 zhaoyingjun
commented
5 years ago
zhaoyingjun
commented
5 years ago 你看一下你进行转换后的语料,里面是不是有很多的3 或者表情符号,表情符号代表UNK的词,你调大一下字典的大小就可以了
Open PanDengStudio opened 5 years ago
zhaoyingjun
commented
5 years ago 你看一下你进行转换后的语料,里面是不是有很多的3 或者表情符号,表情符号代表UNK的词,你调大一下字典的大小就可以了
 PanDengStudio
commented
5 years ago
PanDengStudio
commented
5 years ago 默认2w,我之前用的4w,调到多大才合理?
PanDengStudio
commented
5 years ago GAN训练转换语料全是3是怎么回事?
zhaoyingjun
commented
5 years ago 你看一下data_utils这里,应该是没有做好语料词典转换
 daniellibin
commented
5 years ago
daniellibin
commented
5 years ago 你好,我的回答也全是表情符号。请问有没有训练好的模型分享一下,谢谢。
 Iron-head
commented
4 years ago
Iron-head
commented
4 years ago GAN训练转换语料全是3是怎么回事?
你好,我也遇到这个问题了,请问你是怎么解决的,求分享,谢谢
 Leii
commented
4 years ago
Leii
commented
4 years ago 你看一下你进行转换后的语料,里面是不是有很多的3 或者表情符号,表情符号代表UNK的词,你调大一下字典的大小就可以了
您好 我也遇到这个问题,出来的结果都是å ¯ 或者= 请问要怎么解决?
daniellibin
commented
4 years ago 你看一下你进行转换后的语料,里面是不是有很多的3 或者表情符号,表情符号代表UNK的词,你调大一下字典的大小就可以了
您好 我也遇到这个问题,出来的结果都是å � ¯ 或者= 请问要怎么解决?
你好,请问有没有训练好的模型,能不能分享一下呢,谢谢~
daniellibin
commented
4 years ago GAN训练转换语料全是3是怎么回事?
你好,我也遇到这个问题了,请问你是怎么解决的,求分享,谢谢
你好,你的模型训练怎么样啦,效果可以吗?
 prozyworld
commented
4 years ago
prozyworld
commented
4 years ago 请问一下 返回的全是表情符号 应该改哪里
 huxianhe0
commented
4 years ago
huxianhe0
commented
4 years ago 同问,这个问题半年了,现在跑出来还是都是UNK,在execute.py中outputs始终为[3, 3, 3],问题出在哪里呢
huxianhe0
commented
4 years ago 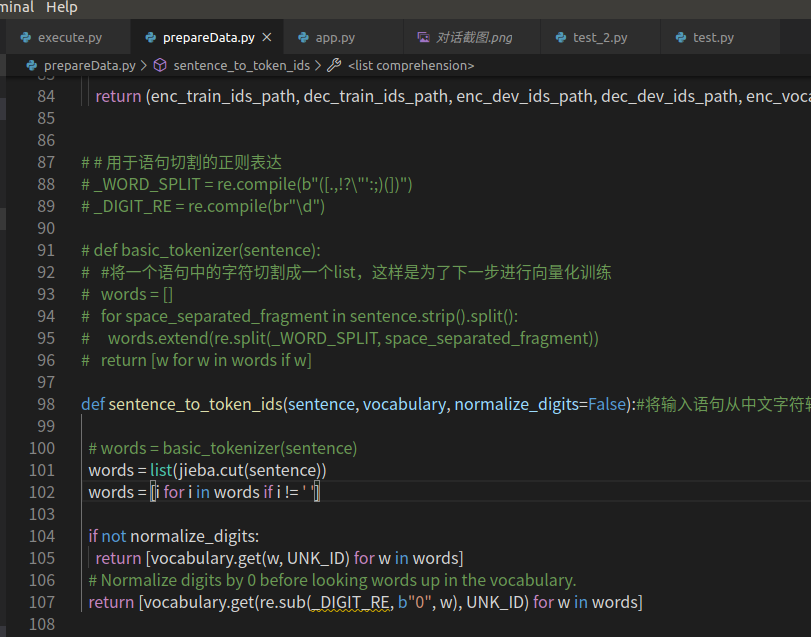
我做了两点改动: (1)分词的basic_tokenizer改成了jieba方法,normalise_digits改成了false; (2)data_utils.py 中改成UTF-8, with open(conv_path,encoding='UTF-8') as f: 改动后一切结果正常,但语料库太弱了,只能用作demo练练手,想变成工程项目的话必须重新制作或购买语料库
 Arbre57
commented
4 years ago
Arbre57
commented
4 years ago
我做了两点改动: (1)分词的basic_tokenizer改成了解霸方法,normalise_digits改成了假; (2)data_utils.py中改成UTF-8,打开时(conv_path,encoding ='UTF-8')为f: 放置后一切结果正常,但语料库太弱了,只能使用demo练练手,想变成工程项目的话必须重新制作或购买语料库
能说具体一点在哪改动的吗,谢谢啦
 hujianhang2996
commented
4 years ago
hujianhang2996
commented
4 years ago
基于之前的电影语料,训练600w次,也是只回答固定的毫无逻辑的话或者表情符号 换了黄鸡语料也只回答简单的表情符号或者=号 求问需要参数特殊设置吗? 以及黄鸡训练成如图的效果花了多久时间? (我是基于windows开发的,将遇到的gbk问题都改为了utf-8)