vikrant7
commented
5 years ago
vikrant7
commented
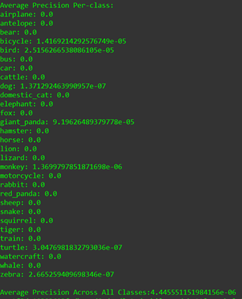
5 years ago Hi @Enlistedman , The model in models/lstm5/WM-1.0-test.pth is just an untrained model saved to verify my code. Sorry for the confusion, I will remove this files. Also please wait for few days as training is still going on, I will update README once it is done.
 Enlistedman
Enlistedman
Hello,I tested the model on ILSVRC2015 using the models/lstm5/WM-1.0-test.pth you provided, but each time the scores and boxes are the same value, the final result is very poor, can you provide the corresponding help? thank you very much.