 glenn-jocher
commented
2 years ago
glenn-jocher
commented
2 years ago 👋 Hello! Thanks for asking about inference speed issues. PyTorch Hub speeds will vary by hardware, software, model, inference settings, etc. Our default example in Colab with a V100 looks like this:
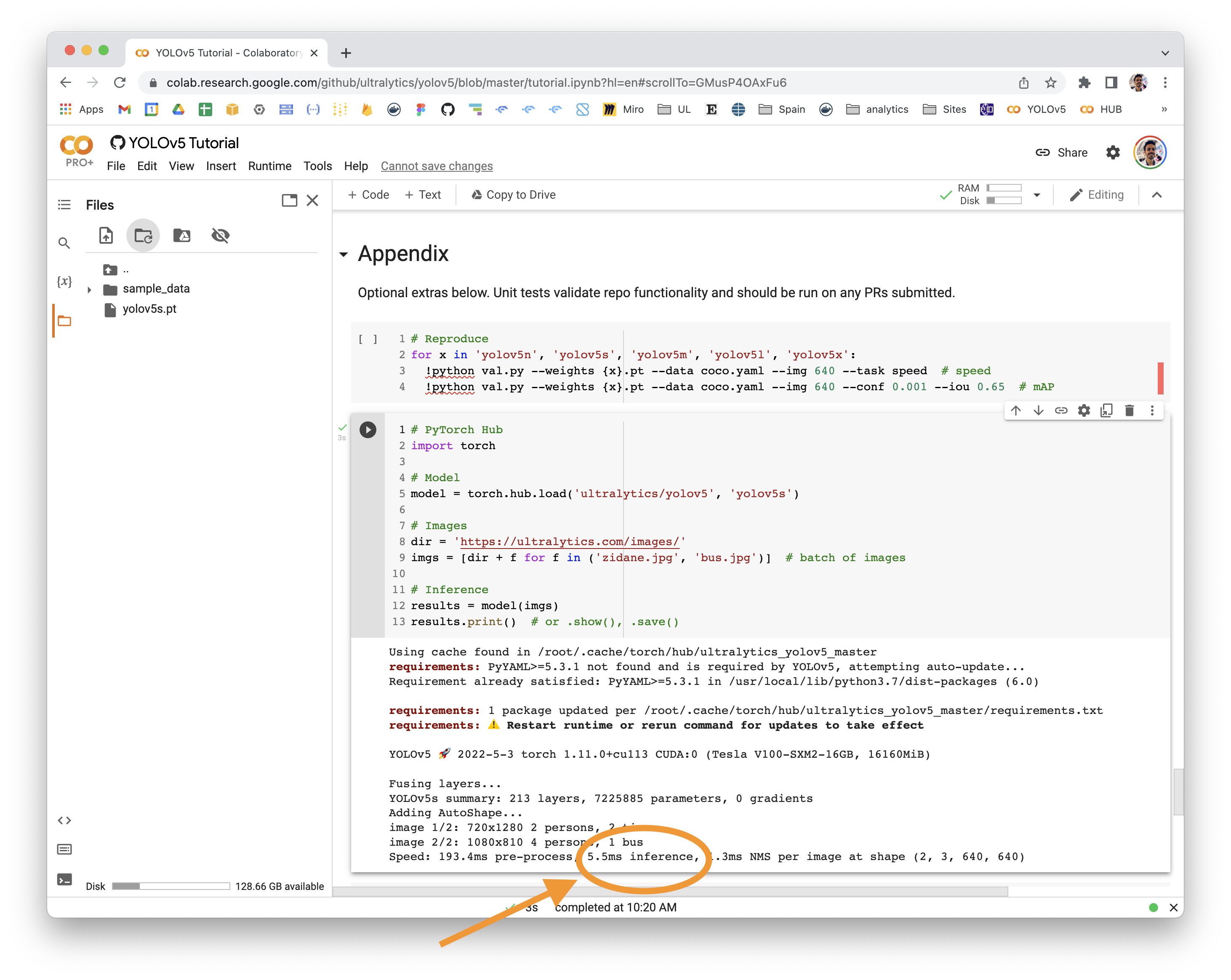
YOLOv5 🚀 can be run on CPU (i.e. --device cpu, slow) or GPU if available (i.e. --device 0, faster). You can determine your inference device by viewing the YOLOv5 console output:
detect.py inference
python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images/
YOLOv5 PyTorch Hub inference
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# Images
dir = 'https://ultralytics.com/images/'
imgs = [dir + f for f in ('zidane.jpg', 'bus.jpg')] # batch of images
# Inference
results = model(imgs)
results.print() # or .show(), .save()
# Speed: 631.5ms pre-process, 19.2ms inference, 1.6ms NMS per image at shape (2, 3, 640, 640)Increase Speeds
If you would like to increase your inference speed some options are:
- Use batched inference with YOLOv5 PyTorch Hub
- Reduce
--img-size, i.e. 1280 -> 640 -> 320 - Reduce model size, i.e. YOLOv5x -> YOLOv5l -> YOLOv5m -> YOLOv5s -> YOLOv5n
- Use half precision FP16 inference with
python detect.py --halfandpython val.py --half - Use a faster GPUs, i.e.: P100 -> V100 -> A100
- Export to ONNX or OpenVINO for up to 3x CPU speedup (CPU Benchmarks)
- Export to TensorRT for up to 5x GPU speedup (GPU Benchmarks)
- Use a free GPU backends with up to 16GB of CUDA memory:


Good luck 🍀 and let us know if you have any other questions!
 dnth
dnth github-actions[bot]
github-actions[bot] marcortiz11
marcortiz11 AbdelsalamHaa
AbdelsalamHaa apanand14
apanand14
Search before asking
Question
Can anyone suggest how can I speed up program since I am using cpu and no gpu, it takes lot of time so are there any other module which can help code to speed up @glenn-jocher ???
Additional
No response