 revans2
commented
8 years ago
revans2
commented
8 years ago Yes we are all having the same issue. There appears to be something odd happening with scala 2.11. If you upgarade all of the versions in the pom.xml, not just the shell script, and run mvn dependency:tree you can see that most things were upgraded to 2.11, but there are some dependencies still stuck on 2.10. The flink kafka integration is an example of this. Looking around I was able to find a 2.11 version, but it looks like it is for a much newer version of flink. Then I ran out of time.
If you want to try and play around with upgrading the version of flink to 1.x and along with it hopefully the kafka version. Then look at the spark side as well that would be great.
In the mean time I suggest you try to find/build the older releases of flink and spark then place them in the download cache instead.
 HassebJ
HassebJ
 mmozum
mmozum raj2261992
raj2261992 supunkamburugamuve
supunkamburugamuve apsankar
apsankar Yitian-Zhang
Yitian-Zhang jm9e
jm9e
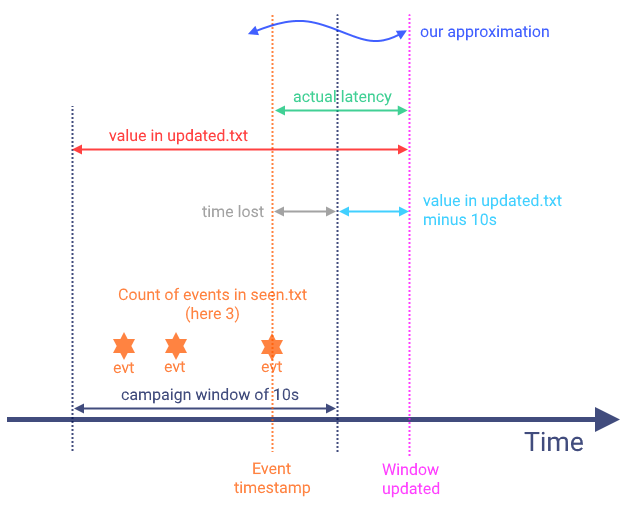
@rmetzger I bumped the versions for Spark, Storm and Flink (also had to modify some pom files) to successfully run benchmarks for all of them but I am having a hard time making sense of the data produced by the benchmarks. Can you please give me some pointers as to how I can use the seen.txt and updated.txt data to generate graphs for the latency characteristics of the frameworks as shown in this post.