 ddecatur
commented
1 week ago
ddecatur
commented
1 week ago Hi Terry, can you specify which of the demo commands is not working and show the results you get?
Closed Terry-Joy closed 4 days ago
ddecatur
commented
1 week ago Hi Terry, can you specify which of the demo commands is not working and show the results you get?
 Terry-Joy
commented
1 week ago
Terry-Joy
commented
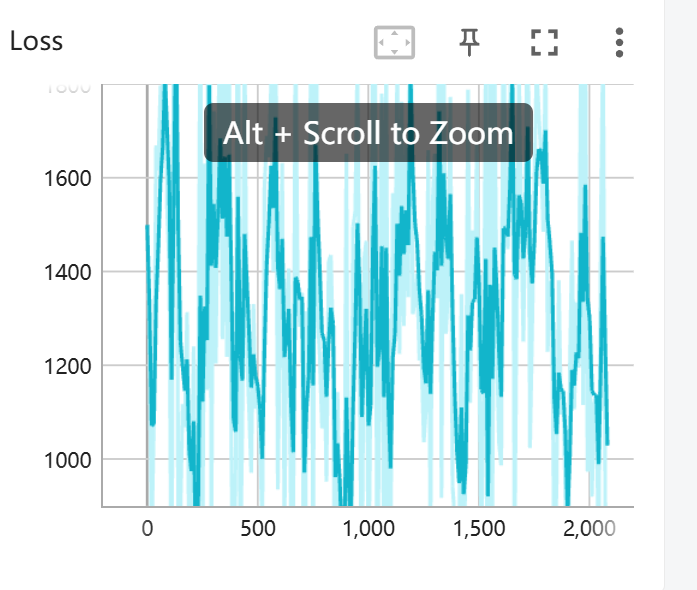
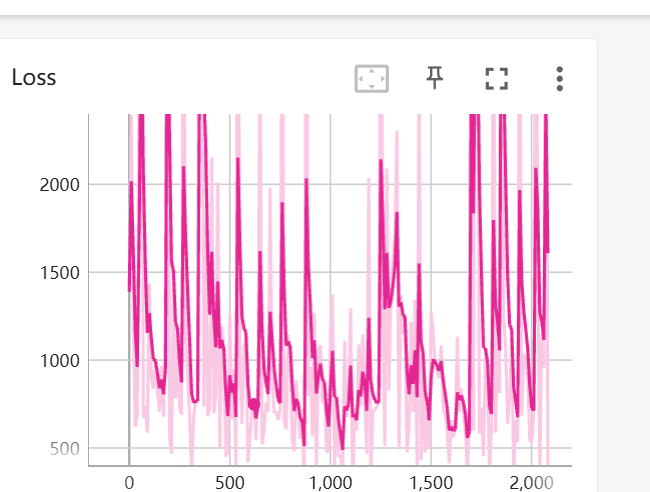
1 week ago I think it's a Great Work! Almost all commands in From Scratch, all my parameters and config are based on the repository, and even the training card is A40, which has not been changed. However, after training, I cannot achieve accurate local editing like your demo, and there are some small textures appearing in some places. May I ask if there are significant differences in the training parameters of different demos, rather than default values. In addition, according to the default configuration and parameters, the loss of the model cannot converge at all and cannot converge on all Scratches. I tried my best to tune it but it still cannot converge. Following is one of the result, can you help me solve these problems?

Terry-Joy
commented
1 week ago All command I trained just as default config, such as mlp_batch_size = 400000 and learning rate is 1e-4.
ddecatur
commented
1 week ago Thanks for the detailed info, I think I know how to fix your issue. During "inference" from our optimized neural fields, we perform thresholding on the localization value before masking the texture. This gives much cleaner results as it removes low confidence localization regions. I just locally ran the following command: python src/main.py --config_path demo/spot/gold_chain_necklace.yaml and without thresholding I get a very similar result to what you show:
However, if I then run the thresholding with a value of 0.7, I get a much cleaner result that matches what is shown in the video:
Due to compute constraints I only ran this for 3750 iterations, so the optimization could be a bit different at 5000 iterations, but I doubt it will change much. We actually automatically run this thresholding and inference at the end of the 5000 iteration optimization, but as I did here (and I assume you did too) I am stopping it early since otherwise the results were satisfactory. To manually run the thresholding on your most recent checkpoint, you can use the command: python src/main.py --config_path demo/spot/gold_chain_necklace.yaml --log.inference true --log.model_path ./results/spot/gold_chain_necklace/model.pth --log.inference_threshold 0.7 (this is how I ran the thresholding for the image above).
One more thing is that in checking out this issue, I noticed that the config for gold chain necklace does not overwrite the default thresholding value of 0.5 and to get the best results you should use 0.7 on this example. I will update the gold chain necklace config to use this value by default for the future.
As for the loss plots, I assume you are plotting the loss from SDS? If so, this will be very noisy as the loss is dependent on the sampled timestep (larger timesteps correspond to more noise so the loss will be higher) and in this work the sampled timesteps are independent from the optimization iteration steps. So I wouldn't rely too much on the loss, perhaps looking at the average loss over the last 150 iterations or so might be more informative.
Hope this solves your issue, but let me know if there is anything else I can help with!
Terry-Joy
commented
6 days ago Thanks a lot. Besides relying on the performance every 150 steps, if we don't depend on the loss, what other good methods or experiences do you have to evaluate the effectiveness of training?
ddecatur
commented
6 days ago Yeah, as you mentioned, manual visual inspection is typically best. If you want to use the loss as a signal, you can take the average loss over some sliding window. Another automated approach is to look at the CLIP similarity scores between the renders and text prompt, but this isn't very reliable as often CLIP scores don't align well with human preference.
Why can't I reproduce your demo? I followed your config to retrain the person detection model, but none of the results I got match the performance seen in your video.