in very different directions on each machine, and the generated images show this.
On the MacOSX, the simulation evolves very quickly to a pure white canvas (all "255"s), but on the Linux platform, the image grows more complex, with the generated numbers bifurcating between large negative and large positive - and hence when np.clip-ed, to range 0-255, show a complex moire-style pattern.
I have confirmed all related libraries and packages seem to be the same versions. The difference seems to be in the operation of Tensorflow.
This seems pretty serious, as each platform is Intel. The Linux box (CentOS-7.4) is Core-i3, while the Macbook is Core-i5. But both are 64-bit, and both Tensorflow installations seem to be correct. I have tried both the binary version, and then built a complete local version of Tensorflow 1.4.1 for the Macbook from source. Both seem to be Ok, and operate correctly. The Linux version of Tensorflow 1.4.0 was installed from binary appears to be operating correctly, albeit differently, but just for this one program.
When the sample program runs, it will display fourteen 400x400 images, as well as the numeric values of the row-20 of the "a" array (400 numbers). The program can be started from an Xterm shell window, with "python LapTest.py". It does not need Jupyter or IPython. With SciPy loaded, the images are rendered as .PNG files on both platforms, using Preview on the MacOSX MacBook, and ImageMagick on the CentOS-7.4 Linux box. Program runs fine to completion, and all looks ok on both machines.
But the results - even with the simple initial pseudo-random conditions - evolve completely differently, and consistantly. The Macbook version of Tensorflow 1.4.1 goes to a pure white screen, while the LInux Tensorflow 1.4.1 configuration evolves to a complex, chaotic, moire-pattern.
Leaving aside the question of even which machine is "correct", the expected result is of course that both machines should at least show clear evidence of similar behaviour.
No change was made to the test program, "LapTest.py", from one machine to the other. The different behaviour is not related to how the images are displayed, which is working fine on both platforms. A copy of this simple program is provided. I have removed or commented out the IPython/Jupyter dependent code, so this program can be run on plain vanilla Python 2.7.14, as long the appropriate packages (tensorflow, numpy, scipy, PIL (Pillow version), matplotlib, imageio ...) are available
Example of Source code to demostrate behaviour: LapTest.py
If someone could try this program on a supported version of Linux (ie. the Ubuntu version that TensorFlow officially supports), that would be helpful. I am running a recent version of the Linux kernel on the CentOS-7.4 box (uname -a reports: kernel version 4.14.9-1.el7.elrepo.x86_64 ). Really like to nail down what is happening. I have attached images of results I am seeing on the two machines, first the Linux box, second is the Macbook.