 iron3oxide
commented
1 year ago
iron3oxide
commented
1 year ago Small update on this: template routes are now integrated into the library, which was one of the main inhibiting factors. The next big one to tackle is that views don't receive a uniform set of parameters (excluding route parameters of course).
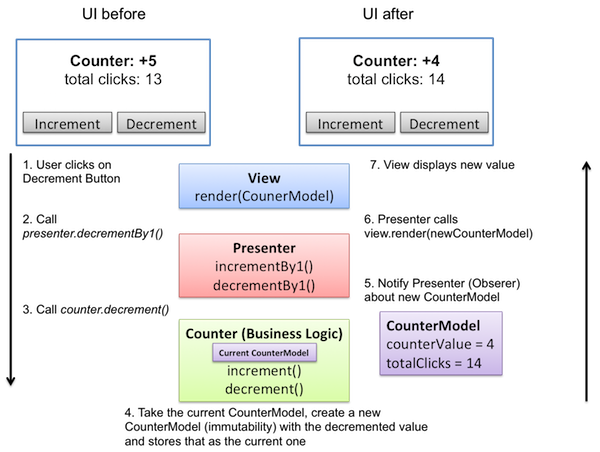
Since every one of the varying parameters (including TuttleParams) seems to be some member of the TuttleApp and each ViewBuilder in the library will automatically receive the RoutedApp as an attribute when it is added to said app, I suggest a refactor which would move the responsibility of passing app attributes/methods to the respective view into the build_view method of a custom TuttleViewBuilder class that inherits from the abstract ViewBuilder class.
This would either mean adding something like on_theme_change to TuttleParams as an optional attribute or creating a separate ViewBuilder implementation for each view that requires special parameters. Which one would you prefer?
 vlad-ed-git
vlad-ed-git clstaudt
clstaudt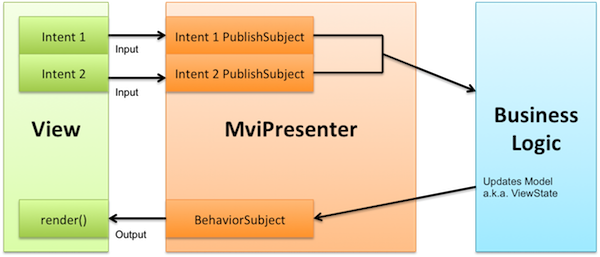{kind=link}
{kind=link}
Since less (boilerplate) code and standardization should be aimed for, especially when it comes to routing, it might be worthwhile to refactor the app directory a bit in order to use the flet-routed-app library. Being the maintainer of said library, I will adapt it to the needs of tuttle wherever necessary.