 tevador
commented
5 years ago
tevador
commented
5 years ago All 16 SSE registers are currently occupied for floating point math, so there is no room to add CLMUL support without reducing floating point.
The main program loop of RandomX uses only basic operations that are common in all 64 bit CPUs including ARMv8.
From the list of extensions, only SSE2 and AES-NI are used at the moment (AES-NI only during scratchpad init/hash steps).
 Gingeropolous
Gingeropolous
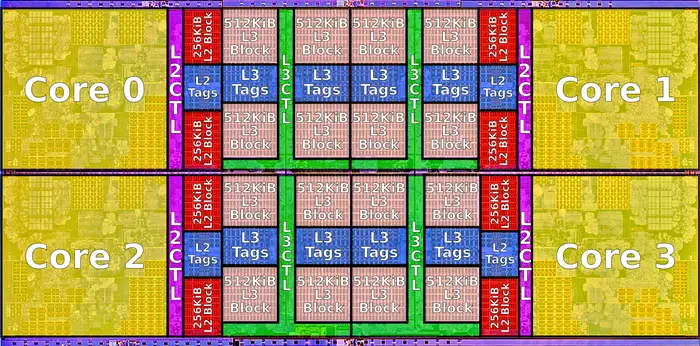
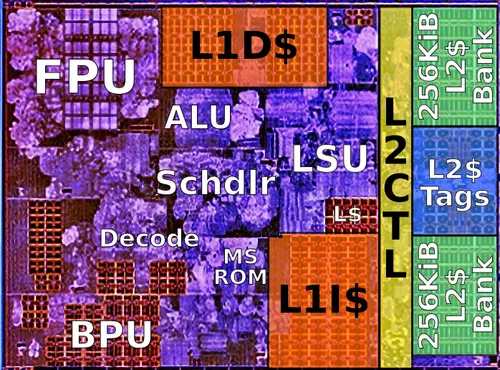
So in the effort to reduce the gap between a consumer CPU and a custom CPU, one approach is exploiting some of the stuff baked in to modern CPUs. This probably just buys us time, similar to the AES-NI of cryptonight.
For instance, does randomX do things that take advantage of
CLMUL instruction set
or any of the things on the extension list?
https://en.wikipedia.org/wiki/Kaby_Lake