 yu3peng
commented
4 years ago
yu3peng
commented
4 years ago NVIDIA GPU 压力测试:nvidia-docker run --rm chrstnhntschl/gpu_burn 180
Open yu3peng opened 4 years ago
yu3peng
commented
4 years ago NVIDIA GPU 压力测试:nvidia-docker run --rm chrstnhntschl/gpu_burn 180
yu3peng
commented
4 years ago yu3peng
commented
4 years ago 一个 MFLOPS (megaFLOPS) 等于每秒1百万 (=10^6) 次的浮点运算 一个 GFLOPS (gigaFLOPS) 等于每秒10亿 (=10^9) 次的浮点运算 一个 TFLOPS (teraFLOPS) 等于每秒1万亿 (=10^12) 次的浮点运算 一个 PFLOPS (petaFLOPS) 等于每秒1千万亿 (=10^15) 次的浮点运算
yu3peng
commented
4 years ago VGPU 技术是用来提高虚拟机的浮点运算、并行计算能力,对虚拟机图像的远程输出到终端上的流畅程度没有实质性的帮助。云主机云服务注重的是运算能力;云桌面注重的是前端桌面的交互体验,所有的远程桌面传输协议都对图像进行了有损压缩,远端虚拟机输出的帧通过网络传输到终端(盒子)时图像实际已经进行了裁减;即使后端虚拟机上的VGPU渲染了一张4K 的32位真彩图像,通过远程桌面传输协议回显(终端盒子收到加密压缩的数据后把数据还原成图像) 到终端显示器上被用户肉眼看到之时其实已经是缩水后的复刻品。 其于VDI 的云桌面在高密集图像处理方面表现不佳其瓶颈也并不在后端的GPU不足,而且网络传输的损失与前端能力的不足。在窄带宽与瘦终端环境表现得更明显。
yu3peng
commented
4 years ago # NVIDIA & Container # 浅谈 docker 挂载 GPU 原理
docker run --device /dev/nvidia0:/dev/nvidia0 --device /dev/nvidiactl:/dev/nvidiactl --device /dev/nvidia-uvm:/dev/nvidia-uvm --device /dev/nvidia-uvm-tools:/dev/nvidia-uvm-tools --device /dev/nvidia-modeset:/dev/nvidia-modeset -v /usr/bin/:/usr/bin -v /usr/lib64:/usr/lib64 -it tkestack/vcuda:1.0 bash
yu3peng
commented
4 years ago # NVIDIA & Container # Docker >= 19.03 docker run --gpus all,capabilities=utilities nvidia/cuda nvidia-smi
yu3peng
commented
4 years ago # NVIDIA & Container # 容器中需要挂载的NVIDIA文件,具体信息可以参考tencent gpu-manager 挂载配置文件,其中 libcuda-control.so 文件来源于dockerhub 上 tencent vcuda容器中的 usr\lib64\libcuda-control.so文件
yu3peng
commented
4 years ago # NVIDIA FAQ #
Q: /dev/nvidia-uvm: no such file or directory.
A:
sudo /sbin/modprobe nvidia-uvm
D=`grep nvidia-uvm /proc/devices | awk '{print $1}'`
sudo mknod -m 666 /dev/nvidia-uvm c $D 0
ls /dev/nvidia*https://www.machunjie.com/trouble/88.html
Q: /dev/nvidia-uvm-tools: no such file or directory
A:
sudo mknod -m 666 /dev/nvidia-uvm-tools c $(grep nvidia-uvm /proc/devices | awk '{print $1}') 1# 推荐算法 # 基于Slope One的推荐引擎
# 推荐算法 # 复杂算法转化为简单算法,高阶算法转化为低阶算法
yu3peng
commented
4 years ago yu3peng
commented
4 years ago yu3peng
commented
4 years ago yu3peng
commented
4 years ago yu3peng
commented
4 years ago yu3peng
commented
4 years ago yu3peng
commented
4 years ago 老黄刀法:
电脑这玩意里面有两个科幻无比的东西,人类的智慧结晶:CPU、GPU。
你也可以叫它CPU和显卡。CPU负责什么?那可就……不重要。
电脑这玩意有显示器,光一个CPU电脑可运行不到桌面,所以部分CPU会集成显卡,也就是"核显",它确保你的电脑可以运行到桌面并且让显示器显示出来内容。
那有的人呢,肯定是不满足于看视频、看小说、听音乐、上上网,电脑嘛,不能打游戏那能叫电脑吗?但是游戏呢,它的运算量不小,比如一个正方体,它有6个面,每个面什么颜色,长宽高多少。如果画个圆球呢?计算量就更大了。
还别说得计算这个球往地上一扔会朝哪里滚,滚动的过程你也得画出来吧?所以要把游戏"画出来"是一件很复杂很复杂的事,那么多小人、建筑、枪车球的都得显示出来。
"核显"说:哥,我一分钟只能算一个1+1=2,你让我算2+2=4我算不过来啊!
因此有了独立显卡,独显。独显块头大,力气大,跑的也快。
独显说:小弟你歇着,我来。
歘歘歘,一副立体的画面就跃然于屏幕之上。
但是呢,游戏也是越来越复杂,以前呢,可能就是超级马里奥就很好玩了,后来呢?得玩英雄联盟、王者荣耀,最开始的独显也应付不过来了,这时候,跑出来四个哥们,一起吼道:我来!这四个哥们呢,是老黄家得,可能分别叫X50、X60、X70、X80。
这时候又有两个概念:分辨率、帧率。你要是用10年前的手机看片,是不是一坨马赛克?你用现在上千的手机看片,好清晰啊。
横着2个灯,竖着2个灯,组成一个屏幕,你啥都看不清;但是横着1920个灯,竖着1080个灯,组成一个屏幕,就很清晰了,这就是分辨率。
另一个帧率呢,翻页动画见过没,你把100张纸上画个小人,每一张略微动一丁点,连续着翻看,小人就动起来了,那么一秒钟你要是只翻一张,你就觉得:怎么这么卡?所以你一秒钟翻60页,动画瞬间流畅!
X50小弟说:这个游戏啊,这个低分辨率的,我能达到30帧/秒,啊,勉强能玩。
X60说:这游戏啊,中等分辨率,我能50帧/秒,玩起来还不错。
X70跳出来:超高清分辨率,60帧/秒,又清晰又流畅,爽快。
X80躺在那:4K超级无敌爆炸分辨率,120帧/秒,享受。
所以这四兄弟分别对应999块、1999块、3999块、6999块。
这时候,突然你跑出来,说我家这R58的身材,能2599给你接近X70的体验(虽然实际可能差一些)。
老黄家的四兄弟一看,不好!这人是来捣乱的!X70你看,委屈你一下,砍你一刀行不?
X70咬咬牙:好,听老爸你的。
咔嚓一刀,X65出来了,2499块!比你X58便宜100!性能和你一样!
你一看,我去,我还没开始卖呢,你这X65卡的档位,比我便宜还比我好一丁点,我这R58怎么卖?卖不出去都砸手里了呀!
这就是黄氏刀法。
yu3peng
commented
4 years ago 老黄两弹功勋:
...因为超频后的英伟达显卡经常导致买家们的主板、电源全损,运气不好的内存都被烧掉。所以,在那些玩家看来,他的显卡成了一枚“ 战术核弹 ”。当然, “ 核弹狂魔 ” 这个名号,怎么会如此简单降临到一个人类身上?
相对于他的产品,其实老黄的脾气更像是一枚核弹。他被称为IT届最好斗的人,硅谷一霸,并且从不怕得罪任何人。。。
据不完全统计,黄仁勋得罪过AMD、Intel、微软、苹果、讯景等大型企业。
由于老黄他 “ 桀骜不驯 ” 的显卡,几乎得过罪所有的游戏厂商。
因为这些游戏厂商的游戏,在他的显卡配置下,要么跑不动,要么游戏效果不理想。。。
曾经,许多玩家反映,老黄最新的N卡带不动北软(即北京软星科技有限公司)开发的游戏 “ 仙剑奇侠传六 ” 。
以自身产品为自豪的老黄顿时感觉面上无光、气急败坏,扬言要炸掉北软的公司。。。
yu3peng
commented
4 years ago yu3peng
commented
4 years ago yu3peng
commented
4 years ago 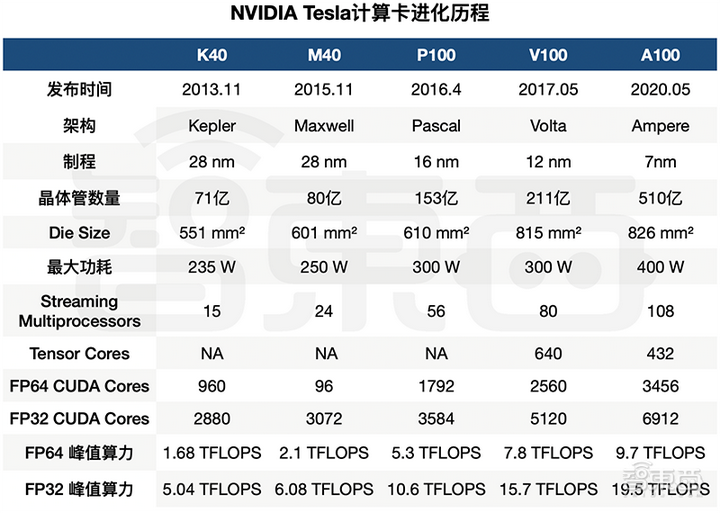
yu3peng
commented
4 years ago yu3peng
commented
4 years ago yu3peng
commented
4 years ago yu3peng
commented
2 years ago yu3peng
commented
2 years ago
https://www.y2p.cc/notes/gpu/