 masayuki-nakano
commented
1 year ago
masayuki-nakano
commented
1 year ago Firefox developers must have intended to work it with String.fromCharCode(event.charCode), and IIRC, a pair of WM_CHAR is sent by Windows for a surrogate pair input.
 jrandolf
jrandolf drwez
drwez Pauan
Pauan mathiasbynens
mathiasbynens garykac
garykac hsivonen
hsivonen{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
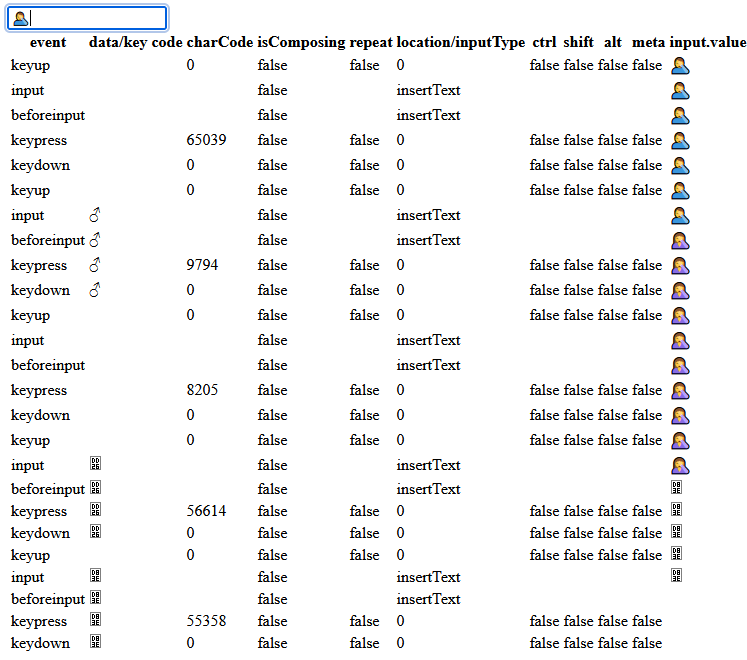
See https://github.com/w3c/webdriver/issues/1741: browsers don’t agree on
keypressevents for keys that map to non-BMP Unicode symbols (i.e. code points beyond U+FFFF).You can reproduce this on https://w3c.github.io/uievents/tools/key-event-viewer.html using a custom keyboard layout. I’m using https://github.com/mathiasbynens/custom.keylayout/tree/main/qwerty which lets me press a key to type
𝌆(U+1D306), which consists of the surrogate halves U+D834 U+DF06.keypressevent is emitted, withcharCode/keyCode/whichset to the full Unicode code point0x1D306. (This is the behavior I’d expect as a user.)keypressevents are emitted, one for each surrogate half (0xD834and0xDF06).keypressevent is emitted.Screenshot showing (from top to bottom) Safari, Firefox, and Chrome: