 zhouwg
commented
3 months ago
zhouwg
commented
3 months ago breakdown task(gradual refinement through Agile method and any help(from AI expert, from upstream GGML community, from Qualcomm, ......) are both greatly welcomed. Guidance from domain-expert is greatly appreciated if there is a problem in path/direction of breakdown task):
-
PoC-S1:
- PoC-S11: background study of Qualcomm QNN SDK
- PoC-S12: model convert tool in python: GGUF ---> Qualcomm's dedicated format (I'm not sure whether this step is essential for the PoC or it's my misunderstanding?) updated on 03-31-2024,17:00, **could be skipped** because: 
- PoC-S13: integrate GStreamer to this project because GStreamer is not only a powerful multimedia framework in Linux and also officially supported by many semiconductor company(such as Intel, Qualcomm, NVIDIA, NXP......) (updated on 03-29-2024,21:48, this should be a **direction problem** caused by my streaming-media background. GStreamer might be not suitable/appropriate for this PoC, this step **could be removed** accordingly)
-
PoC-S2&S3: "play" with QNN SDK(S2) and study internal detail of GGML(S3)
- PoC-S21: initial development env for "play" with QNN SDK on Xiaomi14(done)
- PoC-S22: integrate QNN sample code to ggml-jni and make the data path works fine as expected(data path: UI <---> Java <---> ggml-jni <---> QNN SDK <---> CPU) (done)
- PoC-S23: integrate QNN sample code to ggml-jni and make the data path works fine as expected(data path: UI <---> Java <---> ggml-jni <---> QNN SDK <---> GPU) (done)
- PoC-S24: integrate QNN sample code to ggml-jni and make the data path works fine as expected(data path: UI <---> Java <---> ggml-jni <---> QNN SDK <---> DSP) (updated on 04-19-2024, done)
- PoC-S25: build code skeleton(Java layer and native layer) of stage-2 of PoC(done)
- PoC-S26: offload simple f32 2x2 matrix addition operation to QNN CPU backend(milestone, done on 04-07-2024(April-7,2024), 17:30)
- PoC-S27: offload simple f32 2x2 matrix addition operation to QNN GPU backend(done on 04-08-2024)
- PoC-S28: offload simple f32 2x2 matrix addition operation to QNN DSP(HTA) backend(skip on 04-08-2024, because it relies heavily on Qualcomm('s undocumented doc/lib?) and there are more valuable/important things in next steps, this problem will be solved in next stage. updated on 04-19-2024, done)
- PoC-S29: mapping ggml_tensor and a simple GGML OP(matrix addition operation) to QNN tensor & computation graph & CPU backend and get correct result(done on 04-08-2024)
- PoC-S30: mapping ggml_tensor and a simple GGML OP(matrix addition operation) to QNN tensor & computation graph & GPU backend and get correct result(done on 04-08-2024)
- PoC-S31: mapping ggml_tensor and a simple GGML OP(matrix addition operation) to QNN tensor & computation graph & DSP backend and get correct result(skip on 04-08-2024, because it relies heavily on Qualcomm and there are more valuable/important things in next steps, this problem will be solved in next stage. updated on 04-19-2024, done)
- PoC-S32: mapping ggml_tensor and GGML mulmat to QNN tensor & computation graph & CPU backend and get correct result(done on 04-08-2024)
- PoC-S33: mapping GGML mulmat to QNN GPU backend(done on 04-08-2024)
- PoC-S34: mapping GGML mulmat to QNN DSP backend(skip on 04-08-2024, because it relies heavily on Qualcomm and there are more valuable/important things in next steps, this problem will be solved in next stage. updated on 04-19-2024, done)
- PoC-S35: mapping a complicated GGML computation graph to QNN's computation graph(CPU/GPU backend) and get correct result
- PoC-S36: mapping a complicated GGML computation graph to QNN DSP backend and get correct result(skip on 04-08-2024, because it relies heavily on Qualcomm and there are more valuable/important things in next steps, this problem will be solved in next stage. updated on 04-19-2024, done )
- PoC-S37: study the online AI course from Andrew Ng and Mu Li(I prefer Chinese version for more quickly reading, the English version: https://github.com/d2l-ai/d2l-en), study what's the neural network, study how to implement a simple neural network in C/C++ and then mapping to GGML and then mapping to QNN CPU/GPU backend and get correct result(this step is equal to PoC-S35 actually. updated on 04-10-2024-23:25 after reading online AI course from Andrew Ng & Mu Li very roughly and study more internal mechanism of ggml, this step could be skipped actually although I already know how to do it(I'll submit the source code of PoC-S37 later). thanks to the highly well-designed QNN SDK again, it's really too match with the well-designed ggml)
-
PoC-S4: real challenge in this PoC, current data path of GGML inference on Qualcomm mobile SoC based Android phone: UI <---> Java <----> ggml-jni <---> whisper.cpp < ---> ggml <--->CPU
- PoC-S41: HLD(high level design) of data path: UI <---> Java <---> ggml-jni < ---> whisper.cpp < ---> ggml <---> ggml-qnn.cpp < ---> QNN CPU backend < ---> CPU (updated on 04-10-2024,23:24, there are not too much HLD work need to do because the well-designed ggml already does it internally. updated on 04-11-2024,23:53, done, thanks to the Intel SYCL backend from a small R&D team in Intel Shanghai branch, I'd like to thanks Qualcomm's highly well-designed QNN SDK again, it's a really ONE SDK)
- PoC-S42: implementation of datapath using QNN CPU backend: UI <---> Java <---> ggml-jni < ---> whisper.cpp < ---> ggml <---> ggml-qnn.cpp < ---> QNN(CPU backend) < ---> CPU(milestone, updated on 04-13-2024, done, data path works as expected with whisper.cpp)
- PoC-S43: implementation of major GGML OP(mulmat) using QNN API in ggml-qnn.cpp(04-15-2024, works but with a minor unknown bug, updated on 04-16-2024, the issue had been fixed)
- PoC-S44: implementation of datapath using QNN GPU backend: UI <---> Java <---> ggml-jni < ---> whisper.cpp < ---> ggml <---> ggml-qnn.cpp < ---> QNN(GPU backend) < ---> CPU(updated on 04-16-2024, done, works as expected with whisper.cpp at the first time. just a workaround method and did not find out the root cause of crash. updated on 04-17-2024, done with a better method)
- PoC-S45: validation of major GGML OP(mulmat) using QNN GPU backend(done, updated on 04-17-2024)
- PoC-S46: implementation of datapath using QNN DSP backend: UI <---> Java <---> ggml-jni < ---> whisper.cpp < ---> ggml <---> ggml-qnn.cpp < ---> QNN(DSP backend) < ---> CPU. will fix the unsolved problem in PoC-S28, PoC-S31, PoC-S34, PoC-S36... in this step (updated on 04-17-2024, skipped, because QNN HTP(aka DSP) backend heavily depend on vendor's Android OS(Xiaomi, Vivo's customized OS based on Qualcomm's BSP. updated on 04-19-2024, done)
- PoC-S47: validation of major GGML OP(mulmat) using QNN DSP backend(updated on 04-17-2024, skipped, because QNN HTP(aka DSP) backend heavily depend on vendor's Android OS(Xiaomi, Vivo's customized OS based on Qualcomm's BSP. updated on 04-19-2024, done)
- PoC-S48: validate PoC-S42/PoC-S44/PoC-S46(aka QNN backend) by whisper.cpp asr benchmark or real-time subtitle (updated on 04-13-2024, data path works fine as expected, asr result is not correct because lack of implementation of other GGML OPs using QNN API. updated on 04-17-2024, done, QNN backend(CPU&GPU) works fine/well with whisper.cpp asr benchmark at the first time)
- PoC-S49: implementation of other GGML OPs using QNN API
- PoC-S51: resource management of internal QNN resources in ggml-qnn.cpp(done on 04-21-2024)
- PoC-S52: multi-threading not support using QNN GPU/DSP backend in ggml-qnn.cpp(updated on 04-22-2024, multithreading works fine using QNN CPU backend)
- PoC-S53: stability issue during toggle between different backend(QNN CPU/GPU/DSP backend, ggml...)(updated on 04-22-2024, find out the rootcause and done)
- PoC-S54: validate with llama.cpp using QNN backend(updated on 04-22-2024, works as expected)
- PoC-S61: refine code(remove dependence......) and prepare to submit to upstream GGML(done on 04-23-2024)
- PoC-S62: merge code to master branch(done on 04-23-2024)
- PoC-S63: PR aux-code to upstream whisper.cpp (done)
- PoC-S64: PR aux-code to upstream llama.cpp (done)
- PoC-S65: merge source code from upstream llama.cpp(merge upstream codes, validation with whisper asr benchmark, validation with llama inference), refine code......(done on 04-24-2024: whisper.cpp and llama.cpp works fine/well using QNN CPU/GPU/HTP(aka DSP) backend on Xiaomi 14(a high-end Android phone based on Qualcomm's state-of-the-art mobile SoC)
- PoC-S66:PR ggml-qnn.cpp&ggml-qnn.h to upstream llama.cpp(because llama.cpp is the main playground of ggml)done on 04-24-2024)
 chiwwang
chiwwang tongji1907
tongji1907 caofx0418
caofx0418 nihui
nihui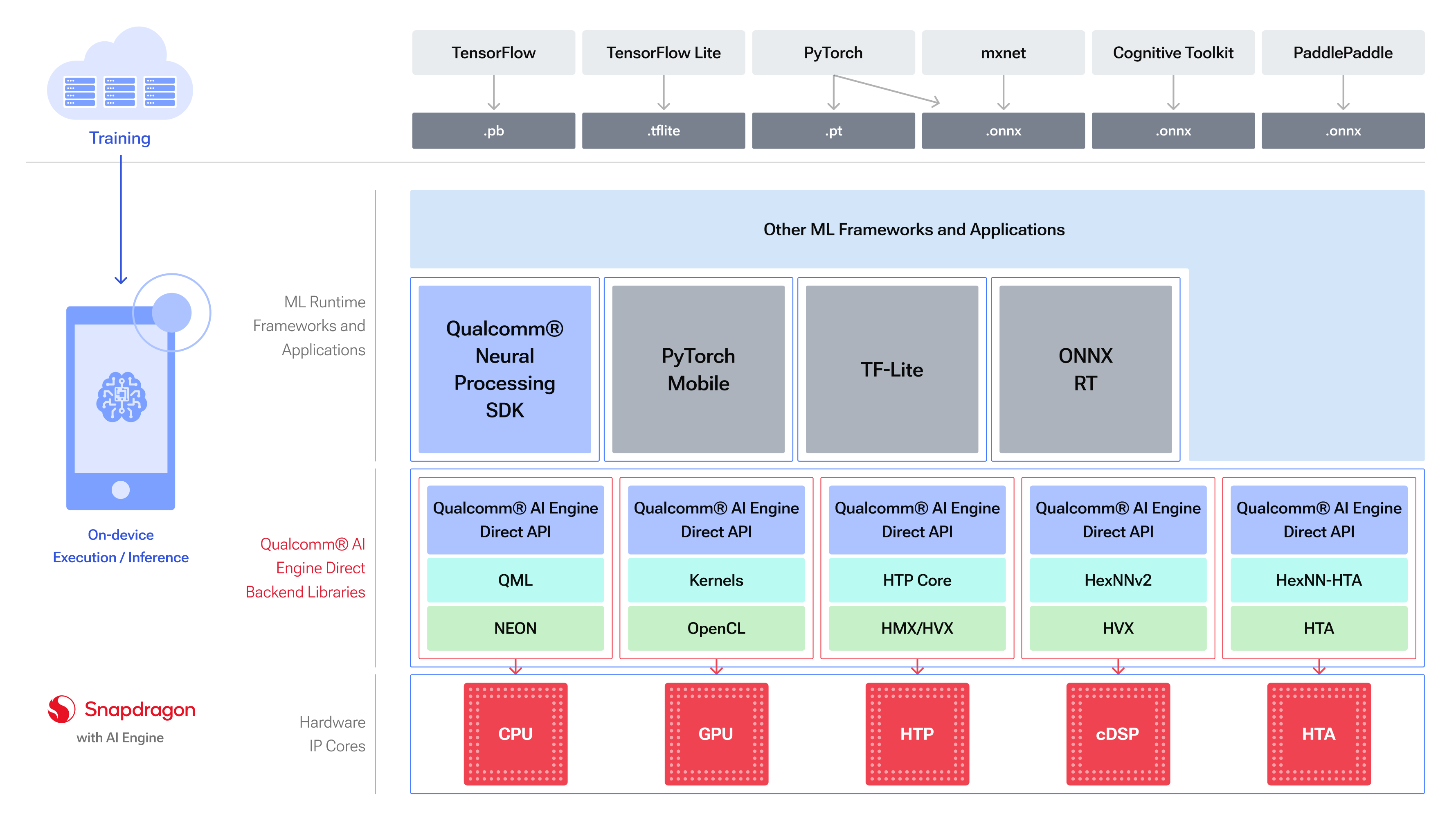{kind=link}
Background of this PoC:
1.GGML is a very compact/highly optimization pure C/C++ machine learning library. GGML is also the solid cornerstone of the amazing whisper.cpp and the magic llama.cpp. Compared to some well-known machine learning frameworks/libraries (e.g. Google TensorFlow, Microsoft ONNX, Meta PyTorch, Baidu PaddlePaddle......), GGML does not have much/complex/complicated/redundant/… encapsulation, so it's very very very useful/helpful/educational for AI beginner(such as me). <!--By studying the internals of GGML, you will know what real AI is and what is behind LLM models and how these AI models work in less than 1 month(less than 2 weeks if your IQ is above 130 ------ the baseline IQ to enter China's top university(China has a population of 1.4 billion and there are only about 50 top domestic universities), less than 1 week if your IQ is above 150 ------ original author of FFmpeg, original author of TensorFlow, original author of TVM, original author of Caffe, original author of GGML). Another thing, tracking code and coding with the GGML API in real task is a good way to study the internals of GGML.--> In general, GGML has following features:
Written in C
16-bit float support
Integer quantization support (4-bit, 5-bit, 8-bit, etc.)
Automatic differentiation
ADAM and L-BFGS optimizers
Optimized for Apple Silicon
On x86 architectures utilizes AVX / AVX2 intrinsics
On ppc64 architectures utilizes VSX intrinsics
No third-party dependencies
Zero memory allocations during runtime
all in one source file and similar to imgui(this is just personal opinion and I really like it, this is a NEW coding style and the requirements for programmer is relatively high and very helpful for experienced programmer, this coding style may not be acceptable in large commercial IT companies because it violates some principles of modern software engineering)
There are four "killer/heavyweight" AI applications based on GGML:
Audio2Text(aka ASR) whisper.cpp
Running LLM locally llama.cpp
Text2Image stable-diffusion.cpp
Text2Speech(aka TTS) bark.cpp
There are also some open source C/C++ open source AI projects/examples based on GGML:
[X] Example of GPT-2 inference examples/gpt-2
[X] Example of GPT-J inference examples/gpt-j
[X] Example of LLaMA training ggerganov/llama.cpp/examples/baby-llama
[X] Example of Falcon inference cmp-nct/ggllm.cpp
[X] Example of BLOOM inference NouamaneTazi/bloomz.cpp
[X] Example of RWKV inference saharNooby/rwkv.cpp
[x] Example of SAM inference examples/sam
[X] Example of BERT inference skeskinen/bert.cpp
[X] Example of BioGPT inference PABannier/biogpt.cpp
[X] Example of Encodec inference PABannier/encodec.cpp
[X] Example of CLIP inference monatis/clip.cpp
[X] Example of MiniGPT4 inference Maknee/minigpt4.cpp
[X] Example of ChatGLM inference li-plus/chatglm.cpp
[X] Example of Qwen inference QwenLM/qwen.cpp
[X] Example of YOLO inference examples/yolo
[X] Example of ViT inference staghado/vit.cpp
[X] Example of multiple LLMs inference foldl/chatllm.cpp
Xiaomi 14 was released in China on 10-26-2023 by one of China’s largest mobile phone giants, Xiaomi 14 was available in Euro since 02-25-2024. Xiaomi 14 contains a very very very powerful mobile SoC------Qualcomm SM8650-AB Snapdragon 8 Gen 3 (4 nm).
Qualcomm is No.1 mobile SoC semiconductor company in our planet currently(MediaTek's market share is No.1 in Q1 2024 but I personally think Qualcomm is the real No.1 mobile SoC vendor in our planet). QNN(Qualcomm Neural Network, aka Qualcomm AI Engine Direct) SDK is verified to work with the following versions of the ML frameworks:
after spent 3 days(from 03-26-2024 to 03-28-2024) on llama.cpp
I want to add Qualcomm mobile SoC native backend for GGML for personal interest or purpose of study AI/machine learning( and study internal mechanism of GGML).
This PoC is a much more difficult task for me because it's my first time using Qualcomm QNN SDK and I don't know anything about real/hardcore AI /machine learning tech.
I'm not sure I can do it this time but I just want to try(and practice my C/C++ programming and troubleshooting skill). so there is NO timeline in this PoC(might be break at any point in the future).
so the integration work of SYCL will provide a huge/significant reference for this POC:we can learn something from what the Intel R&D team has done with ggml-sycl(ggml-sycl.h, ggml-sycl.cpp).
PR or any help(from AI expert, from upstream GGML community, from Qualcomm, from Xiaomi(the most important customer of Qualcomm in China)......) are both greatly welcomed. Guidance from domain-expert is greatly appreciated if there is a problem in path/direction of this PoC.
All codes in this PoC will be open-sourced in this project and want to be submitted to upstream GGML community as ggml-qnn.h&ggml-qnn.cpp if it's considered or accepted.