 glenn-jocher
commented
3 years ago
glenn-jocher
commented
3 years ago @mikecr96 hey buddy, there's actually a better solution that creates a YOLOv5 TF2/Keras model from scratch, transfers over the PyTorch weights, and then exports to TFLite in PR https://github.com/ultralytics/yolov5/pull/1127
 mikecr96
mikecr96
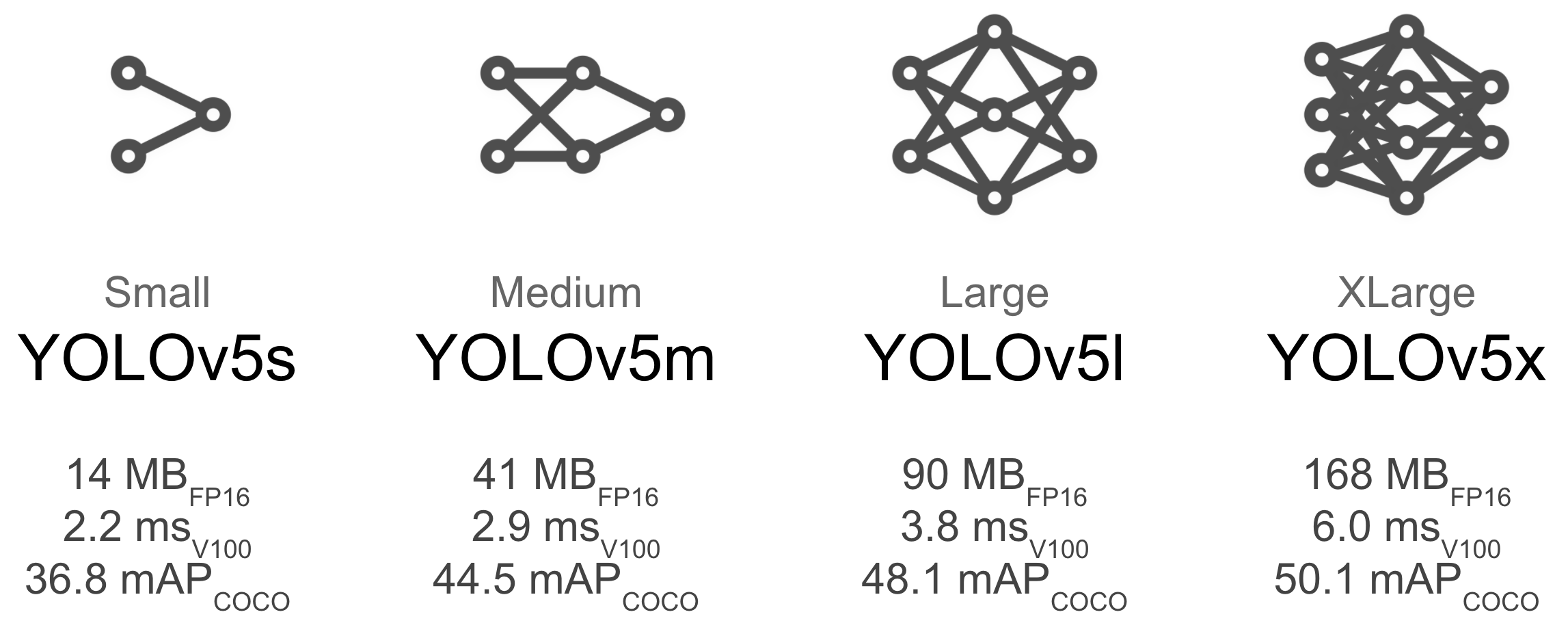


 Running my model using 5s for training but converted to tflite using PR #1127 (FP16):
Running my model using 5s for training but converted to tflite using PR #1127 (FP16):
 Running my model using 5s for training but converted to tflite using PR #1127 (int8):
Running my model using 5s for training but converted to tflite using PR #1127 (int8):

 github-actions[bot]
github-actions[bot] zldrobit
zldrobit
🚀 Feature
models/export.pycurrently export pt models to onnx and other formats. Since convert from onnx to tflite is possible, I guess it should be easy to implement onnx to tflite conversion and/or to keras model.Motivation
I'm trying yolov5 on a Raspberry Pi 4 Model B (4GB RAM). Actually it works fine but slow so I want to try to make yolo works with tflite in order to make inference a little bit faster on ARM processor(s).
Pitch
Whether to just export to tflite model or add official support to yolo to works with tflite models (I guess this should be harder).