 werner-duvaud
commented
4 years ago
werner-duvaud
commented
4 years ago About the slow playback (by playback I mean the test function with the visualization in muzero.py), if the steps are long it can be due to the parameters which are too high compared to the hardware, the speed should improve by decreasing the num_simulations parameter in lunarlander.py for example. In the next commit I improved the speed of the test a bit. If you find something that improves performance, don't hesitate to report it.
About using the Tune trainable api, the api seems more suitable for algorithms whose training loop is the main program loop (everything is synchronized from this). Here is the architecture of the code.
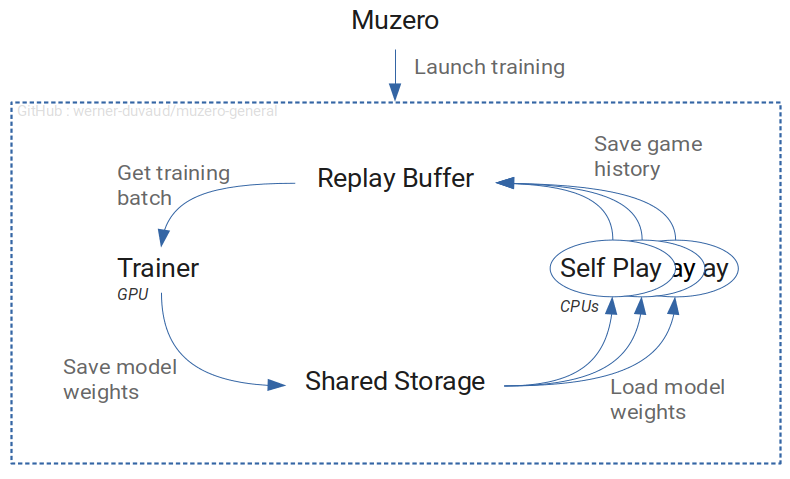
We see that the training part (Trainer) that would be adapted to the trainable API is only a component independent of the rest. In order for the API to work, it would have to include all Muzero; but in this case we would run Muzero classes in parallel which would in turn run components in parallel ... It may be feasible but I think it adds a lot of complexity and it doesn't seem natural to me. In addition I am not an expert with tune, but I am listening for any improvements from this point of view.
However, automatic checkpointing is already implemented. Adding a hyperparameters search is a good idea for future improvement. It is not very complicated to do with the current implementation.
For lunarlander training, it is more difficult and much longer than cartpole because the reward is more rare. In addition I have not yet had time to finely optimize the hyper parameters and the complexity of the network, we are concentrating on the future version for Atari with a ResNet. With the current code, after two hours of training, it shows signs of progress and arrived one time in three to land on the platform. Everything run smoothly on a Linux laptop (CPU: I7 - GPU: GTX 1050Ti). We are planning to run it on a better hardware.
I will improve the weights and parameters in due course. I welcome feedback for the best parameters.
For some reason the playback is really slow (even if I remove the "press enter to continue" prompt).
Also, I'm curious why you didn't implement Trainable interface from ray - it would have enabled a more standardized experience (e.g. ability to run with tune or manully, automatic checkpointing) etc.?
My lunar lander is not training that well yet. Did you manage to get it to work with at least 150-200 reward consistently (e.g. say 100 episodes without dipping below 150)? If so, how long did you train and on what hardware?