 glenn-jocher
commented
2 years ago
glenn-jocher
commented
2 years ago @DP1701 your error message clearly states RuntimeError: CUDA error: out of memory.
YOLOv5 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the nvidia-smi command or by viewing your console output:

CUDA Out of Memory Solutions
If you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
- Reduce
--batch-size - Reduce
--img-size - Reduce model size, i.e. from YOLOv5x -> YOLOv5l -> YOLOv5m -> YOLOv5s > YOLOv5n
- Train with multi-GPU at the same
--batch-size - Upgrade your hardware to a larger GPU
- Train on free GPU backends with up to 16GB of CUDA memory:


AutoBatch
You can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing --batch-size -1. AutoBatch will solve for a 90% CUDA memory-utilization batch-size given your training settings. AutoBatch is experimental, and only works for Single-GPU training. It may not work on all systems, and is not recommended for production use.
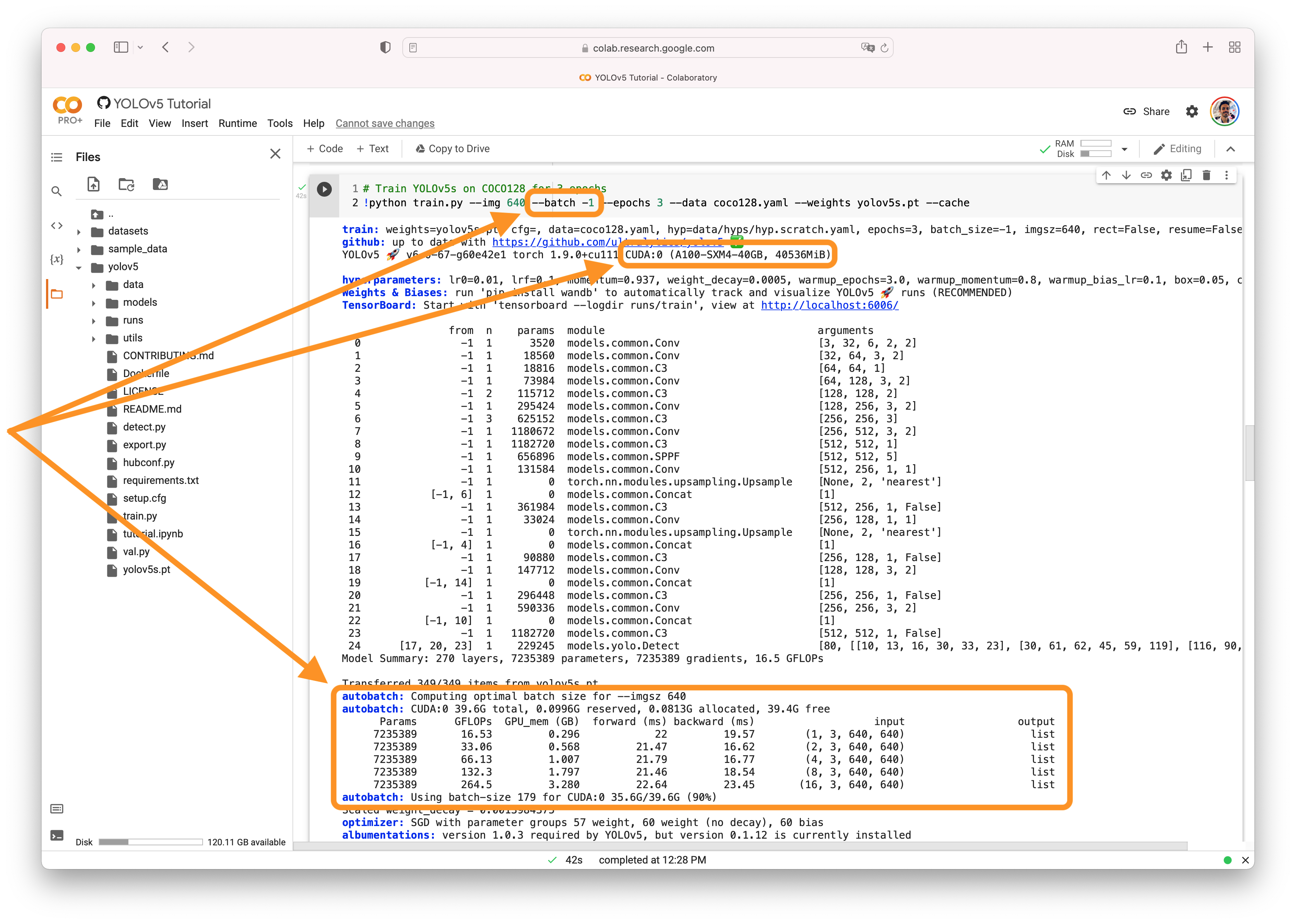
Good luck 🍀 and let us know if you have any other questions!
 DP1701
DP1701
 Symbadian
Symbadian
Search before asking
YOLOv5 Component
Training
Bug
Training does not take place if the --multi-scale option is activated. Stops directly in the first epoch at the beginning.
YOLOv5 🚀 v6.1-170-gbff6e51 torch 1.11.0+cu113 CUDA:0 (A100-SXM4-40GB, 40537MiB) Python 3.8.10
pip list
Package Version
absl-py 1.0.0
albumentations 1.1.0
cachetools 4.2.4
certifi 2021.10.8
charset-normalizer 2.0.9
cycler 0.11.0
fonttools 4.28.3
google-auth 2.3.3
google-auth-oauthlib 0.4.6
grpcio 1.42.0
idna 3.3
imageio 2.13.3
importlib-metadata 4.8.2
joblib 1.1.0
kiwisolver 1.3.2
Markdown 3.3.6
matplotlib 3.5.1
networkx 2.6.3
numpy 1.21.4
oauthlib 3.1.1
opencv-python 4.5.4.60
opencv-python-headless 4.5.4.60
packaging 21.3
pandas 1.3.5
Pillow 8.4.0
pip 20.0.2
pkg-resources 0.0.0
protobuf 3.19.1
pyasn1 0.4.8
pyasn1-modules 0.2.8
pyparsing 3.0.6
python-dateutil 2.8.2
pytz 2021.3
PyWavelets 1.2.0
PyYAML 6.0
qudida 0.0.4
requests 2.26.0
requests-oauthlib 1.3.0
rsa 4.8
scikit-image 0.19.0
scikit-learn 1.0.1
scipy 1.7.3
seaborn 0.11.2
setuptools 44.0.0
six 1.16.0
tensorboard 2.7.0
tensorboard-data-server 0.6.1
tensorboard-plugin-wit 1.8.0
thop 0.0.31.post2005241907 threadpoolctl 3.0.0
tifffile 2021.11.2
torch 1.11.0+cu113
torchaudio 0.11.0+cu113
torchvision 0.12.0+cu113
tqdm 4.62.3
typing-extensions 4.0.1
urllib3 1.26.7
Werkzeug 2.0.2
wheel 0.37.0
zipp 3.6.0
nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2022 NVIDIA Corporation Built on Thu_Feb_10_18:23:41_PST_2022 Cuda compilation tools, release 11.6, V11.6.112 Build cuda_11.6.r11.6/compiler.30978841_0
Ubuntu 20.04.3 LTS