 vercel[bot]
commented
1 year ago
vercel[bot]
commented
1 year ago The latest updates on your projects. Learn more about Vercel for Git ↗︎
| Name | Status | Preview | Updated |
|---|---|---|---|
| cleanrl | ✅ Ready (Inspect) | Visit Preview | Dec 21, 2022 at 5:24PM (UTC) |
Closed 51616 closed 1 year ago
vercel[bot]
commented
1 year ago The latest updates on your projects. Learn more about Vercel for Git ↗︎
| Name | Status | Preview | Updated |
|---|---|---|---|
| cleanrl | ✅ Ready (Inspect) | Visit Preview | Dec 21, 2022 at 5:24PM (UTC) |
 vwxyzjn
commented
1 year ago
vwxyzjn
commented
1 year ago Thanks for preparing this PR @51616. Out of curiosity, what's the speed difference when running with the following?
python cleanrl/ppo_atari_envpool_xla_jax_scan.py --env-id Breakout-v5 --total-timesteps 10000000 --num-envs 8
python cleanrl/ppo_atari_envpool_xla_jax.py --env-id Breakout-v5 --total-timesteps 10000000 --num-envs 8 51616
commented
1 year ago
51616
commented
1 year ago 
Here's the training time comparison. I don't think we can compare the code speed by looking purely at this graph because the speed also depends on how fast the agent learns. Since environment reset is relatively expensive, the faster the agent gets better, the fewer resets are called. The rate at which the agent learns depends on exploration that we don't have full control over. Explicitly setting the random seed still cannot precisely reproduce runs. Anyway, I think we shouldn't expect any speed difference between the two versions (https://github.com/google/jax/issues/402#issuecomment-464860036). The benefits of this change is mostly the reduced compilation time.
The compilation time for the default num_minibatches=4 and update_epochs=4 decreases significantly using jax.lax.scan, from almost a minute to a few seconds. Using scan also does not increase compilation time when using higher values, whereas the python loop does.
If you think that jax's idiomatic is not so pythonic and hard to read, we can keep both versions. I think there is value in providing example in jax's idiomatic tools.
vwxyzjn
commented
1 year ago @51616 thanks for the detailed explanation. I really like this prototype and think it's probably worth having both versions as references. On a high level, there are some remaining todos (in chronological orders):
[x] sanitize the code — remove the commented-out code.
[x] minimize the difference between the two versions (try doing a file diff in vs code: select both files and click compare selected)

[x] add an end-to-end test case in the tests folder and probably add a unit test on compute_gae. You can probably do
from cleanrl.ppo_atari_envpool_xla_jax_scan import compute_gae
from cleanrl.ppo_atari_envpool_xla_jax import compute_gae
After these three steps feel free to ping me to review again, and the last step would be to do the following:
- [x] run benchmark on three environments to ensure performance is okay (there is no reason to run 57 atari games in this case). You should use the followingexport WANDB_ENTITY=openrlbenchmark python -m cleanrl_utils.benchmark \ --env-ids Pong-v5 BeamRider-v5 Breakout-v5 \ --command "poetry run python cleanrl/ppo_atari_envpool_xla_jax_scan.py --track --capture-video" \ --num-seeds 3 \ --workers 1
@vwxyzjn I did clean up some of the code. Please let me know if there's any specific place I should fix. I have a few questions regarding the tests/benchmarks:
compute_gae method, I have tested locally comparing with the original function. It was a quick and dirty test by pasting the function from the original file and comparing the output of the two. Testing in a separate file is a bit complicated though. It requires defining the function outside the if __name__ == '__main__' statement to be importable. Should I move the function out? What about other functions?vwxyzjn
commented
1 year ago For the compute_gae method, I have tested locally comparing with the original function. It was a quick and dirty test by pasting the function from the original file and comparing the output of the two. Testing in a separate file is a bit complicated though. It requires defining the function outside the if name == 'main' statement to be importable. Should I move the function out? What about other functions?
Ah my bad for not thinking this through. In that case, maybe don't import the compute_gae and copy them to the test files and compare. If that's too much hassle, without test on it is also ok :)
How do I access the project's wandb account?
Could you share with me your wandb account username? I will add you to the openrlbenchmark wandb team.
51616
commented
1 year ago In that case, maybe don't import the compute_gae and copy them to the test files and compare.
I will make a test file for that.
Could you share with me your wandb account username? I will add you to the openrlbenchmark wandb team.
Here's my wandb account: https://wandb.ai/51616
vwxyzjn
commented
1 year ago Thank you @51616 I have added you to the openrlbenchmark team. You might want to run pre-commit run --all-files to fix CI.
51616
commented
1 year ago @vwxyzjn I already did the pre-commit hooks for that commit but it still gives an error. I think it has something to do with the tests folder not being formatted but still being checked in CI? I will run the benchmarks today.
edit: turned out the test file was not formatted on my side.
51616
commented
1 year ago @vwxyzjn I did the benchmarks. Please let me know if you want any specific updates for this pr.
vwxyzjn
commented
1 year ago Thanks for your patience. The results look great. The next step is to add documentation. Could you give the following command a try? It compares jax.scan with the for loop variant and openai/baselines'PPO.
pip install openrlbenchmark
python -m openrlbenchmark.rlops \
--filters '?we=openrlbenchmark&wpn=cleanrl&ceik=env_id&cen=exp_name&metric=charts/avg_episodic_return' 'ppo_atari_envpool_xla_jax_scan?tag=pr-328' \
--filters '?we=openrlbenchmark&wpn=baselines&ceik=env&cen=exp_name&metric=charts/episodic_return' 'baselines-ppo2-cnn' \
--filters '?we=openrlbenchmark&wpn=envpool-atari&ceik=env_id&cen=exp_name&metric=charts/avg_episodic_return' 'ppo_atari_envpool_xla_jax_truncation' \
--env-ids BeamRider-v5 Breakout-v5 Pong-v5 \
--check-empty-runs False \
--ncols 3 \
--ncols-legend 2 \
--output-filename compare \
--scan-history \
--reportIt should generate a figure and tables (compare.md), which you can use to add the docs.
 51616
commented
1 year ago
51616
commented
1 year ago openrlbenchmark doesn't seem to work with python<3.9. I got the following error
ERROR: Ignored the following versions that require a different python version: 0.1.1a0 Requires-Python >=3.9,<4.0; 0.1.1a1 Requires-Python >=3.9,<4.0
ERROR: Could not find a version that satisfies the requirement openrlbenchmark (from versions: none)
ERROR: No matching distribution found for openrlbenchmarkedit: I ran the command with a new environment and it worked just fine but I'm not sure if the python>=3.9 requirement is intended.
vwxyzjn
commented
1 year ago Try again pip install openrlbenchmark==0.1.1a2 or pip install https://files.pythonhosted.org/packages/03/6c/a365d82a4653255cbb553414c9f15669ce7b947871233b5ab0f43a8de546/openrlbenchmark-0.1.1a2.tar.gz.
vwxyzjn
commented
1 year ago Yeah I have just made it compatible with python 3.7.1+
51616
commented
1 year ago Thank you for a quick response. I got the report but I'm not sure where to put it. Which specific doc are you referring to?
vwxyzjn
commented
1 year ago consider adding a section in https://github.com/vwxyzjn/cleanrl/blob/master/docs/rl-algorithms/ppo.md like other ppo variants
51616
commented
1 year ago I added the documentation. Not sure if I did it right. Please take a look :pray:
Description
Modifying the code to use
jax.lax.scanfor fast compile time and small speed improvement.The loss metrics of this pull request (blue) are consistent with the original version (green).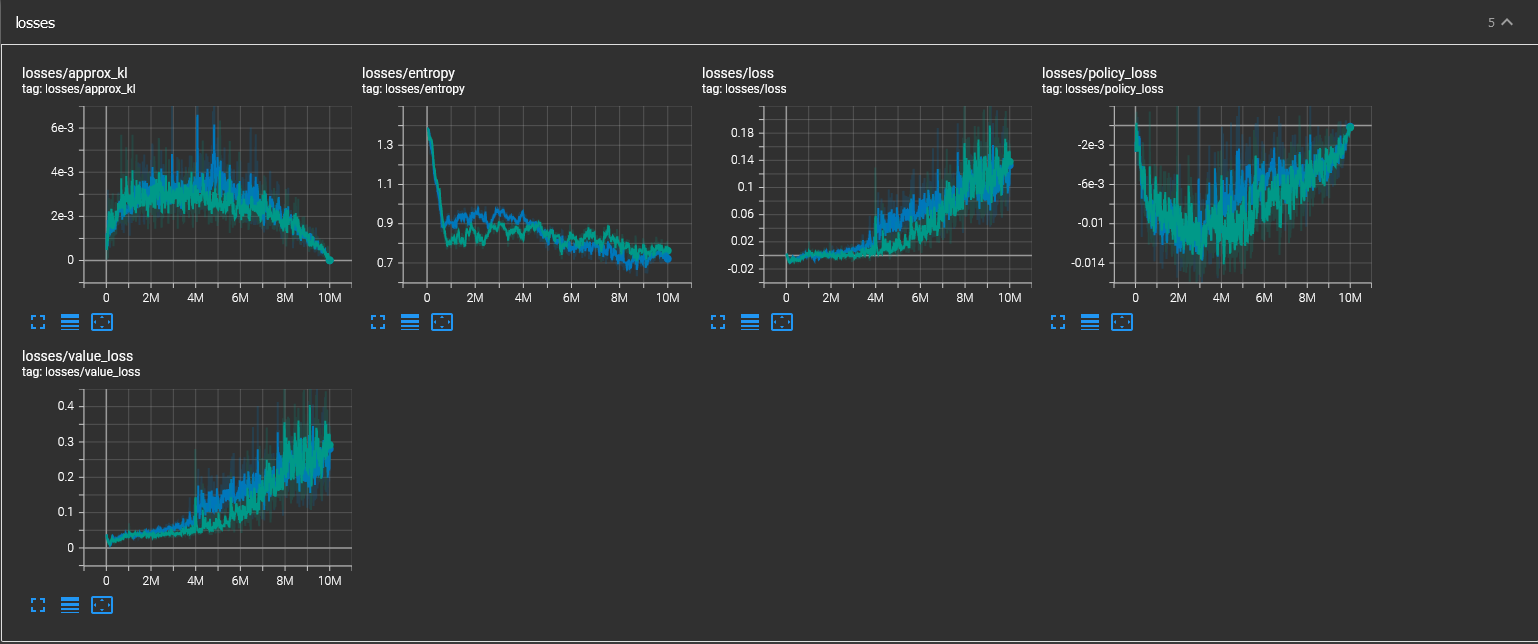
The performance is similar to the original with a slight speed improvement.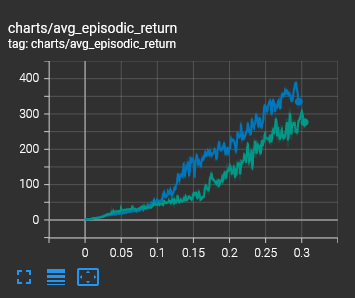
The command used is
python cleanrl/ppo_atari_envpool_xla_jax_scan.py --env-id Breakout-v5 --total-timesteps 10000000 --num-envs 32 --seed 111(blue) andpython cleanrl/ppo_atari_envpool_xla_jax.py --env-id Breakout-v5 --total-timesteps 10000000 --num-envs 32 --seed 111(green).Types of changes
Checklist:
pre-commit run --all-filespasses (required).mkdocs serve.If you are adding new algorithm variants or your change could result in performance difference, you may need to (re-)run tracked experiments. See https://github.com/vwxyzjn/cleanrl/pull/137 as an example PR.
--capture-videoflag toggled on (required).mkdocs serve.