Issue: Finetuning PSALM Model for Anomaly Detection
I'm working on finetuning the PSALM model after stage 2 for an anomaly detection task on my own dataset, which consists of two categories: 1. Defective 2. Good
Issue Description
During the evaluation stage, I find that the model always outputs all 0 for panoptic_seg without segments_info.
I have constructed three test demos:
①The training set contains only one category (category2 -> good).
panoptic_train2017.json:
(all the segments_info is the same)
images in train2017(input):
images in panoptic_train2017 and panoptic_semseg_train2017:
(Totally black -> only category2)
panoptic_val2017.json:
PS:
① if an image is "defective" then it has the ground_truth mask with 2 categories (black and white)
if an image is "good" then it has the ground_truth mask only with 1 category (totally black)
② "id": 16777215 = 255 + 255 256 + 255 256^2 (rgb2id in panoptic_api)
images in val2017:
(it's a Defective image)
images in panoptic_val2017
(black means it's good, white means it's defective)
def train():
global local_rank
parser = transformers.HfArgumentParser(
(ModelArguments, DataArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
local_rank = training_args.local_rank
compute_dtype = (torch.float16 if training_args.fp16 else (torch.bfloat16 if training_args.bf16 else torch.float32))
mask_cfg = get_mask_config(config=model_args.mask_config)
mask_cfg.MODEL.MASK_FORMER.SEG_TASK = model_args.seg_task
bnb_model_from_pretrained_args = {}
print('using model PSALM')
# model_name = get_model_name_from_path(model_path)
# model_args.model_map_name =
model_args.model_map_name = 'psalm'
tokenizer, model, image_processor, context_len = load_pretrained_model(model_args.model_name_or_path, None,'psalm',mask_config=model_args.mask_config,model_args=model_args)
data_args.image_processor = image_processor
data_args.is_multimodal = True
# if not training_args.bf16:
#Load PSALM model
# model = PSALM.from_pretrained(
# model_args.model_name_or_path,
# mask_decoder_cfg=mask_cfg,
# add_cross_attn=True,
# cache_dir=training_args.cache_dir,
# **bnb_model_from_pretrained_args
# )
# if not model.is_train_mask_decode:
# mask2former_ckpt = model_args.vision_tower if model_args.load_mask2former else None
# model.initial_mask_module(mask2former_ckpt)
model.config.use_cache = False
#Decide whether to freeze the backbone
if model_args.freeze_backbone:
model.model.requires_grad_(False)
# Free the projector
for param in model.get_model().mm_projector.parameters():
param.requires_grad = False
# Freeze vision_tower parameters
for param in model.get_model().vision_tower.parameters():
param.requires_grad = False
#Decide whether use the gradient_checkpointing
if training_args.gradient_checkpointing:
if hasattr(model, "enable_input_require_grads"):
model.enable_input_require_grads()
else:
def make_inputs_require_grad(module, input, output):
output.requires_grad_(True)
model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
model_max_length=training_args.model_max_length,
padding_side="right",
use_fast=False,
)
if tokenizer.pad_token is None:
smart_tokenizer_and_embedding_resize(
special_tokens_dict=dict(pad_token="[PAD]"),
tokenizer=tokenizer,
model=model,
)
if model_args.version in conversation_lib.conv_templates:
conversation_lib.default_conversation = conversation_lib.conv_templates[model_args.version]
else:
conversation_lib.default_conversation = conversation_lib.conv_templates["vicuna_v1"]
# Delete the code that loads vision_tower and mm_projector
tokenizer.add_tokens("[SEG]")
model.resize_token_embeddings(len(tokenizer))
model.get_special_token(SEG=tokenizer("[SEG]", return_tensors='pt', add_special_tokens=False)['input_ids'], EOS=tokenizer.eos_token_id)
data_module = make_unify_datamodule(tokenizer=tokenizer, data_args=data_args, training_args=training_args)
training_args.dataloader_drop_last = True
trainer = LLaVATrainer(model=model,
tokenizer=tokenizer,
args=training_args,
**data_module)
if list(pathlib.Path(training_args.output_dir).glob("checkpoint-*")):
trainer.train(resume_from_checkpoint=True)
else:
trainer.train()
trainer.save_state()
model.config.use_cache = True
# Delete the code that check whether using lora
safe_save_model_for_hf_trainer(trainer=trainer,output_dir=training_args.output_dir)
if __name__ == "__main__":
train()
load data:
def make_unify_datamodule(tokenizer, data_args, training_args):
panoptic_coco_dataset = COCO_panoptic_dataset_random(json_path=data_args.panoptic_json_path, tokenizer=tokenizer,
data_args=data_args)
datasets = [panoptic_coco_dataset]
# you can change 16 to your frequency sets, it represents how many samples to change tasks
train_dataset = UnifyDatasetSingleDatasetForBatch(datasets,16,fix_dataset_len=data_args.fix_dataset_len)
print(f'total unify dataset number is {len(train_dataset)}')
data_collator = DataCollatorForCOCODatasetV2(tokenizer=tokenizer)
return dict(train_dataset=train_dataset, eval_dataset=None, data_collator=data_collator)
PS: only use panoptic_coco_dataset for task1 in the paper
Issue: Finetuning PSALM Model for Anomaly Detection
I'm working on finetuning the PSALM model after stage 2 for an anomaly detection task on my own dataset, which consists of two categories: 1. Defective 2. Good
Issue Description
During the evaluation stage, I find that the model always outputs all
0forpanoptic_segwithoutsegments_info.I have constructed three test demos:
①The training set contains only one category (category2 ->
good).panoptic_train2017.json:
(all the segments_info is the same)
images in train2017(input):
images in panoptic_train2017 and panoptic_semseg_train2017:
(Totally black -> only category2)
panoptic_val2017.json:
PS:
① if an image is "defective" then it has the ground_truth mask with 2 categories (black and white)
if an image is "good" then it has the ground_truth mask only with 1 category (totally black)
② "id": 16777215 = 255 + 255 256 + 255 256^2 (rgb2id in panoptic_api)
images in val2017:
(it's a Defective image)
images in panoptic_val2017
(black means it's good, white means it's defective)
finetune.sh(based on tranin.sh):
finetune.py(based on train.sh):
load data:
PS: only use panoptic_coco_dataset for task1 in the paper
training process info:
evaluation command:
panoptic_evaluation.py:
just add "print" to output the info
modify the code inside process()
PS: ①print panoptic_img and segments_info
②save the panoptic_img converted by id2rgb to the specific folder
evaluation process:
(without segments_info)
PS: ①if the training set is with the mask which is all with category 1, it works like this:
(sometimes it has segments_info and sometimes it doesn't)
②if the mask is all with category 3, it doesn't work:
panoptic_train2017.json: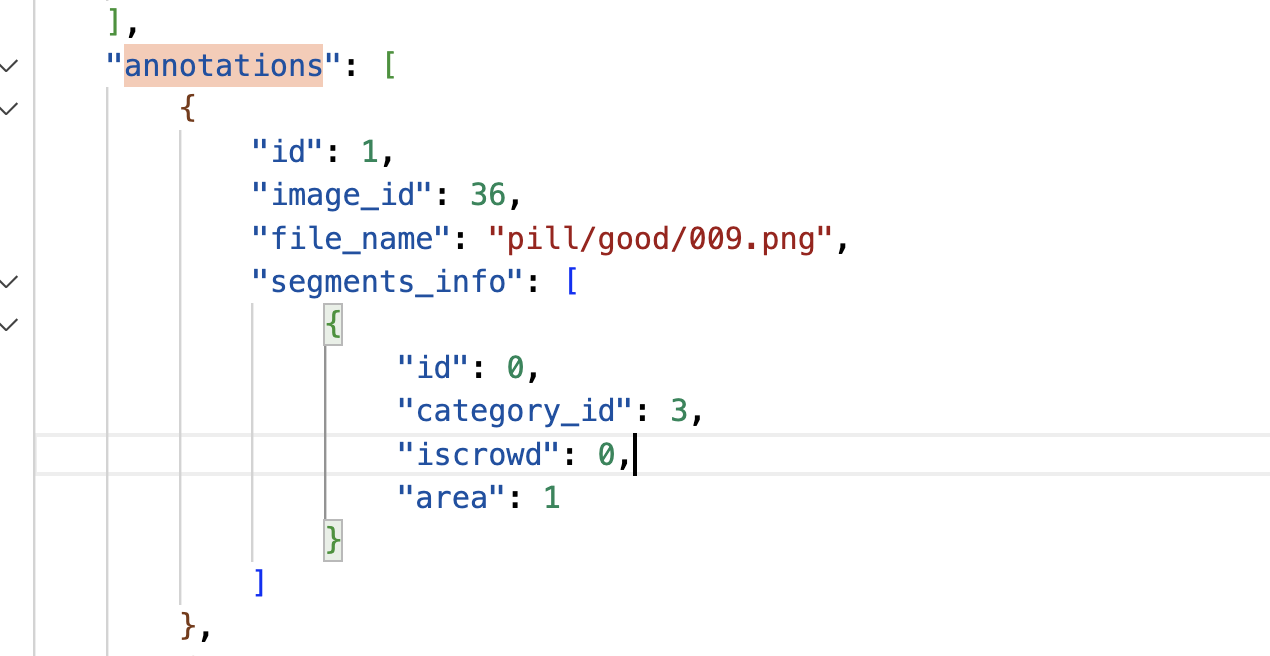
②The training set containing 2 categories with the left half side as gray and right half side as white
......
③The training set containing only one category1
......