 wanghaisheng
commented
6 years ago
wanghaisheng
commented
6 years ago 

Open wanghaisheng opened 6 years ago
wanghaisheng
commented
6 years ago
wanghaisheng
commented
6 years ago 大多数人每天都会使用到一些机器人流程自动化工具,例如读取邮件和系统,计算,生成文件和报告。而在未来,那些你不想做的枯燥的工作,也许真的可以不做了,重复化、标准化的工作都可以让机器人帮你完成。本期推文特邀陈剑独家原创阐述RPA的概念、原理与实践。
本文将就以下五个部分展开——
01 理解RPA
02 RPA的优势
03 RPA和AI是什么关系?
04 RPA与财务共享服务
05 RPA选型与ADII实施方法
01
理解RPA
RPA是Robotic Process Automation的缩写,从字面便不难看出其要义,即:机器、流程、自动化,RPA是以机器人作为虚拟劳动力,依据预先设定的程序与现有用户系统进行交互并完成预期的任务。从目前的技术实践来看,现有的RPA还仅适用于高重复性、逻辑确定并且稳定性要求相对较低的流程。
用更通俗的解释,RPA就是借助一些能够自动执行的脚本_(这些脚本可能是某些工具生成的,这些工具也可能有着非常有好的用户化图形界面)_完成一系列原来需要人工完成的工作,但凡具备一定脚本生成、编辑、执行能力的工具在此处都可以称之为机器人。
比如,在游戏领域被广泛为人所熟知的国产软件“按键精灵”,即可以通过它的一些简单功能帮助我们完成一些自动化的工作。
按键精灵的简要工作原理是通过录制操作者的鼠标和键盘的动作步骤形成操作脚本(用户也可以不用录制的方式,完全手工编写脚本),这里的脚本是可以修改的,用户可以更具需要修改脚本的参数,比如鼠标点击的位置、键盘输入的值,再次运行脚本的时候就会重新执行录制过程中的这些动作,如果脚本的参数有修改,则会执行对应的调整后的动作。
我们可以借助这个软件,通过录制鼠标和键盘动作的方式,来完成一些简单的操作,如果用户用的熟练,理论上按键精灵既可以帮助我们完成一些更复杂场景下的自动化工作处理。
举个简单的例子,比如我们每天上班时要打开ERP系统并进入到AP发票处理页面,如果你觉得每天都重复这么做非常无趣(如果没有设置保存账户和密码的话),我们就可以通过按键精灵来简化我们的步骤,点击软件的录制动作按钮之后,软件就开始记录我们的动作.
比如双击ERP软件的图标、输入账户信息,点击登录按钮,进去之后再点击菜单逐层进入AP发票处理页面,等这一系列的操作完成之后,我们点击停止录制,然后为这个录制的流程设置一个快捷键,比如ctrl+1。
怎么使用这个录制的过程呢,等我们再次上班时,按下ctrl+1,这个软件就会按着你上次录制的过程依次做一遍,直到运行结束,整个过程完全不需要你的参与,以后你就可以通过这个方式一键登录ERP系统并进入发票处理页面了。
考虑面向的用户群体往往并不会拥有专业的技术背景,总体而言,这些工作与流程自动化工具的应用还是相对比较简单易用,通常可以通过图形化的界面完成脚本的生成与编辑,即使是利用相对专业的脚本编辑器,这里的脚本业务完全不是程序员所面对的那种代码,简单看一下教程很快也能上手。
比如以下在Mac OSX系统下利用Apple Script所编写的简单工作自动化代码(让Google Chrome浏览器在新窗口中打开百度首页),可以看到语法非常简单,基本上已经是英语大白话了。
上面就是RPA的简单原理示例,当然现今各大软件厂商推出的RPA工具远比上述我们提及的小工具在功能丰富度上、场景的针对性上强很多,但其核心逻辑并没有本质的差异,在某些特定的业务场景下,熟练的Excel VBA开发者仅利用office工具甚至也能完成好的RPA工作(许多RPA工具仍然需要Excel VBA来进行协同工作)。
02
RPA的优势
通过上文的介绍,相信读者能够很好的理解以下RPA的特点,这些特点正是RPA能够给企业带来价值的主要原因:
机器处理:通过用户界面(UI)或者脚本语言(Script)实现借由机器人的重复人工任务的自动化处理;
基于明确的规则操作:流程必须有明确的、可被数字化的触发指令和输入,流程不得出现无法提前定义的例外情况;
以外挂的形式部署在客户现有系统上:基于规则在用户界面进行自动化操作,非侵入式模式不影响原有IT基础架构;
模拟用户手工操作及交互:机器人可以执行用户的日常基本操作,例如:鼠标点击、键盘输入、复制/粘贴等一系列日常电脑操作。
RPA的优势来源除了上述这些众所周知的功能特点外,对于规则的高度严肃性(良好的操作品质)、对现有系统的非侵入性(非耦合型)都是RPA的突出特点。
以下我们从这两个层面分别去理解RPA在应用过程中所带来的优势:
03
RPA和AI是什么关系?
有些厂商在宣传RPA的时候有意无意和人工智能扯到了一起,但是从负责任的角度,RPA和AI简直天壤之别,现在的机器人还只是逻辑编程比较完善能够执行一定预制判断逻辑的的机器,还远谈不上人工智能,透过下面这张图,读者应该能够理解RPA和AI在自动化发展路径上的位置差异。
人工智能(Artificial Intelligence)是一个相当广泛的概念,人工智能的目的就是让计算机这台机器能够象人一样思考,而当前被广泛提及的机器学习(Machine Learning)都只是人工智能的分支,机器学习是专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,使之不断改善自身的性能。
战胜围棋各段高手的Google AlphaGo就是机器学习的代表,它所使用是深度学习(Deep Learning)方法,DL试图使用包含复杂结构或由多重非线性变换构成的多个处理层(神经网络)对数据进行高层抽象的算法,因此能够处理以前机器难以企及的更加复杂的模型(比如:高度的不确定性、超大的计算量)。
当前财务在人工智能行业热度中处于居中位置,但距离AI在财务、会计领域的实用化还为时尚早,从短期内的趋势而言,还是基于标准化、逻辑清晰的RPA为基础,逐步向具有一定智能化程度的流程自动化转变。
但是随着近年无论是全球范围还是中国范围的人工智能投资的逐步加大,相信我们在未来的十年或者二十年内,AI在实用性和普及型方面的逐步突破,财务领域的AI深入应用亦未可知。
04
RPA与财务共享服务
根据之前我们对于集团财务指导、控制、执行三个层面职能的划分,我们不难理解发现RPA将更容易在执行和控制两个层面发挥应有的价值,尤其是在交易性的业务执行层面,通常会有更多契合业务需求的实用应用场景,就像制造工厂越来越广泛的引入机器人工作中心来实现生产环节的去人工化,机器人软件有着财务工厂之称的财务共享服务中心同样有着广阔的空间,尤其是近年国内共享服务中心建设浪潮兴起,RPA概念和应用实践也一度占据了新闻热点。
以一个典型的交易型财务共享服务中心为例,常见的业务流程一般包括销售至收款(OTC)、采购至应付(PTP)、员工费用报销(T&E)、资产核算(FA)、总账与报告(RTR)、资金结算(TR)等流程,这些流程里不少业务处理环节都具备高度的标准化、高度的重复性特点,这也是RPA大展拳脚的广阔空间,那么现阶段这些流程里RPA有怎样的应用的Best Practice呢?
下表为读者简要展示了一些应用的示例:
流程循环
典型应用示例
销售到收款
自动开票:机器人自动抓取销售开票数据并自动进行开票动作;
应收账款对账与收款核销:机器人取得应收和实收数据,按照账号、打款备注等信息进行自动对账,并将对账差异进行单独列示,对于对账无误的进行自动账务核销;
客户信用管理:自动进行客户信用信息的查询并将相关数据提供给授信模块用以客户信用评估、控制
采购到付款
供应商主数据管理:自动将供应商提供的资料信息进行上传系统处理(比如获取营业执照影像并识别指定位置上的字段信息,填写信息到供应商主数据管理系统,上传相关附件);
发票校验:基于明确的规则执行三单(发票、订单、收货单)匹配;
发票处理:发票的扫描结果的自动处理(与机器人结合的OCR、发票的自动认证等);
付款执行:在缺少直接付款系统对接的场景下,可考虑利用机器人提取付款申请系统的付款信息(付款账号、户名等),并提交网银等资金付款系统进行实际付款操作;
账期处理及报告:比如自动财务账务处理(应付、预付重分类等);
供应商询证:自动处理供应商询证信息并将结果信息进行自动反;
差旅与报销
报销单据核对:比如自动发票信息核对(申报数与发票数等)、报销标准核查等;
费用自动审计:设定审计逻辑,机器人自动按照设定的逻辑执行审计操作(数据查询、校验并判断是否符合风险定义);
存货与成本
成本统计指标录入:机器人自动;
成本与费用分摊:期末机器人按脚本分步或并行执行相关成本、费用分摊循环
资产管理
资产卡片管理:批量资产卡片更新、打印、分发等;
期末事项管理:资产折旧、资产转移、报废等的批量处理;
总账到报表
主数据管理:主数据变更的自动系统更新、变更的通知、主数据的发布等;
凭证处理:周期性凭证的自动处理、自动账务结转、自动凭证打印;
关联交易处理:关联交易对账等;
薪酬核算:在缺少系统对接场景下的自动薪酬账务处理;
自动化报告:格式化报告的自动处理;
资金管理
资金管理:根据设定的资金划线执行自动资金归集、自动资金计划信息的采集与处理等;
对外收付款**:**收款与付款的自动化处理;
银行对账等:机器人取得银行流水、银行财务账数据,并进行银行账和财务账的核对,自动出具银行余额调节表;
税务管理
税务申报:税务数据的采集与处理、税务相关财务数据、业务数据的采集与处理,自动纳税申报;
05
RPA选型与ADII实施方法
目前面向桌面自动化、流程自动化的软件工具大致可以分为消费级和企业级两大类,相信不少消费级软件读者都不太陌生,而企业级则相对了解有限,这里补充一些面向企业的RPA产品供本书读者参考、备选,有关详细信息读者可以自己查阅他们的官方网站。
以下是RPA相关产品代表——
RPA的实施通常不涉及企业现有IT架构的调整,但现有的RPA平台和平台之间多数是无法相互兼容的,因此一旦选择某平台,随着其上运行的应用场景的增多,未来可能在相对长的一段时间内较难进行平台的迁移,因此在平台选型时需要综合考虑各自平台的优缺点,充分比较用户易用性、系统集成性以及平台收费模式等。
一旦确定RPA平台,企业所需要面对的是一个个像纷至沓来的各类RPA需求,因此良好的需求与实施管理同样非常重要。
在基于明确的RPA平台上进行流程自动化的实施,多数是场景式的、相对短流程的流程节点优化,总体目标是消除流程中需要广泛人工处理但逻辑清晰的业务步骤,但其改善需求是否与RPA平台匹配则需要进行一定的评估,诸如预计收益、预计RPA初始化投入等,确认后即进入设计、实施环节,多数轻量的RPA场景实施能够保证在一周之内完成设计和落地,而后则是结合运营反馈的改善。
综合上述步骤,本文提出RPA实施的ADII方法,期望能够帮助已经选用了RPA平台的读者和企业更好的管理到RPA实施。
案例:
某企业实施
纳税申报自动化的
RPA流程
对于纳税主体较多的集团性企业,由于纳税申报的数据来源不同(有来自财务系统,有来自开票软件,还有其他台账等),本来手工操作量就大,即使部分企业已经部署了VBA来实现单主体报税数据的自动生成,但当所以当存在较多纳税主体需要编制报表时,数据准确性无法保障,人工处理部分的工作占比过高,数据处理、报表编制效率不高。
纳税申报过程整体RPA适配度高,相当多的步骤可以借助机器人进行自动化,当前市场上支持这部分工作自动化的厂商也较多,因此这家企业启动了基于RPA的纳税申报自动化项目。
最终RPA实施的纳税申报过程被细分为三大子过程,即:数据采集与处理过程,数据提交过程,账务处理过程。
其中,数据采集过程更多的是与本地数据的交互(税务主体信息、开票信息、财务信息等),而数据提交过程更多的是与税局系统的交互过程(登录、数据填写、提交等动作),账务处理过程则是纳税、缴税的账务化反映。
1)数据准备过程
第一,利用RPA工具,通过脚本的预定义,期末机器人自动登录账务系统(比如试算平很表、固定资产子账目)、国税系统按照税务主体批量导出财务数据、增值税认证数据等税务申报的业务数据基础;
第二,机器人自动获取事先维护好的企业基础信息用以生成纳税申报表底稿;
第三,对于需要调整的税务、会计差异、进项税数据差异、固定资产进项税抵扣差异、预缴税金等自动通过设定好的规则进行调整,借助预置的校验公式进行报表的校验(比如财务科目与税务科目的数字校验);
第四,机器人将处理好的数据放到统一的文件夹,由税务人工进行审查(或干预)。
2)数据提交过程
第一,对于核对审查无误的数据,执行脚本,由机器人按照公司主体自动登录税务申报系统;
第二,执行纳税申报底稿的读取,并自动导入底稿相关数据,执行纳税申报表提交动作以完成纳税申报,并将相应的信息保存在本地。
3)账务处理过程
第一,税务分录的编制与自动录入:根据纳税、缴税信息完成系统内税务分类的编制;
第二,计算递延所得税并完成分录的编制与录入:对于涉及递延所得税的,自动进行递延所得水资产或负债的计算并完成系统内的入账。
版权声明:本文来源为管理学家。
wanghaisheng
commented
6 years ago wanghaisheng
commented
6 years ago wanghaisheng
commented
6 years ago https://github.com/robotframework/robotframework
Generic test automation framework. http://robotframework.org
wanghaisheng
commented
6 years ago https://github.com/littlecodersh/ItChat A complete and graceful API for Wechat. 微信个人号接口、微信机器人及命令行微信,三十行即可自定义个人号机器人。 http://itchat.readthedocs.io
wanghaisheng
commented
6 years ago https://github.com/node-webot/weixin-robot 微信公共帐号自动回复机器人 A Node.js robot for wechat.
wanghaisheng
commented
6 years ago https://github.com/go-vgo/robotgo/blob/master/README_zh.md
Golang 跨平台自动化系统,控制键盘鼠标位图和读取屏幕,窗口句柄以及全局事件监听https://github.com/Bottr-js/Bottr 🤖 The world's simplest framework for creating Bots http://bottr.co
wanghaisheng
commented
6 years ago 🤖 A Node queue API for generating PDFs using headless Chrome. Comes with a CLI, S3 storage and webhooks for notifying subscribers about generated PDFs
wanghaisheng
commented
6 years ago https://github.com/Chatie/wechaty
WeChat Bot SDK for Personal Account, Powered by TypeScript, Docker, and 💖 https://chatie.io/wechaty/
wanghaisheng
commented
6 years ago https://github.com/arviedelgado/Roro Roro is a free open-source Robotic Process Automation software. http://roroscript.com
wanghaisheng
commented
6 years ago Cons
1 "Record and Play" feature not available
2 Windows 10 not supported
3 Limited browser support beyond IE
4 Version control management tool not available
5 Product Licence is costly. Need to have minimum licences.
6 Windows based control room as opposed to web based control room from compatatiors.
7 Mainly used for Backoffice (unassisted automation). RDA / assisted automation is supported through surface automation (double check) using events like button click event.
Important Elements of Blue Prism:
Process studio
Object studio
Control room
System manager and Release manager
Application Modeller
PROs
1 Great RPA tool for both RDA and RPA. RDA is assisted automation where Agent an Bot work together. It requires a design of user interface.
2 Integrated with Visual studio and great if you have DotNet/C# experience.
3 Framework components like Logging, runtime configuration (read dynamic values from xml) can be built as C# DLL / custom conrols and import it to openspan studio.
5 Text adapter/Emulator for mainframe support
6 TFS integration
Cons
1 Non Visual studio .Net developers find it difficult.
2 Localized credential staorage in flat file.
3 Inbuilt work queues not available
Important Elements of PegaRobotics/Openspan 1 Robotic Desktop Automation (RDA) support by adding windows forms 2 Adapters (Web, Desktop, Text and Citrix) 3 Global Container, Activities and Interaction manager to pass data back and forth between projects 4 Entry and Exit points
Cons
1 Inbuilt work queues not available
2 AA has localized credential staorage in flat file. Credential vault is not secured for users
3 Need minimum programming experience
4 AA only has task level reporting capability
5 AA has procedural approach towards exposing AA components.
6 AA fails to create a complete Virtual workforce concept by not allowing to share same workstation with Agent/user.
7 Exposing web service not supported in AA
8 Limited features for data driven backend operations, compare to its competators. For ex, excel automation or file automation.
Elements of AA
Cons
1 Overall runtime performance is slow
2 Requires 8 GB RAM
3 Java code not supported whereas VBA, C# are supported
4 Able to extract PDF data but extracting tabular data from PDF is lengthy process
Elements of UiPath: 1 UiPath robots - Enterprise ready Front and Back office robot 2 UiPath Studio - 3 UiPath Orchestrator - Enables the Orchestration and management of thousands of robots from a single command centre
wanghaisheng
commented
6 years ago https://github.com/MnKGuitarPro/academy_uipath
Exercises from the UiPath Academy Courses
wanghaisheng
commented
6 years ago 导入RPA应该了解的一些知识
上次概要介绍了下RPA的基本知识,这次说一下导入RPA时应该知道的一些知识点。
RPA是为了实现用软件自动化代替在各个行业中用人操作电脑办公的这部分业务,即使是在多个应用之间需要共享数据才能完成的业务,也可以实现自动化处理。
例如说对于会计部门来说,员工每月都有交通费,差旅费,宴请费等等各种单据需要报销,会计部门需要对这些费用进行整理,收集,精算甚至登录到公司的管理系统,还要把汇总结果登录到税务部门的系统上去,或者还有和工资明细等等进行合并,作业量非常大。如果使用里RPA的软件,就可以自动识别单据类型,费用,特定员工信息,自动输入公司的管理系统,税务系统,也可以登录薪资系统取得工资信息,依照模板制作工资条,通过邮件通知员工。更加高级的定制功能,可以通过查询网络信息,核查各项费用的合理性等等,大大减少工作量,提高工作效率,减少出错率。
现在自动化的方法有基于规则库,基于宏,脚本,API等方法实现RPA功能的。
典型的RPA工具是用基于各个软件商提供的规则库,宏,脚本,比较容易的开发出所需的自动化业务流。大部分的RPA工具有点像Excel的宏,记录鼠标和键盘的各种操作,然后用规则库的各种控件控制流程,也会提供简单的脚本语言以便定制一些特殊业务。
作为RPA的一些代表软件商有美国的Automation Anywhere,英国的Blue Prism,罗马尼亚的UiPath
还有WorkFusion,Pegasystems,NICE,Redwood Software,Kofax等等。
美国的Automation Anywhere的占有率最高,是在Windows系统上运行,主要在任务编辑器上记录想要自动化的作业过程,然后做成脚本。对网页数据的抓取和依据计划进行文件转送等的业务,提供数十种的模板,和OCR,JAVA等的结合组件也给提供,不过要收费。
英国的Blue Prism是在微软的.NET Framework之上做成的,提供比较丰富的组件,支持的领域也比较广泛,使用中央式管理,就是费用太贵。
UiPath是最近在看的工具,是罗马尼亚一家公司,说是现在以美国为中心在开展业务了,东京香港新加坡都有办事处了。提供的工具分三个模块,Studio是开发工具,不需写代码,提供了丰富的模板来进行自动化业务的记录。Robot是个执行自动化的部分。Orchestrator用来日志和资源管理,机器管理和统括管理的工具。
对于导入RPA需要注意的几个点:1:担当的分配和职责必须明确
2:应用范围要确定
3:导入计划要确实管理
4:费用(购买工具的费用,维护费,设备购置等等)
5:品质管理
6:风险评估和应对
7:导入实施的判断标准
8:对应人员的培训(目前基本是英语,工具学习等等)
wanghaisheng
commented
6 years ago 
wanghaisheng
commented
6 years ago 

wanghaisheng
commented
6 years ago 
wanghaisheng
commented
6 years ago  wanghaisheng
commented
6 years ago
wanghaisheng
commented
6 years ago challenger Use AI to free human from drudgeries.
很多工作被机器取代,这是大势所趋。最近国外有个很流行的概念叫 robotic process automation (RPA),暂时还没有准确的汉语翻译,本质就是使用计算机技术把日常工作中重复性的工作自动化,省时省力还能避免网球肘。
其实在我并不知道这个概念之前,就自己做了一些微小的工作。我是做 SAP 实施的,在本司各种密集的项目中,有大量的重复性配置要做。当初曾经复制粘贴到手都感觉要断了,而且这种无聊的工作让人怀疑人生,我他妈是干嘛来了,为什么要做这种没有意义的事情,这种事情不应该是印度人做么。。
当然确实是可以找印度人做,但人家也不是傻子,塞这种活计他们又不高兴。那怎么办呢?计算机是最不讨厌重复性工作的,一个循环重复一万次加减法它也不抱怨,事实上,这也是我一直以来的想法:把所有重复、机械、无聊的工作都交给计算机,而人类可以只做有趣的、创造性的事情。
我把自动化的过程分为了三个阶段:笨笨的自动化(硬编码),聪明的自动化和人工智能。
首先讲笨笨的自动化,这种其实很简单,就是用编程模仿鼠标和键盘的操作,然后交给计算机重复执行。编程语言的话当然是用 Python 大法啦,最简洁优雅的语言就是坠吼的。
Python-模拟鼠标键盘动作
举个栗子,比如要把一个 CSV 里面的数据更新到网站,因为一次性只能更新一行的数据,所以要重复非常多次才能完成。如果写一个简单的脚本,那么 Python 可以自己去填写,一个 tab 填用户名,两个 tab 填密码,再 N 个 tab 填描述等等。这些流程是写死在程序里的,所以叫硬编码。对于简单的重复性场景来说,这不失为有效的自动化方法,就像 Excel 里面的宏一样。下面这段是我用来发 QQ 骚扰我妹的,迅速狂发同一条信息。。它跑在 Mac 上,Windows 上运行的话键的名称改一下就好了。可见非常简单。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pymouse import PyMouse
from pykeyboard import PyKeyboard
m = PyMouse()
k = PyKeyboard()
for i in range(10):
k.press_key('Command')
k.tap_key('Tab')
k.release_key('Command')
k.type_string("Xiong Hai Zi!")
k.tap_key('Return')
k.press_key('Command')
k.tap_key('Tab')
k.release_key('Command')但是硬编码有它自己的问题,因为所有都是写死的,所以它只能适应单一的 GUI 场景,万一有变化呢?比如说在 SAP 配置页面,不同的 FTP/RFC/HTTP adapter 要配置的东西完全不一样,如果针对每一个都硬编码的话,理论上是可以的,但也太麻烦了,适应性也不好,万一 SAP 有个新的东西又要写一堆代码。那么有没有更聪明的办法呢?这就是聪明的自动化了。
它的原理也并不复杂,主要是让计算机能够像人类一样『看』到电脑上的字符,然后再跟配置文件里的内容对照,动态决定应该去哪个地方配置。这里面用到了计算机视觉(CV)和光学字符识别(OCR)的技术。
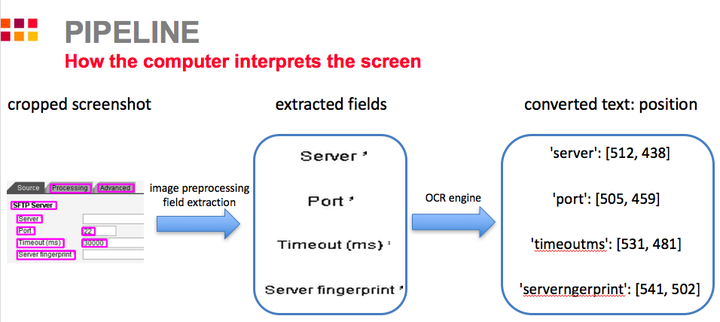
事实上,我只写了不到 300 行代码,就实现了可以配置 SAP PI 所有类型的场景,即使有新的场景一样可以对付,而且不管电脑怎么换,屏幕分辨率怎么变,全部都可以一键搞定。
更高级的自动化就是人工智能了,这个目前还停留在想法阶段,因为强人工智能还没有实现。虽然神经网络、深度学习在模仿大脑,阿法狗也彻底战胜了人类,但电脑依然不能像人一样思考,理解人类的语言,模仿人类的感情。从 Siri 们的智商就能看出来人工智能目前还是人工弱智,但它们在很多细分领域已经赶上甚至超越了人类。像自动驾驶,其实应用的和我一样是计算机视觉的技术,只是更加复杂,训练和调试的方式不太一样。这些人工智能目前的发展,已经可以带来巨大的价值。未来甚至可以想象,把大多数生产活动都交给机器后,可以实现无人化工厂,原料进去,产品出来,中间不需要人类参与。这不就是实现了物质极大化吗?所以人工智能才是最有可能实现共产主义的,虽然人类社会制度的转变总是伴随着战争、冲突、危机等剧痛。
最后谈一谈人工智能导致失业的问题。与其说是失业,我更愿意称之为解放,把人类从机械、重复、无聊的工作中彻底解放出来,让人们把时间用来做有趣的事情,过有意义的生活,而不是把生命浪费在辛勤劳作中。人类发展的历史是生产率不断提高的历史,从工业革命早期的蒸汽机开始,就是不断在用机器替代人力,虽然有经济周期的波折,但这个世界的财富绝对值,人们的平均生活水平是一直提升的。现在很多人恐惧甚至反对人工智能,但这就像当年卢德分子破坏织布机一样是徒劳的;法国的出租车司机抗议 Uber,必然也是在试图逆历史潮流过程中螳臂当车。任何有利于生产力的科技最终都势不可挡。不过强人工智能可能带来伦理性的辩论,但那是另一个更大的话题了。 很多所谓的争议只是短期和长期,局部和全局的区别。自动化的进步短期肯定会造成失业,因为那些工人的就业弹性很低,很难立即找到合适的工作。再加上社会分配制度一般是远远滞后于技术进步,所以会造成贫者越贫富者越富的情况;但从长期来看,这些新技术提升了生产率、资源利用效率,一定是更有利于人类社会。从局部和全局的角度来看,对于新技术直接冲击的行业,像出租车行业,肯定是弊大于利,因为可能造成整个行业的衰退;但对于所有其他人,共享经济让出行变得更便宜、更方便。所以很多纷争,只是所处的立场和时间跨度不同,跳出这些框框才能看清问题的本质。 编辑于 2017-03-12
wanghaisheng
commented
6 years ago wanghaisheng
commented
6 years ago AutoHotkey is a powerful and easy to use scripting language for desktop automation on Windows. https://github.com/Lexikos/AutoHotkey_L
wanghaisheng
commented
6 years ago Facebook's products and services are powered by machine learning. Powerful GPUs have been one of the key enablers, but it takes a lot more hardware and software to serve billions of users.
Most of Facebook's two billion users have little idea how much the service leans on artificial intelligence to operate at such a vast scale. Facebook products such as the News Feed, Search and Ads use machine learning, and behind the scenes it powers services such as facial recognition and tagging, language translation, speech recognition, content understanding and anomaly detection to spot fake accounts and objectionable content.
The numbers are staggering. In all, Facebook's machine learning systems handle more than 200 trillion predictions and five billion translations per day. Facebook's algorithms automatically remove millions of fake accounts every day.
In a keynote at this year's International Symposium on Computer Architecture (ISCA), Dr. Kim Hazelwood, the head of Facebook's AI Infrastructure group, explained how the service designs hardware and software to handle machine learning at this scale. And she urged hardware and software architects to look beyond the hype and develop "full-stack solutions" for machine learning. "It is really important that we are solving the right problems and not just doing what everyone else is doing," Hazelwood said.
Facebook's AI infrastructure needs to handle a diverse range of workloads. Some models can take minutes to train, while others can take days or even weeks. The News Feed and Ads, for example, use up to 100 times more compute resources than other algorithms. As a result, Facebook uses "traditional, old-school machine learning" whenever possible, and only resorts to deep learning--Multi-Layer Perceptrons (MLP), ConvolutionalNeural Networks (CNN), and Recurrent Neural Networks (RNN/LSTM)--when absolutely necessary.
The company's AI ecosystem includes three major components: the infrastructure, workflow management software running on top, and the core machine learning frameworks such as PyTorch.
window.console && console.log && console.log("ADS: queuing inpage-video-top-5b1a205d5e473 for display"); var cbsiGptDivIds = cbsiGptDivIds || []; cbsiGptDivIds.push("inpage-video-top-5b1a205d5e473");
Facebook has been designing its own datacenters and servers since 2010. Today it operates 13 massive datacenters--10 in the U.S. and three overseas. Not all of these are the same since they were built over time and they do not house the same data since "the worst thing you can do is replicate all data in every data center." Despite this, every quarter the company "unplugs an entire Facebook datacenter," Hazelwood said, to ensure continuity. The datacenters are designed to handle peak loads, which leaves about 50% of fleet idle at certains times of the day as "free compute" that can be harnessed for machine learning.
Rather than using a single server, Facebook took hundreds of workloads in production, put them in buckets, and designed custom servers for each type. The data is stored in Bryce Canyon and Lightning storage servers, training takes place on Big Basin servers with Nvidia Tesla GPUs, and the models are run on Twin Lakes single-socket and Tioga Pass dual-socket Xeon servers. Facebook continues to evaluate specialized hardware such as Google's TPU and Microsoft's BrainWave FPGAs, but Hazelwood suggested that too much investment is focused on compute, and not enough on the storage and especially networking, which in keeping with Amdahl's Law can become a bottleneck for many workloads. She added that AI chip startups weren't putting enough focus on the software stack leaving a big opportunity in machine learning tools and compilers.

Facebook's own software stack includes FBLearner, a set of three management and deployment tools that focus on different parts of the machine learning pipeline. FBLearner Store is for data manipulation and feature extraction, FBLearner Flow is for managing the steps involved in training, and FBLearner Prediction is for deploying models in production. The goal is to free up Facebook engineers to be more productive and focus on algorithm design.
Facebook has historically used two machine learning frameworks: PyTorch for research and Caffe for production. The Python-based PyTorch is easier to work with, but Caffe2 delivers better performance. The problem is that moving models from PyTorch to Caffe2 for production is a time-consuming and buggy process. Last month, at its F8 developer conference, Facebook announce that it had "merged them internally so you get the look and feel of PyTorch and the performance of Caffe2" with PyTorch 1.0, Hazelwood said.
This was a logical first step for ONNX (Open Neural Network Exchange), an effort by Facebook, Amazon and Microsoft to create an open format for optimizing deep learning models built in different frameworks to run on a variety of hardware. The challenge us that there are lots of frameworks--Google TensorFlow, Microsoft's Cognitive Toolkit, and Apache MXNet (favored by Amazon)--and the models need to run on a variety of different platforms such as Apple ML, Nvidia, Intel/Nervana and Qualcomm's Snapdragon Neural Engine.
There are a lot of good reasons for running models on edge devices, but phones are especially challenging. Many parts of the world still have little or no connectivity and more than half of the world is using phones dating from 2012 or earlier, and they use a variety of hardware and software. Hazelwood said there is about a 10X performance difference between today's flagship phone and the median handset. "You can't assume that everyone you are designing your mobile neural net for is using an iPhone X," she said. "We are very anomalous here in the U.S." Facebook's Caffe2 Go framework is designed to compress models to address some of these issues.
The deep learning era has arrived and Hazelwood said there are lots of hardware and software problems to solve. The industry is spending lots of time and money building faster silicon but, she said, we need equal investment in software citing Proebsting's Law that compiler advances only double compute performance every 18 years, "Please keep that in mind so we don't end up with another Itanium situation," Hazelwood joked, referring to Intel's non-defunct IA-64 architecture. The real opportunity, Hazelwood said, is in solving problems that no one is working on building end-to-end solutions with balanced hardware and better software, tools and compilers.
wanghaisheng
commented
5 years ago wanghaisheng
commented
5 years ago https://github.com/cbladd/UiPath/wiki/What-is-screen-scraping-and-gui-automation ===Definition=== '''Screen scraping''' is according to Wikipedia "a technique in which a computer program extracts data from the display output of another program. The key element that distinguishes screen scraping from regular parsing is that the output being scraped was intended for final display to a human user, rather than as input to another program, and is therefore usually neither documented nor structured for convenient parsing."
'''GUI automation''' is more or less the opposite of screen scraping. It aims to drive an application to a desired state by simulating mouse and keyboard events like a normal user will do.
===The challenge === Wikipedia continues by shedding light '''on how difficult the scraping''' is from a technological standpoint. "Screen scraping is generally considered an ad-hoc, inelegant technique, often used only as a "last resort" when no other mechanism is available.
Prior to [[Api-documentation|UiPath]], screen scraping solutions were based on employing OCR techniques on screenshots. OCR is traditionally slower, error prone (the best accuracy rates are 95% for typewritten documents), not suitable for applications screens as many UI elements interfere with the OCR algorithms producing undesired results and a good OCR engine is extremely expensive.
GUI automation is no less difficult. One might think that sending mouse and keyboards at screen coordinates is easy but it is not at all reliable. GUI might resize and change position not to speak about different screen resolutions, color depth and font size.
Let's say you need to get the invoice number from your old CRM app to copy into your brand new web based CRM. Old invoice number is displayed as a label in the Customer Invoice screen. You cannot use fixed screen coordinates to scrape it because users might change the position of CRM main window, you cannot use relatively client coordinates because the label might flow if the users change the size of the invoicing window and you cannot use the label handle (hwnd) because it changes between different instances of the app. Same challenge when you want to copy the invoice number, you need to click the input filed prior to send keystrokes but where to click?
===The solution=== The original idea behind UiPath was to intercept and analyze Windows GDI TextOut functions family calls in order to detect the particular text that an application is writing in a given region on the screen. While the idea is clean and nice the implementation is not trivial. It took us 5 years of continuous development to achieve the solid performance of today versions. Our stress test regularly performs 1 million consecutive screen scrapings without any crash or degradation in the system performance.
;What about other technologies that do not use GDI to render text? We support PDF, Flash, Flex, Java, Silverlight, WPF, QT, FoxPro, HTML (IE, Chrome, Firefox), MS Office, Console. For each of these technologies we had to create connectors that understand their internal document object model or use accessibility where available . This is more limited in scope because text layout information is not exposed but it has the advantage to extract entire text from most UI controls and it works even with scrolling or hidden windows.
;Does it cover all scenarios? As the last resort, we have leveraged OCR technology to be able to scrape those screens that display text as images. We took Google Tesseract free OCR engine and tweak it to work with screen fonts. This is not a trivial task in itself as OCR engines works best on scaned paper at higher resolutions. We were able to get 95% accuracy at character level.
;What about text position changing? Here comes [[UiNode]]. It identifies windows or controls based on a plain text [[Selector]] that is calculated from immutable attributes of a window/control like title and class. You can consider it as a query used to match a running instance of a UI object or even better as variable name that points to a real UI object on the screen.
What's best, UiNode provides a single interface that works identical with different UI technologies and different type of UI controls. You program the same against a VB6 or a web and a Java app. All you have to do is to use ScreenScraper Studio to calculate a selector when you design your scraping process and then you can use it to initialize a UiNode that points to the real Ui object on the screen.
Does it solve automation? Well, partly. UiNode is crucial in a good automation because it locates UI elements on the screen with 100% accuracy. The next part of automation is to convinse UI to behave the way we want. What comes immediately to mind is to simulate mouse and keyboard input. We know where is the UI object on the screen so it should be handy to move mouse there and click it. In fact that works beautifully when the app to be automated is in foreground. When the app is not in foreground it is possible to send windows messages or even to use the object model exposed by the Ui framework to perform actions.
wanghaisheng
commented
5 years ago https://github.com/cbladd/UiPath/wiki/Screen-scraping-methods
===Why more scraping methods?=== ScreenScraper offers more than one method of doing screen scraping. It largely depends on the target application technology and your requirements what method works best in a particular case. Read below the pros and cons of each method.
===Native method=== ;Pros :100% accuracy. :Very fast. :Preserves text layout. :Can precisely get the position on the screen of text fragments. :Can get text font and color.
;Cons :Rarely the screen region that is captured flickers. We did a lot of work to ensure minimal or zero flickering but under heavy stress you might notify slight flickering. Usually this is not notifiable by users. :Works only with apps that uses gdi to render text.
===FullText method=== ;Pros :100% accuracy. :Very fast. :No flickering. :Work with most technologies used to create user interfaces including Windows standard SDK, .Net Forms, Java, Flash, WPF.
;Cons :Can get only the whole text of a UI control. :Cannot get text font and color.
===OCR method=== ;Pros :Works on text that is displayed as a bitmap. Most notable type of apps where OCR is the only solution are Citrix presentation manager and Microsoft Remote desktop. :Can precisely get the position on the screen of text fragments.
;Cons :95% accuracy. This can be improved with custom training for specific fonts. Contact us at support@deskover.com for more info. :Slow compared with the other 2 methods though most tasks will take less than half a second.
wanghaisheng
commented
5 years ago http://www.cppblog.com/weiym/archive/2013/12/01/204536.html Windows桌面共享中一些常见的抓屏技术 https://blogs.msdn.microsoft.com/dsui_team/2013/03/25/ways-to-capture-the-screen/ Ways to capture the screen
Capturing the screen (or put another way, creating an in-memory copy of the image currently being displayed on the screen, for re-display, printing, or later saving) is a task with many different solutions. I'll try to enumerate the possibilities below. This isn't a perfect or complete list, but it covers the best supported ways, and lists some of their drawbacks.
1 - Use the Desktop Duplication API. This is a very powerful and full-featured API, which provides access to every frame of desktop update, BUT, it is not available prior to Windows 8.
One drawback is that most full-screen exclusive mode DirectX or OpenGL applications will not be able to be captured with Desktop Duplication. Exclusive mode really means that the ‘Windowed’ field of D3DPRESENT_PARAMETERS is set to false. Some apps are not in true full-screen mode and are windowed, but with the window set to the size of the desktop. These can still be captured.
To make matters a little more confusing, newer DirectX (11.1 and later) exclusive mode apps can be captured with the Desktop Duplication API, unless they "opt-out" and specifically disallow it (in which case they won't be capture-able by Desktop Duplication, just like a pre-11.1 DirectX app).
2 - The old standby, GDI, can still capture the screen. Typically, BitBlt is used. This technique is not perfect, and there are some things, such as multimedia output, that won't get captured.
BitBlt can also can be slow, although you can get much better performance by making sure that the bitmap (that you are capturing into) is the same resolution as the screen. To assure this, you could use CreateCompatibleBitmap (for a device-dependent bitmap), or CreateDIBSection (for a device-independent bitmap). If you use CreateDIBSection, just make sure the bit-depth and layout matches the screen's. This allows BitBlt to avoid any color conversion, which can drastically slow everything down. Here's what such code might look like from a high level...
// Pseudo-code...
HDC hDCScreen = GetDC(NULL);
HDC hDCMem = CreateCompatibleDC(hDCScreen);
HBITMAP hBitmap = CreateCompatibleBitmap(hDCScreen, screenwidth, screenheight);
SelectObject(hDCMem, hBitmap);
BitBlt(hDCMem, 0, 0, screenwidth, screenheight, 0, 0, SRCCOPY);
…
3 - Another option is to use Direct3D. Note that some have reported that this can actually be slower than BitBlt, but performance of any technique will depend a lot on the hardware and graphics settings (regardless of the method used). To do this with Direct3D, you could use GetRenderTargetData to copy the rendering surface (retrieved with GetRenderTarget) to an off-screen surface (which can be created with CreateOffscreenPlainSurface). After copying the surface data this way, you can save the contents of the surface to a file using D3DXSaveSurfaceToFile.
4 - Yet another possibility is to use Windows Media technologies to do the capture (specifically, Expression Encoder will do this if you just need another application). To do it programmatically yourself (using Windows Media), you can use the Windows Media Video 9 Screen codec.
5 - Finally, for pre-Windows 8 systems, you could develop a Mirror Driver to do this (Windows 8 uses another driver model, which is also described under the preceding link).
Some of the above techniques (particularly #2 and #3) can also be used to capture only a single window. Note that iif you use BitBlt to do this, you could "or in" the CAPTUREBLT flag if you wanted to capture windows that are layered on top of your window . The PrintWindow API is another good option for capturing only a single window (not listed above since it can't capture the entire screen).