 ysh329
commented
2 years ago
ysh329
commented
2 years ago 异步计算的意义
现代 GPU 有多个队列,通过队列提交任务给着色器(Shader Core)处理。桌面级 GPU 和 Arm Mali GPU 在队列执行拓补结构上不同,这也导致了在异步方法的实现上二者的差异。下面,我们先分析传统桌面 GPU 和 Arm Mali GPU 的架构差异。
桌面级 GPU 的队列任务流程
传统桌面 GPU 架构的渲染模式属于 立即模式 (Immediate Mode),立即模式下渲染流程会严格地按照命令队列的方式执行:在每个图元(primitive)上的每次绘制调用(draw call)中,以顺序地方式执行顶点和片段着色器(vertex and fragment shaders)的工作负载。
渲染是从 2D 或 3D 模型借助计算机程序生成现实世界的真实或非非真实图像的过程。渲染也是图形流水线的最后一个主要步骤,让模型或者动画得到最终的外观呈现。
这个流程以伪代码的形式表示即为:
for draw in renderPass:
for primitive in draw:
for vertex in primitive:
execute_vertex_shader(vertex)
if primitive not culled:
for fragment in primitive:
execute_fragment_shader(fragment)这里的绘制调用(draw call)为 GL 的描绘次数,也可称为一条用来渲染网格的命令,这条命令由 CPU 发出,并被 GPU 接收。GL 绘图一般次序为:设置颜色——绘图方式——顶点坐标——绘制——结束。每帧会重复该过程,该过程就是一次draw call。即上述伪代码中的 renderPass的一次draw。
网格(Mesh)代表一个可绘制实体,一般来说,Mesh 指 3D 模型的网格,由多边形拼接而成的,复杂多边形由多个三角面拼接而成的。所以一个 3D 模型的表面是由多个彼此相连的三角面构成的,三维空间中,构成这些三角面的点以及三角形的边的集合就是 Mesh,在OpenGL中我们可以定义网格(Mesh)类结构体,其成员可以是多个顶点(Vertex)结构体的组合,而顶点(Vertex)是包含了位置、纹理坐标等信息的结构体。
draw call命令发出后,GPU 使用 Render State(材质、纹理、着色器)和所有顶点数据(这些数据就是下图中的Atrtibutes和Textures),通过代码魔法将这些信息转换为屏幕上的彩色像素,这个转换过程也被称为 Pipeline(流水线,或者别扭的直译叫法“管线”) 。该过程简化用下图表示,中间如栅格化(rasterization,表示将计算机图形学中的向量图形转换成像素阵列,即位图的过程)等操作略过:

上图分为三部分,第一行为 GPU 这一侧的处理,第三行为主机端数据,中间的第二行为数据交互流向。其中,蓝色为硬件单元,橘色为数据结构,绿色为数据。渲染流程为:主机端将图元的属性信息数据通过 DDR 发给 GPU,并交给顶点着色器处理,用于处理如几何变换、灯光等如一个矩形的四个顶点即顶点着色器会被调用四次,其处理结果以先进先出的队列数据结构保存,并交给片段着色器(Fragment Shader)处理,Fragment Shader 的工作内容很多,包括不限于每个像素的最终颜色等属性。Fragment 是可被渲染到屏幕上的像素点。
总之,上面,在桌面级GPU硬件上,渲染队列通常是两种组成。因为文中说的不清楚,我的理解是:有两个串行的队列,分别有其硬件实现,对应是上图的 Vertex Shader 和 Fragment Shader。Vertex Shader 是处理计算负载任务,即COMPUTE Queue,而 Fragment Shader 是 GRAPHICS Queue:
- 1个单独(lone)的图形 (Grahpics) 队列:什么类型的任务都可以做,来者不拒,这个队列很可能很长,在图上表示为第一行(GPU)的 Fragment Shader的工作;
- N个(许多个)仅计算(Compute)的队列:只能做计算任务负载,在图上表示为第一行(GPU)Vertex Shader的工作。
这么看,传统桌面级 GPU 两个串行队列的立即模式下,非常低效。这里也科普一下这种最早的立即模式渲染(Immediate Mode Rendering,IMR)。
传统桌面 GPU(nVIDIA,AMD)都是IMR架构,在移动领域,nVIDIA 的 GeForce ULP 和 Vivante 的 GC 系列 GPU 都是属于 IMR 架构。IMR 架构的 GPU 渲染完物体后,都会把结果写到系统内存中的帧缓存里(FrameBuffer,见上图的Framebuffer Working Set),因此就可能出现 GPU 花了大量的时间渲染了一个被遮挡的看不见的物体,而最后这些结果在渲染完遮挡物后被覆盖,做了无用功。这个问题称之为 Overdraw。
虽然现代的 IMR 架构 GPU 在一定程度上可以避免这个问题,因为后续又有了 TBR (Tlie Based Rendering)架构,但要求应用程序将场景里的三角形按照严格的从前往后的顺序提交给 GPU,要完全避免 Overdraw 还是很困难的,当然后续的TBDR(Tile Based Deferred Rendering)架构完全避免了这个问题,是后话了。

 图:TBR Pipeline(来自 PowerVR 的 TBR 架构)
图:TBR Pipeline(来自 PowerVR 的 TBR 架构)

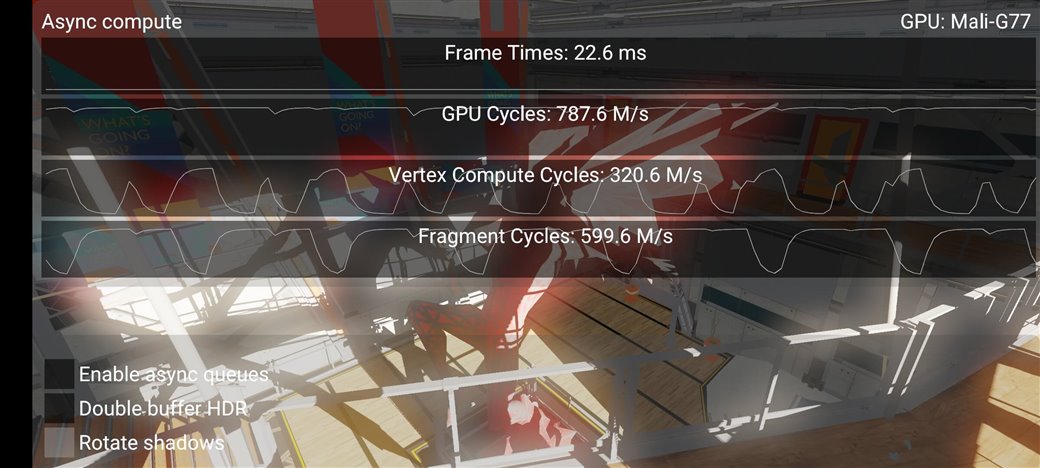
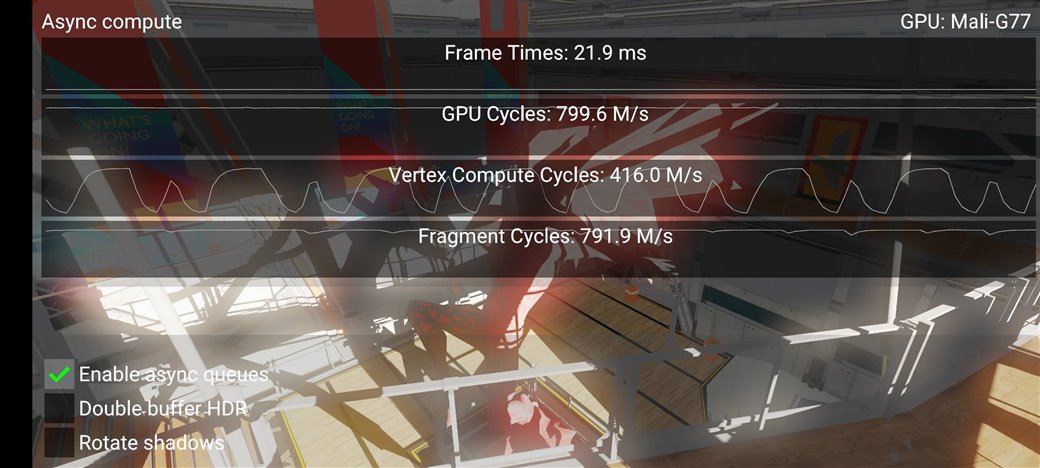
在Arm Mali GPU上使用异步计算:附实践代码
异步计算技术确实是效果拔群的性能优化杀器,但难于在项目中落地。异步计算始于上一代控制台硬件(Console Hardware),就是游戏主机时代,在后来的现代图形 API(如 Vulkan 和 D3D12)上逐步体现,目前异步计算已是图形程序员的常用工具。
本文将展示一个新的 Vulkan 示例,该示例代码也已更新到了 Github KhronosGroup 下的 Vulkan-Sample 仓库中,其演示了如何使用异步计算,感兴趣的同学也可以看看这篇 《使用异步计算技术榨干GPU资源》。
严格来说,"异步计算"(Async compute)本身不一种技术,它只是通过一次同时向 GPU 提交多个命令流(multiple streams of commands)来有效利用现代 GPU 可用的硬件资源的策略。咱们后文会具体展开来讲,因为把异步计算用起来,确实需要一定的专业知识。