 praiskup
commented
8 years ago
praiskup
commented
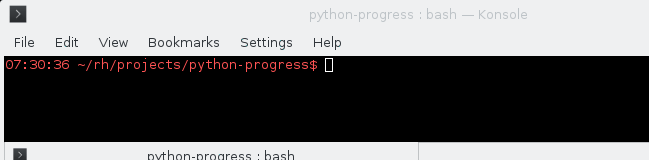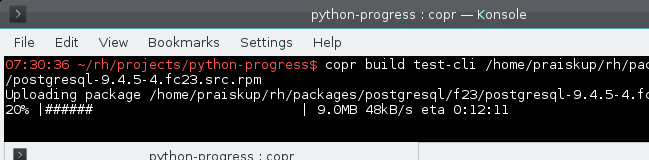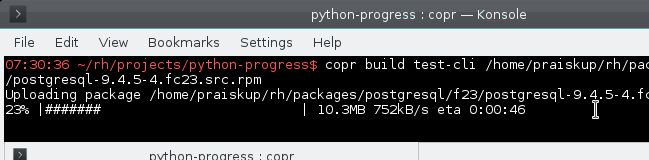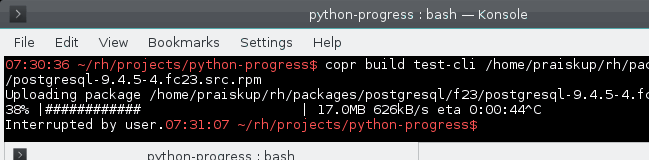
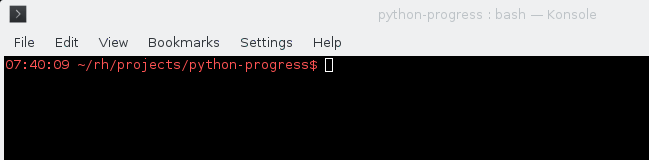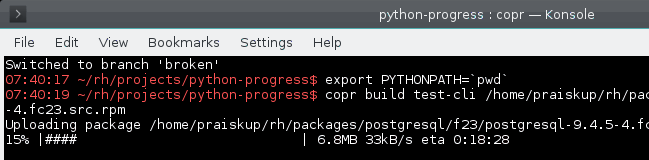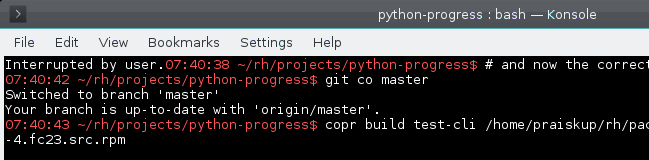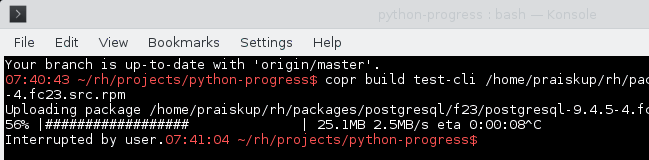
8 years ago The algorithm was not changed by this PR. The problem is that the "old" implementation works with incredibly small float numbers, doing their sum and dividing ... which makes it very inaccurate. image
The code that uses it: https://git.fedorahosted.org/cgit/copr.git/tree/cli/copr_cli/main.py?id=15116133574defe50#n165
 verigak
verigak saxtouri
saxtouri{kind=link}
{kind=link}
{kind=link}
Follow up for verigak/progress/pull/23