 barryWhiteHat
commented
4 years ago
barryWhiteHat
commented
4 years ago Semphore currently uses blake2 hash function (quantum forward secracy) and pedersen hash (harden mimc collision resistant) we also use eddsa signature for similar crypto UX, this could be replaced with knoledge of preimage as signature.
An example minimal circuit that is lacking the quantum forward secrecy is https://github.com/peppersec/tornado-mixer/ its possibly a better benchmark candidate.
You would need to add shamir secret share of the leaf but that is for both.
 mmaller
mmaller kobigurk
kobigurk mratsim
mratsim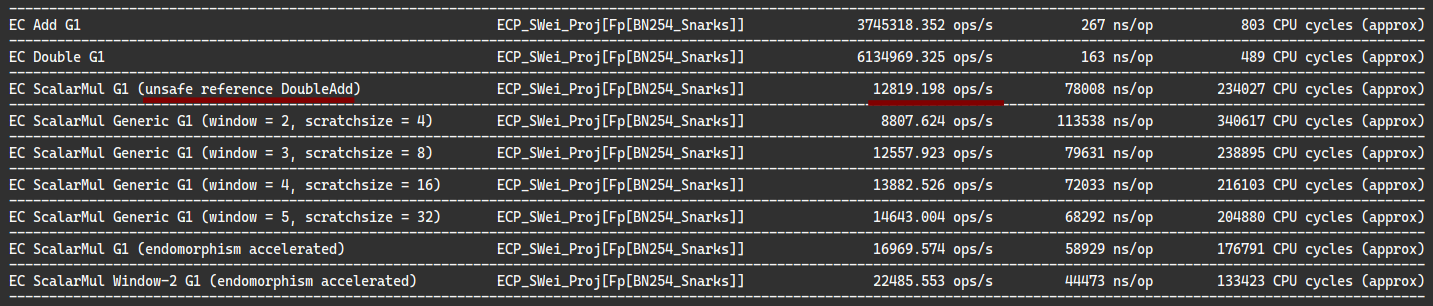

 According to Aranha2010 (which has more operations than Grewal2012) this already saves 2.5x multiplications
According to Aranha2010 (which has more operations than Grewal2012) this already saves 2.5x multiplications 

 oskarth
oskarth jacqueswww
jacqueswww
 cammellos
cammellos kilic
kilic jon-chuang
jon-chuang
Problem
Prove time for Semaphore (https://github.com/kobigurk/semaphore) zKSNARKs using circom, groth and snarkjs is currently way too long. It takes on the order of ~10m to generate a proof. With Websnark, it is likely to take 30s, which might still be too long. We should experiment with native code on mobile here.
Acceptance criteria
While we can potentially use precomputed proofs to some extent, this needs to be on the order of a seconds to be feasible for e.g. spam protection signalling normal messages. This means a performance improvement of a bit more than two orders of magnitude is necessary. Alternatively, perf can be a bit less if we get precomputed proofs and batching to work smoothly.
Details
See https://github.com/vacp2p/research/blob/master/zksnarks/semaphore/src/hello.js#L118 for proof generation. This is using snarkjs, circom and running through Node, which is likely one of the slower environments. Additionally, number of constraints for the snark are around ~60k.
Reducing the problem to a simpler circuit (Pedersen commitment, 5 rounds), see https://ethresear.ch/t/benchmark-circom-vs-bellman-wasm-in-chrome-on-mobile/5261, we note the previous benchmarks of Circom and Bellman in different environments such as Node/WASM/Native:
I.e. wasm 50x faster, and native 500x faster. There appears to be WIP and room for improvement for the wasm benchmarks.
Circom and Bellman both have around ~3.5k constraints, i.e. 5% of our original snark.
For our initial problem, this would mean roughly:
3.5k -> 60k; 20x constraints
=> node ~15m => wasm ~30s => native ~2s
Possible solutions
1. Use a better environment (WASM or native).
No-brainer. Either use Websnarks with existing Circom snarks or Bellman to WASM.
WASM might not be enough though, especially to get to subsecond, and requires more optimization.
Native would be useful, especially for resource restricted devices and for spam protection. Additional benchmarks on mobile would be good to have. A big issue is in terms of deployment - currently native would mean something like Bellman, which right now doesn't have a library like Circom for writing SNARKs. This seems to be an ongoing effort:
2. Decrease number of constraints.
60k could possible be reduce quite a lot, but require additional research (e.g. merkle tree structure, number of rounds for various hash functions, etc). If this could be halved, then Webnarks might be enough.
3. Use a different type of ZKP
Other types of ZKP come with lower proof time, but with other trade offs (such as proof size). The main reasons to explore this would, from my current POV, be related to: proof time; security assumptions (cryptographic assumptions and trusted setup); and proof time.
4. Precompute proofs
It's possible we can precompute proofs for e.g. spam protection. This means you can instantly signal, and then 'save up' messages. How this would work in practice requires further research.
5. Prover as a service?
I don't know what this would look like, but perhaps proof generation could be outsourced. This appears to be STARKware business model if I understand it correctly: https://starkware.co/the-road-ahead-in-2019/
6. Batching of signals
A bit similar to 'precompute case', but it might be doable to take many messages in a 30s period and batch them together. In the human chat case, this would impact UX. Worth exploring though.
Note
The benchmark in problem descrption and ethresear.ch might be incorrect, so worth checking them again.