 hadley
commented
6 years ago
hadley
commented
6 years ago Is the col1, col2, col3 format a typical source format, or is it some intermediate structure that you're created along the way?
Closed MaximeWack closed 5 years ago
hadley
commented
6 years ago Is the col1, col2, col3 format a typical source format, or is it some intermediate structure that you're created along the way?
 MaximeWack
commented
6 years ago
MaximeWack
commented
6 years ago Yes col{1-n} is a typical source format. It happens with this kind of input :
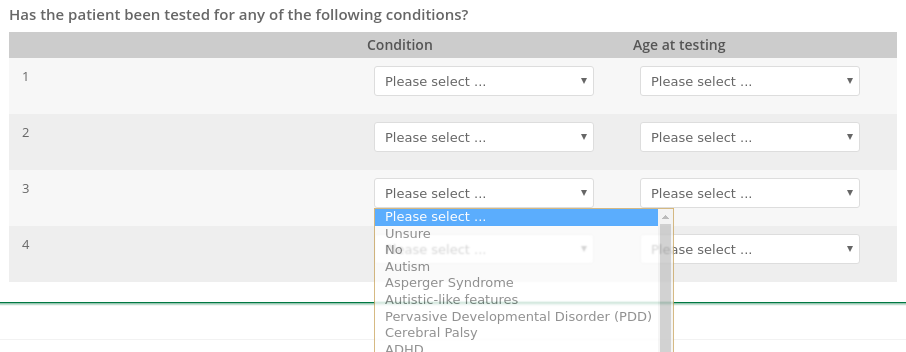
in which every drop menu has the same set of options.
This is indeed a very un-tidy way of recording data, but after encountering it in the wild for the third time I decided it was worth the effort of coding a generic function to handle it, and that it might interest other people.
 markdly
commented
6 years ago
markdly
commented
6 years ago @MaximeWack, I often encounter this type of data format for surveys and educational assessment data too. If you prefer to avoid a gather and spread type operation perhaps using nest and unnest() instead might be helpful in some situations:
library(tidyverse)
df <- tribble(
~id, ~col1, ~col2, ~col3,
1, "A", "B", "C",
2, "B", "C", NA,
3, "D", NA, NA,
4, "B", "D", NA)
x <- LETTERS[1:4]
df %>%
nest(-id) %>%
mutate(data = map(data, ~ bind_rows(setNames(x %in% unique(unlist(.)), x)))) %>%
unnest()
#> # A tibble: 4 x 5
#> id A B C D
#> <dbl> <lgl> <lgl> <lgl> <lgl>
#> 1 1 TRUE TRUE TRUE FALSE
#> 2 2 FALSE TRUE TRUE FALSE
#> 3 3 FALSE FALSE FALSE TRUE
#> 4 4 FALSE TRUE FALSE TRUEThis feels slightly too specialised to be worth including in tidyr. With the new pivot functions, it's fairly easily to solve in just three steps:
library(tidyr)
df <- tibble::tribble(
~id, ~col1, ~col2, ~col3,
1, "A", "B", "C",
2, "B", "C", NA,
3, "D", NA, NA,
4, "B", "D", NA
)
df %>%
pivot_long(-id, na.rm = TRUE) %>%
dplyr::count(id, value) %>%
pivot_wide(
names_from = value,
values_from = n,
values_fill = list(n = 0)
)
#> # A tibble: 4 x 5
#> id A B C D
#> <dbl> <int> <int> <int> <int>
#> 1 1 1 1 1 0
#> 2 2 0 1 1 0
#> 3 3 0 0 0 1
#> 4 4 0 1 0 1Created on 2019-03-07 by the reprex package (v0.2.1.9000)
I'll include this as an example in the new pivot vignette.
I'd like to see a function which would turn a ragged array to a sparse one, usually when a "factor" with non-mutually exclusive choices is tentatively recorded using a group of drop-downs.
For example, if you have such a "factor" with legal values
A/B/C/Drecorded over three variablescol1,col2andcol3.calling such a function, indicating that
col1,col2andcol3are encoding for the same information, would yieldOptions would include the ability to set a prefix for the new variable names to avoid collisions, and to create the
NAcolumn.I found this use case many times in medical surveys where disease history is badly recorded using multiple drop-down lists or sets of checkboxes. IIRC, google surveys also treats sets of checkboxes this way, with one column containing semi-colon separated values. This can be dealt with using a call to
separatethen a call tobinarize.Playing around a bit with
spreadandgatherallows this behavior but this can be CPU/memory heavy on large dataframes.There is a (pre-tidyeval) implementation in PR #288