 jwrosewell
commented
4 years ago
jwrosewell
commented
4 years ago Dear Yoav,
Over the past two weeks we have sought evidence to justify this change. We have found none. None of the industry stakeholders we have spoken to were previously aware of the proposal. This means that the usual and necessary protocols of public review are lacking.
In its current form this could easily be interpreted as a partisan gerrymandering attempt by the incumbent dominant player in the field, to the disadvantage of other players.
In our conversations with other players, most recently at the Westminster Policy Forum, we found that they thought that this was all part of a cookie discussion. Solicitation of feedback from a wide global cross section of stakeholders via a neutral party is now required. The W3C comes to mind as fulfilling exactly that role.
This proposal is too radical and has too much potential for disruption to be pushed though quickly, even if you accept the privacy arguments, which we remain unconvinced by.
Considering purely the macro issues associated with good governance and controlled change we observe the following:
-
The proposal has not been reviewed beyond a small group of dedicated, focused and elite engineers who in the main add – not take away – excellent features. This change impacts global industry sectors as diverse as publishing, marketing, advertising, technology, charities and more in yet undetermined ways. The risk is equivalent to the Y2K bug.
-
Online platforms – and Google in particular – are the subject of a wide ranging Competition and Market Authority (CMA) review covering the subjects of this proposal. The full report is expected to be published on 2nd July 2020. An interim report was published on 18th December 2019. The interim report establishes a balance between the needs of individuals for privacy and for markets and technology to function efficiently. Its conclusions should inform this proposal.
-
This proposal will disproportionally benefit Google as in practice it will remove data for smaller platform operators and millions of others. Paragraph 60 appendix E of the CMA review states.
“Google is the platform with the largest dataset collected from its leading consumer-facing services such as YouTube, Google Maps, Gmail, Android, Google Chrome and from partner sites using Google pixel tags, analytical and advertising services. A Google internal document recognises this advantage saying that ‘Google has more data, of more types, from more sources than anyone else’.”
The appendix includes the following diagram to illustrate the point.
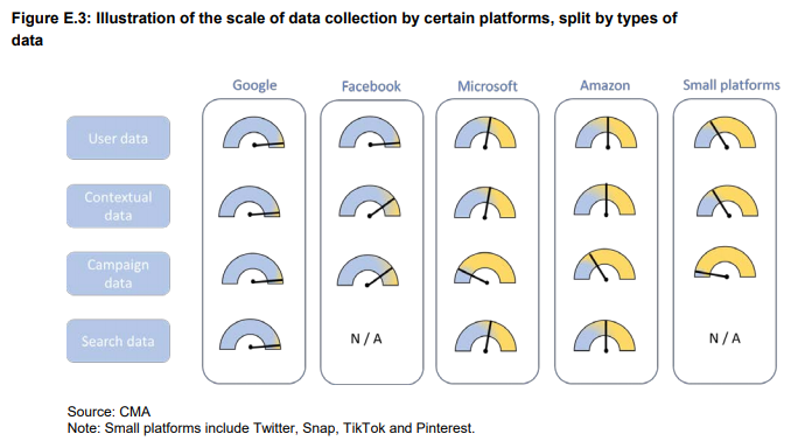
-
The CMA are yet to comment on Google’s role in relation to influence over web standards via the Chromium project and other means. Microsoft’s decision to adopt Chromium, and the apparent decline of Firefox are likely to be topics they comment on in July 2020.
-
We need more time to discuss the impact with our users. We believe this is true for others.
As just one example the AdCom specification needs to be updated. Only once this is done can all publishers, SSPs, exchanges and DSPs adopt the new schema. If any of these parties do not make the modifications all are disadvantaged. The change needs to be made in lockstep.
Many trade bodies and organisations are focused on the implications associated with the publicity concerning 3rd party cookies. They are only just becoming aware of this proposal. We are encouraging them to engage publicly but respect the demands on their time, limited resources and the sensitivities concerning the topic of privacy.
There are many more arguments concerning assumptions, insufficient evidence, implementation, control over privacy (who decides?), and the technical impacts of the proposal yet to be resolved.
In summary, this is a change that requires careful and widespread consideration, and a significant effort to socialise for it to be recognised by all as legitimately in the public interest. Without mature reflection and appropriate implementation delay it will be perceived as market manipulation by the incumbent player.
Regards,
James Rosewell - for self and 51Degrees
 torgo
torgo jyasskin
jyasskin yoavweiss
yoavweiss mh0478025
mh0478025 kiwibrowser
kiwibrowser gjsman
gjsman chris-griffin
chris-griffin pluma
pluma fredgrott
fredgrott joneslloyd
joneslloyd fightborn
fightborn markentingh
markentingh AdamMurray
AdamMurray bhartvigsen
bhartvigsen dbaron
dbaron annadane
annadane awilfox
awilfox kralos
kralos baybal
baybal JasSra
JasSra nt1m
nt1m withinboredom
withinboredom mcatanzaro
mcatanzaro ocram
ocram Steve51D
Steve51D ImaCrea
ImaCrea immanuelfodor
immanuelfodor mgol
mgol ghost
ghost scottlow
scottlow ronancremin
ronancremin
Goedenavond TAG!
This is not your typical spec review, and is highly related to https://github.com/w3ctag/design-reviews/issues/320. But, because @torgo asked nicely, I'm opening up a review for a specific application of UA-CH as a replacement for the
User-Agentstring.We've had a lot of feedback on the intent, which resulted in changes to the API we want to ship. It also resulted in many open issues. Most either have pending PRs or will have ones shortly.
The latest summary is:
User-Agentrequest header will be frozen other than its browser's significant version, and unified between different platforms and devices to reduce the amount of passive fingerprinting the browser is sending out by default.navigator.userAgentand friends will be similarly frozen.Sec-CH-UAandSec-CH-UA-Mobileheaders to enable most cases of content negotiation. As those headers are low-entropy, we can afford that trade-off, privacy-wise.Sec-CH-UAis defined as a set, and likely to be GREASEd to avoid current abuse patterns of the User-Agent string.Checkboxes:
Further details:
You should also know that...
[please tell us anything you think is relevant to this review]
We'd prefer the TAG provide feedback as (please delete all but the desired option):
🐛 open issues in our GitHub repo for each point of feedback