 github-actions[bot]
commented
4 years ago
github-actions[bot]
commented
4 years ago Hello @seekFire, thank you for your interest in our work! Please visit our Custom Training Tutorial to get started, and see our Jupyter Notebook ![]() , Docker Image, and Google Cloud Quickstart Guide for example environments.
, Docker Image, and Google Cloud Quickstart Guide for example environments.
If this is a bug report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you.
If this is a custom model or data training question, please note that Ultralytics does not provide free personal support. As a leader in vision ML and AI, we do offer professional consulting, from simple expert advice up to delivery of fully customized, end-to-end production solutions for our clients, such as:
- Cloud-based AI systems operating on hundreds of HD video streams in realtime.
- Edge AI integrated into custom iOS and Android apps for realtime 30 FPS video inference.
- Custom data training, hyperparameter evolution, and model exportation to any destination.
For more information please visit https://www.ultralytics.com.
 glenn-jocher
glenn-jocher TaoXieSZ
TaoXieSZ seekFire
seekFire bretagne-peiqi
bretagne-peiqi
 gaobaorong
gaobaorong pravastacaraka
pravastacaraka zhiqwang
zhiqwang
 ehdrndd
ehdrndd
 data4pass
data4pass Zengyf-CVer
Zengyf-CVer yyccR
yyccR
 myasser63
myasser63 joangog
joangog Liqq1
Liqq1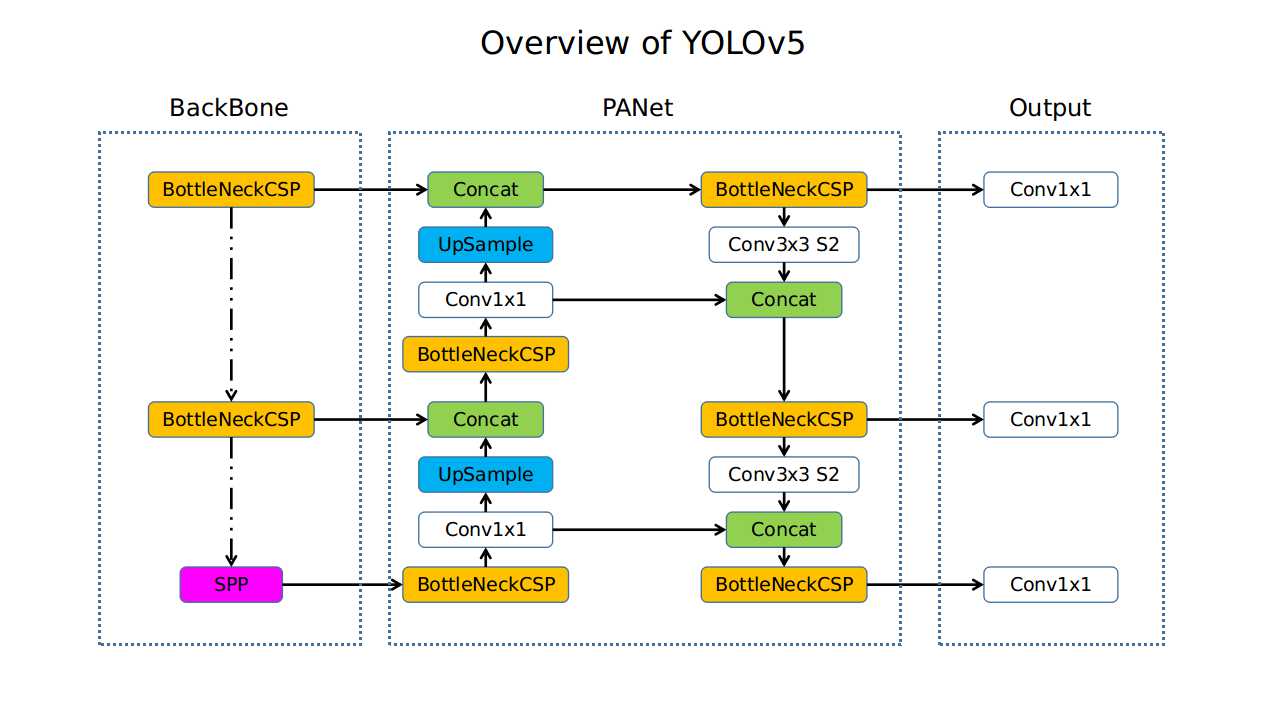
 wwdok
wwdok
 imdadulhaque1
imdadulhaque1 jeannotdamoiseaux
jeannotdamoiseaux



 joonjeon
joonjeon sweetygupta17
sweetygupta17 Symbadian
Symbadian
 QiangYanHuang
QiangYanHuang
In order to understand the structure of YOLOv5 and use other frameworks to implement YOLOv5, I try to create an overview, as shown below. If there has any error, please point out