 GreaterFire
commented
7 years ago
GreaterFire
commented
7 years ago Also, I want to emphasize that, with the help of TLS, the anti-active-probing mechanism that trojan adopts is unbreakable.
Regarding multiplexing, I think it's better up to the underlying protocol to decide whether to terminate a connection. HTTP has its own Keep Alive scheme which can
- Raise performance, and
- Make the traffic looks more like
HTTPS.
I don't recommend using multiplexing because it seems that GFW closes long TLS connections.
 ytgui
ytgui klzgrad
klzgrad Akkariiin
Akkariiin
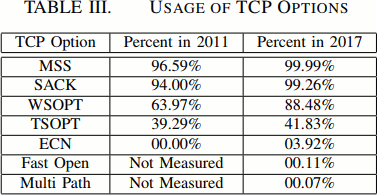
I would like to invite you to the discussion of the rationales and ideas for a better circumvention protocol.
Many of the points below can have better context with citations but I try to keep it informal this time.
Why use TLS
Security
The Shadowsocks specification has been reinventing cryptography to make up for apparent vulnerabilities from various probing attacks. It among other similar protocols try to recommend specific cipher suites and cryptographic configurations without professional analysis and audit. The fact that the Shadowsocks spec was fixed again and again with faulty cryptographic designs shows how hard it is to reinvent cryptography and why obfuscation is not possible without certain level of security.
This subject has been much better researched and engineered for years as TLS. TLS provides confidentiality, authentication, and integrity. It protects against replay attack. It has mature and high performance and cross-platform implementations. It is only sensible to adopt commonly used best practices. Those who do not understand TLS are doomed to reinvent it, poorly.
Obfuscation
What Shadowsocks is doing is no different from Tor's pluggable transports, e.g. ScrambleSuit and obfs4, which have designed custom cryptographic protocols to replace Tor's default TLS stack, except that Tor's protocols are scholarly peer-reviewed.
The assumption of these Tor PT protocols is that if the wire data look as random as possible (above the transport layer) it would be impossible to identify or classify. This assumption has its limitation. It is shown that random packet padding actually becomes a feature in itself and enables new entropy-based attacks.
The bigger picture is that most traffic on the Internet does not look random. If an obfuscation protocol makes the data too random it attracts additional scrutiny. A thought experiment: the GFW intercepts 60% HTTP, 30% TLS, and 10% unrecognized high-entropy traffic. After the initial coarse traffic classification, the 10% traffic gets redirected for additional analysis, where more advanced methods become affordable.
The obvious solution is to obfuscate above the transport layer inside real TLS. By moving the protocol up the layer, traffic classification at the transport layer is less effective and the obfuscated traffic is less likely to be scrutinized by being of a larger traffic class. (Note that it must be real TLS. Mimicry of HTTP (or TLS) has been shown to be easily detected.) I think this is part of the reason Meek (plain HTTPS proxy with fake TLS SNI) is given more attention at Tor. As more traffic moves to TLS this effect becomes more pronounced.
Problems of TLS
Information leak
TLS is much more complex than TCP and give off much more information, mostly in TLS parameters in ClientHello and ServerHello, state transition, and certificates.
In principles these protocol behaviors can be imitated perfectly by reusing a browser's TLS stack and it is easy to verify the imitation locally.
GFW people have proposed to prioritize traffic for more advanced analysis by a "trustworthiness" ranking of the certificates. This is essentially network-layer host behavior analysis applied at the TLS layer and the certificates are the new IP addresses. Indeed IP addresses can also have "trustworthiness" used to prioritize traffic for analysis, e.g. if 99% traffic of a foreign host is with a single domestic host, select it for advanced tunnel traffic classifiers; well-known IP addresses are whitelisted, etc.
Traffic selection is always happening and it's a matter of degree of uniqueness of the certificates. In this sense CA-signed certificates (Let's Encrypt) can be even more unique than self-signed certificates because the former may represent less traffic than the latter. There are no clear wrong options here for circumvention but the choice of best practice remains an open question.
Performance
TLS handshakes introduce additional RTT on top of TCP handshakes. Latency is critical for network performance.
The Shadowsocks protocol has no handshakes and its implementation uses TCP Fast Open which reduces even more handshake RTT. Although TCP Fast Open is not always usable as it is commonly obstructed by middleboxes.
Speaking of RTT, VPNs at the network layer would have the least RTT among proxy schemes, but VPNs' usability is harmed by its requirement to configure the OS network stack. In this sense Shadowsocks' success is partly due to the fact that it requires little sysadmin work which is a reasonable tradeoff for TCP handshake RTT.
There are remedies in TLS for the RTT problem. TLS 1.2 False Start extension reduces handshakes to 1-RTT. TLS 1.3 (draft) introduces a 0-RTT mode. But TLS 1.3 implementations are still not production-ready to match the 0-RTT performance in Shadowsocks protocol (I tried Chromium/BoringSSL, Nginx. Though HAProxy just put out 0-RTT support in 1.8-rc3, I was working with Nginx because it's easier for scripting. I hope I can get them working soon.)
About TCP Fast Open, I found neither Nginx nor HAProxy has implemented it in client mode. Nginx gave an interesting reason: it's better to use persistent connections instead of creating new connections very fast. Shadowsocks creates a new proxy connection for each client request. It is arguable whether multiplexing would be better than that for Shadowsocks, but the benefit is obvious in the case of TLS where the cost of creating new connections is high.
There are two schemes of multiplexing: one is multiplexing multiple streams into a single TCP connection, the other is connection reuse/connection pooling. Mux.Cool used by V2Ray is of the first scheme. The first scheme has a head-of-line blocking problem which increases latency, see this. The second one is used by Nginx as "keepalives." It works like this: For a new client connection, try to use an idle proxy connection in the pool or create a new connection; after the client connection is closed, do not close the proxy connection instead save it into the pool as idle (with an idle timeout).
The Shadowsocks protocol does not allow multiplexing because it cannot distinguish the start and end of streams. Neither does the Trojan protocol but Trojan can be extended to allow this enhancement. To enable multiplexing the protocol can use a similar scheme as HTTP chunked transfer encoding:
Traffic analysis
I agree this is a legitimate threat and deserves attention. There has been a report of a specific TLS-in-TLS proxy being repeatably detected by traffic analysis, but at the same time GFW people have also admitted the limitation of practical traffic analysis (classifiers do not generalize, concept drift, etc.).
The difficulty at the circumvention side is that there is no way to verify the effectiveness of any proposed traffic obfuscation technique in real-world setting and similarly there is no way to compare their relative effectiveness.
Despite the theoretical trouble I think the current recommendation is to implement any basic packet padding scheme, which will be always better than no padding. More adversarial implementations of detectors of traffic obfuscators may prove useful in measuring the strength of them.
Other rationales
@GreaterFire @micooz @WANG-lp @bosskwei @wongsyrone