 zergov
commented
23 hours ago
zergov
commented
23 hours ago J'ai aussi faite un figma qui montre un peu les differents flow, on pourra utiliser ca dans les rapports : https://www.figma.com/board/CXNpHkeO8oTvorDGhY4hP0/PFE---ETS---Github-visualization-tool?node-id=2-70&node-type=code_block&t=YIgNsUtGaGi3F8bI-0
 syw1-art
syw1-art
Proposal: Extract repository information in an async job
Today, this is how the API serves a user requesting information about a repository: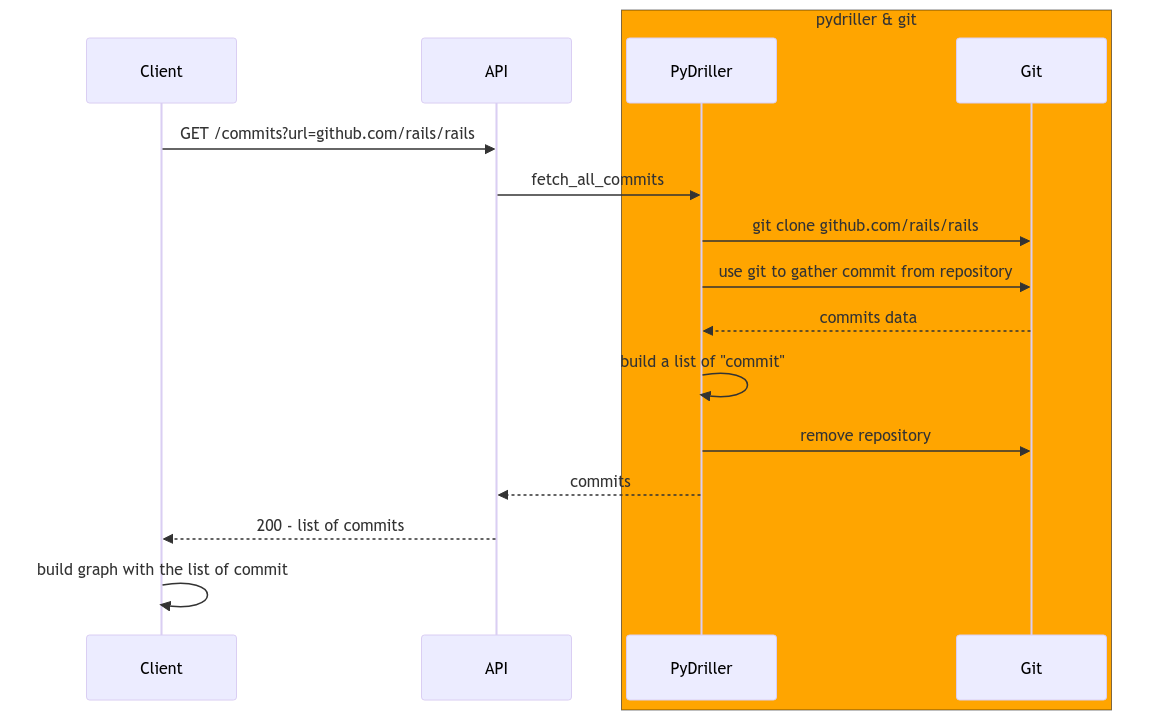
The orange section is very expensive. We shouldn't do this work each read requests. We should clone and invoke Git to extract information about the repo only once. The extracted data should be written to a database, and the application should read from this database.
This is the new flow I propose we do: Scenario: The user requests information about the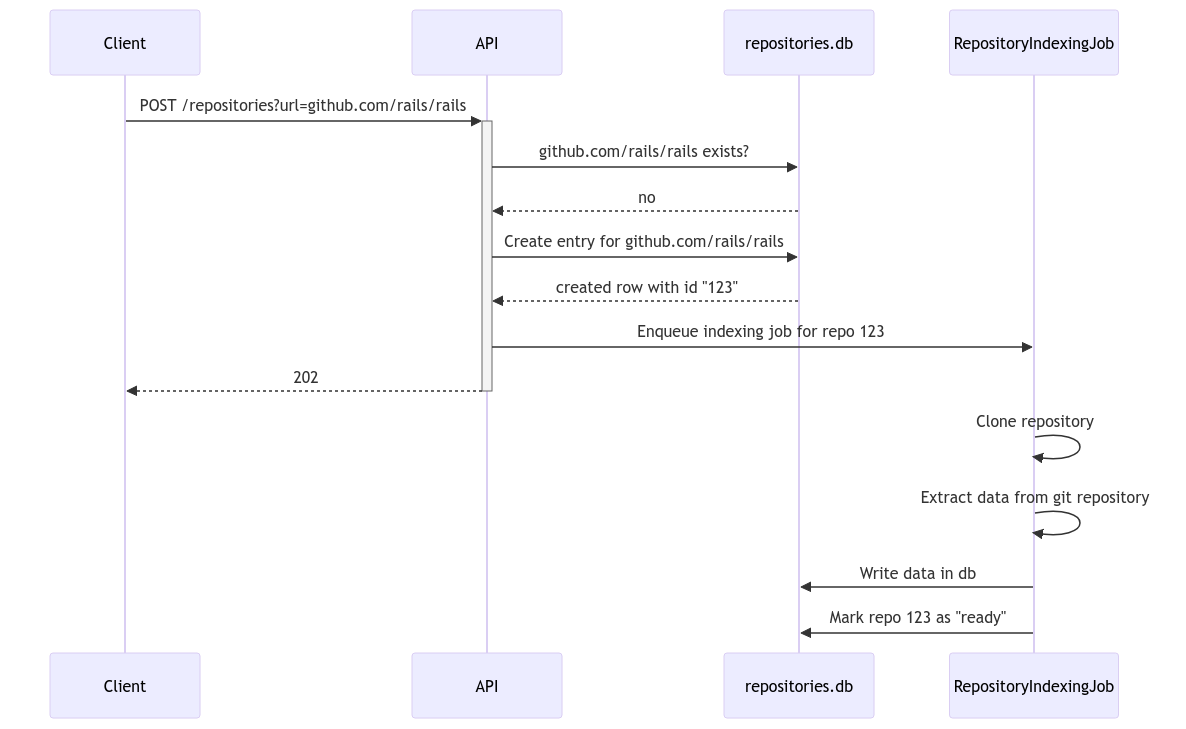
github.com/rails/railsrepository.In this model:
github.com/rails/railsrepository in our database and enqueue a background job to process that repo.The background job will clone, extract data from the repo, and write that data into our database. Once its done, it will mark the repo as "ready".
Once that's done, future requests for the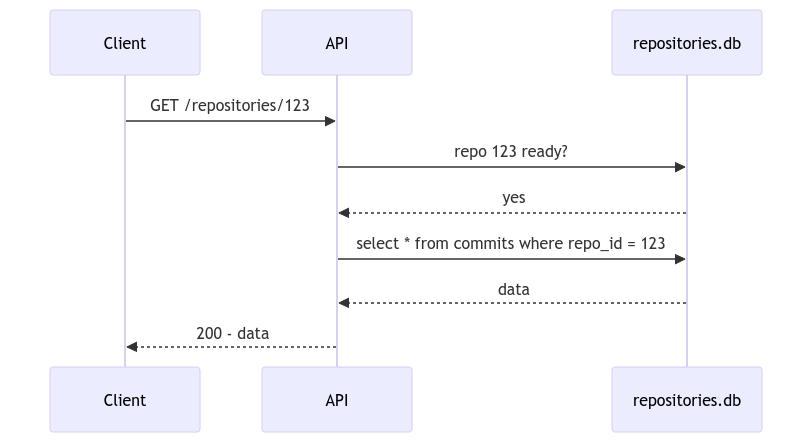
github.com/rails/railsrepository will use this flow:The request can be served to the user without having to invoke Git or clone the repository.