 wanghaisheng
commented
6 years ago
wanghaisheng
commented
6 years ago 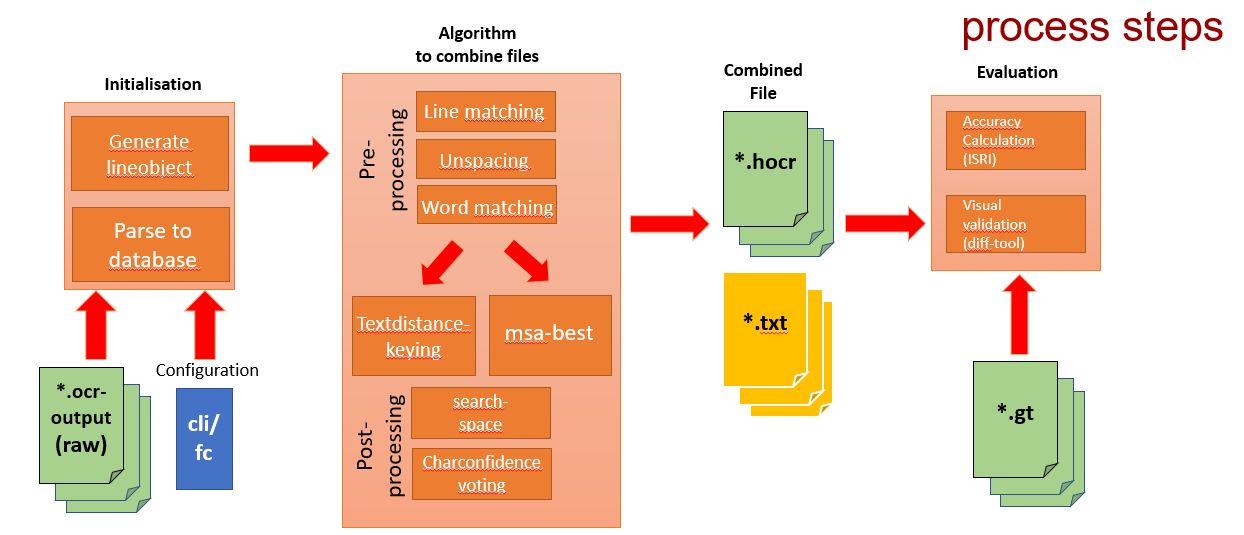
-
Parsing all ocr-outputfiles to an database
(This step only has to be done once) -
Pre-process the gathered information
The results from the following processes can also be stored directly to the database- Line-matching all files
- Unspacing words in each file
Unspacing means to delete whitespaces in spaced text
(E.g. H e l l o => Hello) - Word-matching all files per line
-
Combine file information
- Different compare methods
- Textdistance-Keying
- Levenshtein
- Damerau-Levenshtein
- ...
- Multi-Sequence-Alignment (MSA)
- pivot-based
- linewise/wordwise
- Adjustable search-space-processor correction
- Matching similar character
- Whitespace/Wildcard improvements
- Adjustable decision parameter
- Char confidence
- Best-of-n
- Textdistance-Keying
- Different compare methods
-
The output can be stored in the database and/or as .txt or .hocr.
-
Evaluate the output against groundtruth files or each other and generate a accuracy report. Or compare the files visual via diff-tools.
Process, enhance and evaluate multiple ocr-ouput. https://github.com/UB-Mannheim/ocromore