 vinhnd20
commented
3 months ago
vinhnd20
commented
3 months ago Đặt vấn đề và đưa ra phương án giải quyết vấn đề. Cần phải có minh chứng, thử nghiệm.
Open vinhnd20 opened 3 months ago
vinhnd20
commented
3 months ago Đặt vấn đề và đưa ra phương án giải quyết vấn đề. Cần phải có minh chứng, thử nghiệm.
vinhnd20
commented
3 months ago Trước đoạn cuối trong Introduction thì nêu rõ vấn đề. Đoạn cuối thì đề xúât giải pháp.
vinhnd20
commented
3 months ago Thứ 7 gửi thầy đến phần intro
 crvt4722
commented
3 months ago
crvt4722
commented
3 months ago Database as a Service (DBaaS) is a cloud computing service that allows users to access, manage, and utilize a cloud-based database system without having to purchase, install, configure hardware or software, and set up a management environment for operating the database on their systems (not to mention the real estate costs to provide space for hardware equipment). However, ensuring that user data is always safe and reliable even in the event of a database failure is a persistent issue for major cloud providers today. In this paper, we will explore a new advancement in the deployment of database services using the open-source OpenStack Trove, focusing on the Semi-Synchronous Replication Database Cluster deployment model and the automated disaster recovery feature (High Availability), ensuring that user data is lossless.
Keywords: DBaaS, OpenStack, Semisynchronous replication, High Availability, Disaster recovery, Data loss
Data loss on databases can truly be a nightmare for any business, as every bit of data could decide the success or failure of a business campaign or a project. Therefore, ensuring reliability, and high availability for databases is always a top priority in most enterprises. In recent years, DBaaS (Database as a Service) has become more popular than ever, offering a flexible and efficient approach to managing and operating databases. Additionally, many open-source solutions have been developed to help developers deploy DBaaS to their users, notably OpenStack Trove. OpenStack Trove is a key to deploying DBaaS with a robust cloud infrastructure and flexible data management features. However, despite offering data replication solutions, it still has limitations in ensuring the highest reliability and availability for the system. That's why we are looking towards a more advanced solution.
In this presentation, we will introduce a new step in providing database services using OpenStack Trove. We will delve into the Semi-Synchronous Replication and High Availability Cluster models, and discuss how to effectively implement them on OpenStack Trove. This solution not only enhances reliability but also increases availability, ensuring data is not lost in the event of system failures. Additionally, it can be deployed across multiple zones or regions, supporting Disaster Recovery for your database system.
OpenStack is an open-source cloud computing platform capable of supporting both public clouds and private clouds. This platform provides users with a scalable cloud computing infrastructure solution with many outstanding features.
Below is the basic architecture for deploying cloud computing services on OpenStack.
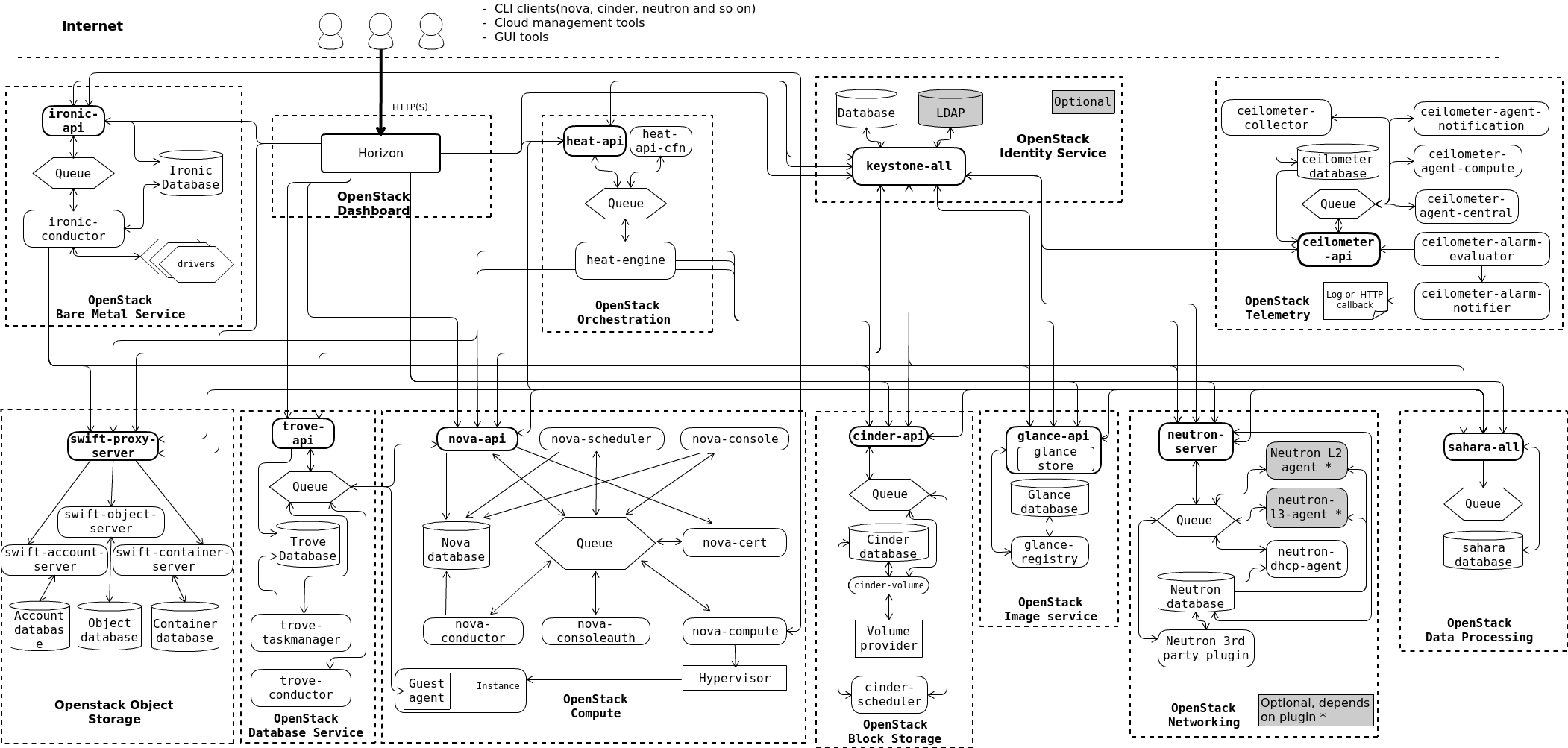
Below is the explanation of these components of the OpenStack architecture:
This architecture outlines the fundamental components and their interactions within an OpenStack deployment, offering a robust and flexible cloud infrastructure.
Trove is Database as a Service for OpenStack. It's designed to run entirely on OpenStack, with the goal of allowing users to quickly and easily utilize the features of a relational or non-relational database without the burden of handling complex administrative tasks. Cloud users and database administrators can provision and manage multiple database instances as needed. Initially, the service will focus on providing resource isolation at high performance while automating complex administrative tasks including deployment, configuration, patching, backups, restores, and monitoring.
Below is the architecture of the components of OpenStack Trove.

In addition to the basic components for deploying the OpenStack infrastructure layer (Nova, Cinder, Swift, Glance, Neutron, Keystone), OpenStack Trove has additional specific components to be able to deploy and operate the Database as a Service, including:
Currently, Trove provides data replication features for the types of databases it supports. However, its current model is Asynchronous Replication. Therefore, replication latency can occur during data synchronization between nodes, which can lead to data loss if the database system encounters an issue.
Database replication by default is asynchronous. The source writes events to its binary log or WAL and replicas request them when they are ready. The source does not know whether or when a replica has retrieved and processed the transactions, and there is no guarantee that any event ever reaches any replica. With asynchronous replication, if the source crashes, transactions that it has committed might not have been transmitted to any replica. Failover from source to replica in this case might result in failover to a server that is missing transactions relative to the source.

With fully synchronous replication, when a source commits a transaction, all replicas have also committed the transaction before the source returns to the session that performed the transaction. Fully synchronous replication means failover from the source to any replica is possible at any time. The drawback of fully synchronous replication is that there might be a lot of delay to complete a transaction.
Semisynchronous replication falls between asynchronous and fully synchronous replication. The source waits until at least one replica has received and logged the events (the required number of replicas is configurable), and then commits the transaction. The source does not wait for all replicas to acknowledge receipt, and it requires only an acknowledgement from the replicas, not that the events have been fully executed and committed on the replica side. Semisynchronous replication therefore guarantees that if the source crashes, all the transactions that it has committed have been transmitted to at least one replica.
Compared to asynchronous replication, semisynchronous replication provides improved data integrity, because when a commit returns successfully, it is known that the data exists in at least two places. Until a semisynchronous source receives acknowledgment from the required number of replicas, the transaction is on hold and not committed.
Compared to fully synchronous replication, semisynchronous replication is faster, because it can be configured to balance your requirements for data integrity (the number of replicas acknowledging receipt of the transaction) with the speed of commits, which are slower due to the need to wait for replicas.

We have deployed an Enterprise Database cluster on 3 nodes configured with Semisynchronous replication, where one node is designated as the master: responsible for the primary read/write operations from the users. The other 2 nodes act as slave nodes: they can be used for read operations from the users and play a crucial role in ensuring that if a failure occurs on the master node, the system can continue to operate by switching over to one of the slave nodes.

In a distributed database system, ensuring high availability and fault tolerance is crucial for maintaining seamless operations. Failover processes are an integral part of this system, allowing the database cluster to continue functioning smoothly even in the event of a node failure.
This part outlines the steps involved in performing a failover in case of the master node is crashed, ensuring that the most up-to-date replica is promoted to master status and the cluster is restored to normal operation without any data loss. Steps to follow are described below:
After completing these steps, the cluster will return to normal operation, ensuring no data loss during the failover process.
In addition to handling the case of a master node failure, dealing with failed replicas is also crucial for ensuring the cluster's stability. The steps to handle a failed replica are described below:
Note that in the case of a single replica node failure, the cluster can still operate stably with read and write operations using the remaining two nodes. User services will not be interrupted.
To evaluate the semi-synchronous replication and high availability solutions using OpenStack Trove, tests were conducted in a controlled environment with the following setup: Database Cluster 3-node with OpenStack deployment and Semisynchronous Replication, Monitoring Tools.
To comprehensively assess the solution, various test scenarios were devised to simulate different types of failures and measure the system's response and recovery times. The key scenarios included: a. Master Node Failure
b. High Load
The following metrics were used to evaluate the performance and reliability of the implemented solution:
The tests yielded the following results:
The implementation of semi-synchronous replication and high availability features using OpenStack Trove significantly enhances the reliability and availability of database services. The automated failover and disaster recovery mechanisms ensure that user data remains safe and accessible even in the event of node failures or network issues. These advancements make OpenStack Trove a robust solution for deploying Database as a Service in a cloud environment, providing enterprises with a reliable and scalable database management platform.
By ensuring minimal replication lag, quick failover times, and consistent data integrity, this solution meets the high standards required for enterprise-grade database services. Future work could focus on further optimizing the failover processes and exploring additional replication models to enhance performance and reliability even further.
vinhnd20
commented
1 month ago
Abstract
Data loss on databases can truly be a nightmare for any business, as every bit of data could decide the success or failure of a business campaign or a project. Therefore, ensuring reliability, and high availability for databases is always a top priority in most enterprises. In recent years, DBaaS (Database as a Service) has become more popular than ever, offering a flexible and efficient approach to managing and operating databases. Additionally, many open-source solutions have been developed to help developers deploy DBaaS to their users, notably OpenStack Trove. OpenStack Trove is a key to deploying DBaaS with a robust cloud infrastructure and flexible data management features. However, despite offering data replication solutions, it still has limitations in ensuring the highest reliability and availability for the system. That's why we are looking towards a more advanced solution. In this presentation, we will introduce a new step in providing database services using OpenStack Trove. We will delve into the Semi-Synchronous Replication and High Availability Cluster models, and discuss how to effectively implement them on OpenStack Trove. This solution not only enhances reliability but also increases availability, ensuring data is not lost in the event of system failures. Additionally, it can be deployed across multiple zones or regions, supporting Disaster Recovery for your database system.
Keywords: DBaaS, OpenStack, Cloud computing, data loss, Disaster Recovery, High Availability.
I. Introduction
II. OpenStack
III. Replication , Semi-Synchronous Replication
IV. Implement
V. Test and evaluate
VI. Conclusion