 yoavweiss
commented
3 years ago
yoavweiss
commented
3 years ago That makes sense at a high level, but it would be interesting to dig into the details and see how we can define something like that in terms that are:
- Possible to specify in an interoperable way
- Not computing-intensive on low-end devices
- Ideally - image format agnostic
 eeeps
eeeps jonsneyers
jonsneyers addyosmani
addyosmani kornelski
kornelski vsekhar
vsekhar anniesullie
anniesullie
 jyrkialakuijala
jyrkialakuijala npm1
npm1 gunta
gunta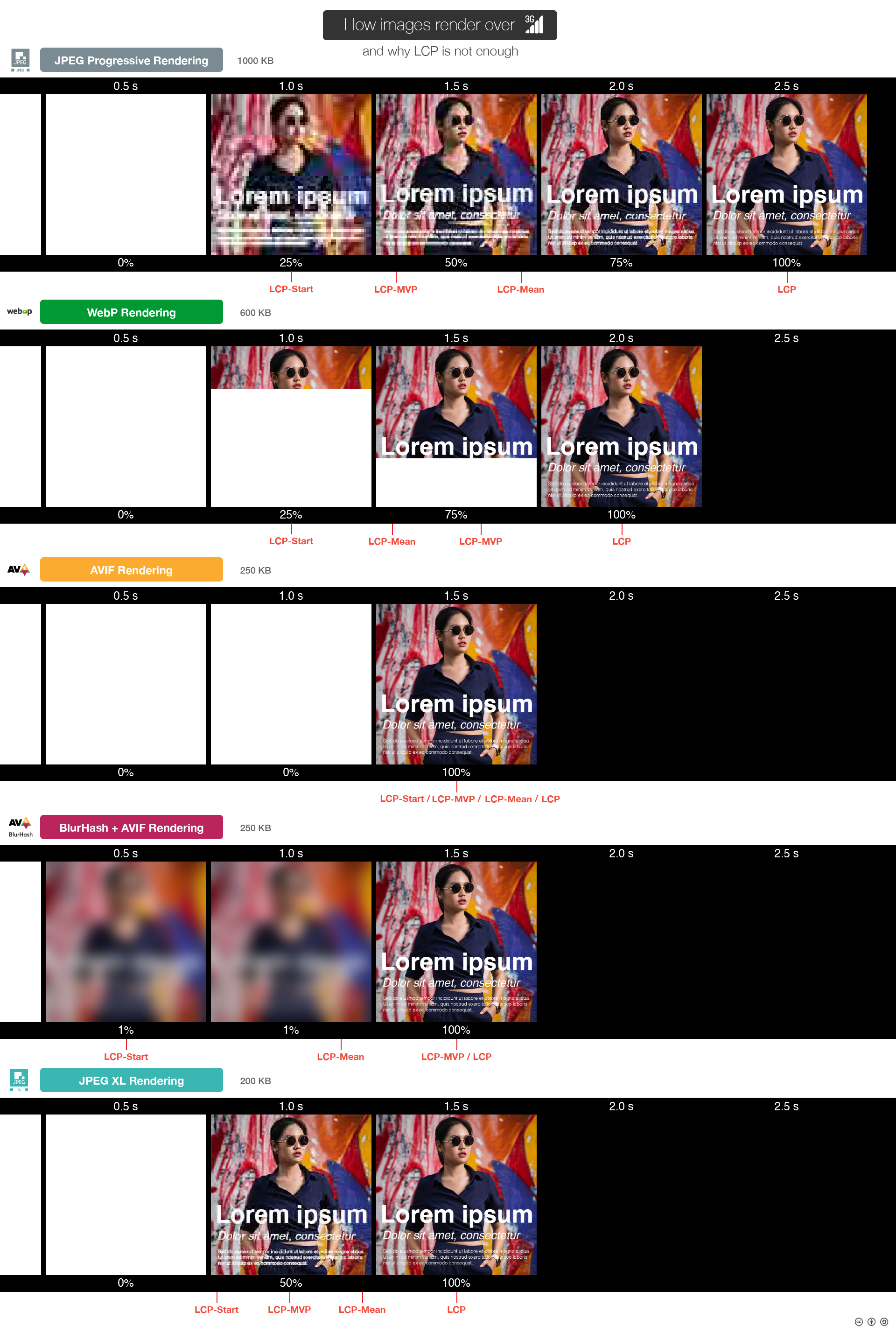

 mo271
mo271


 Not really all that different to considering all images larger than 50k.
Not really all that different to considering all images larger than 50k. 


If the LCP is an image, it doesn't really make sense to give the same score to a 100 kB AVIF, a 100 kB WebP, and a 100 kB progressive JPEG. The AVIF will only be shown after 100 kB has arrived (it gets rendered only when all data is available), while you'll see most of the image after 90 kB of the WebP (since it is rendered sequentially/incrementally), or after 70 kB of the JPEG.
Instead of defining LCP as the time when the image has fully loaded, it could be defined as the time when the image gets rendered approximately, within some visual distance threshold compared to the final image.
The threshold should be high enough to not allow a tiny extremely blurry placeholder to count as the LCP, but low enough to e.g. allow an image that only misses some high-frequency chroma least significant bits, e.g. the final passes of a default mozjpeg-encoded jpeg.