Project 2
Group 2 Members
- Jeffrey Magina
- Jay Patel
- Jeremy Tran
- Pejal Rath
Introduction
The main focus of this project is to get familiar with the data pipeline process. The project utilizes Java, AWS-EMR Cluster, AWS-S3 Bucket, AWS-RDS, Tomcat, Apache Spark, PostgresSQL, HttpServlet and HTML. In AWS-S3 bucket, there is a CSV file that contains raw data related to hotel booking.
Project Flow
- The program will load the CSV file from S3 bucket, perform Spark transformatons on the raw data and save it back to S3 bucket in CSV file format. The process of loading the CSV file from S3 will be handled by EMR instance.
- The program will load all the CSV files that were generated by Spark transformations, build a SQL table for each CSV file and save it to a AWS RDS PostgresSQL remote database.
- The program will host a Tomcat Server where user can inquiry for each table inside the database located inside AWS-RDS.
How To Perform Spark Transformation On Raw Data And Save Back To AWS-S3 Bucket
./copyAndRunSparkJobJar.sh ~/.ssh/"keypair".pem spark-job-1.0-SNAPSHOT.jar
How To Save Each CSV File That Contained Processed Data In AWS RDS PostgreSQL Database
./sendFromS3toDB.sh
How To Host Tomcat Server For User Inquiry
./runServer.sh
Example Of How To Operate The Application
Example 1: Copy Jar File To EMR Cluster And Perform Spark Transformation
Expected Input:
./copyAndRunSparkJobJar.sh ~/.ssh/spark-demo.pem spark-job-1.0-SNAPSHOT.jar
Expected Output:
S3 Bucket
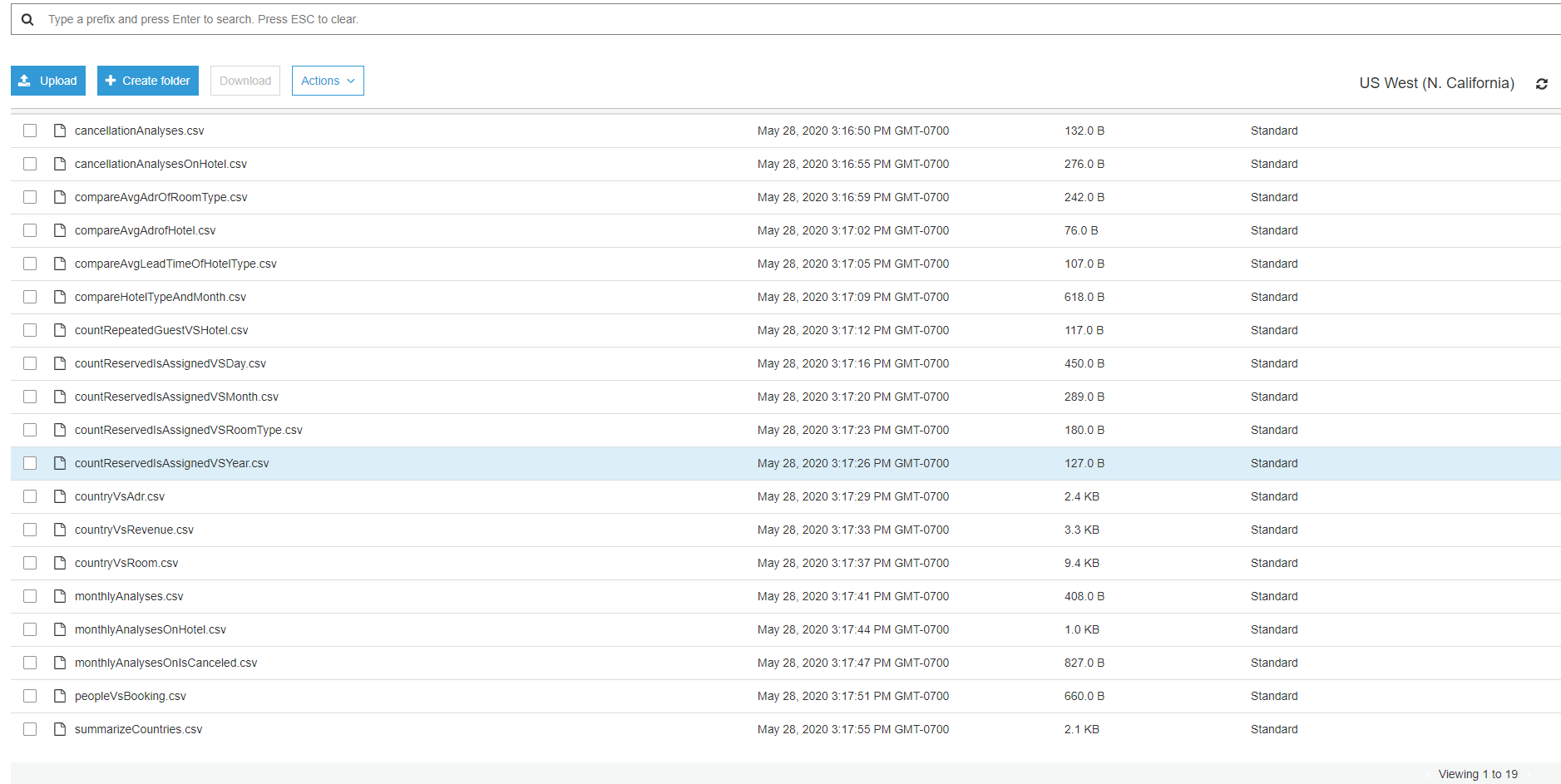
Example 2: Build Table For Each CSV File And Save To Database
Expected Input:
./sendFromS3toDB.sh
Expected Output:

Example 3: Host Tomcat Server For User Inquiry
Expected Input:
Terminal
./runServer.sh
Web browser
http://localhost:8080/group2/project2.html
Expected Output:
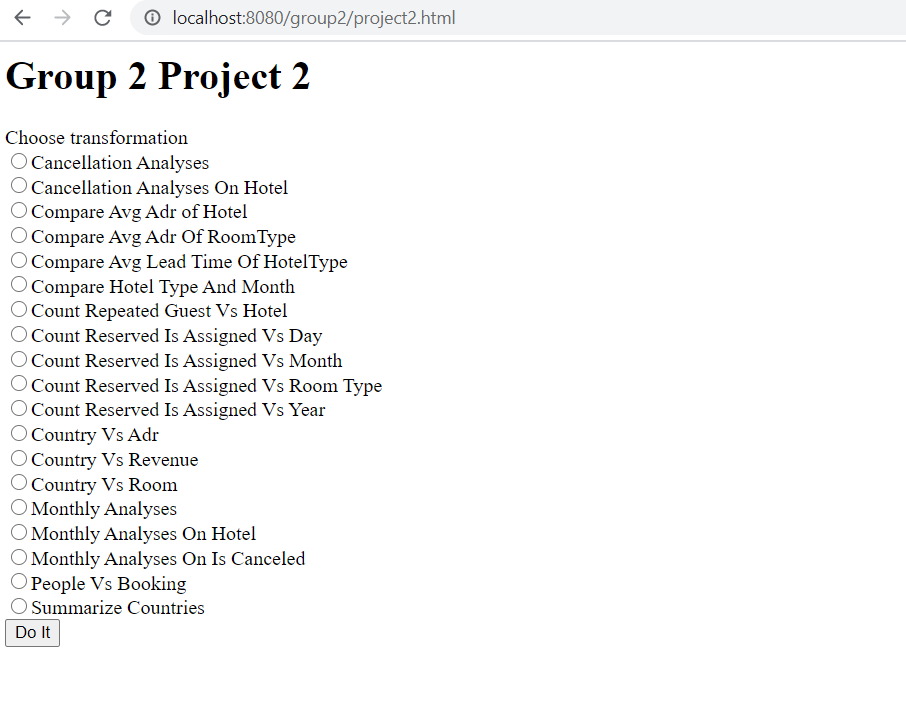
Example 4: User Inquiry "People Vs Booking"
Expected Input:
Web browser

Expected Output:
