3D-VisTA: Pre-trained Transformer for 3D Vision and Text Alignment
Ziyu Zhu, Xiaojian Ma, Yixin Chen, Zhidong Deng📧, Siyuan Huang📧, Qing Li📧
This repository is the official implementation of the ICCV 2023 paper "3D-VisTA: Pre-trained Transformer for 3D Vision and Text Alignment".
Paper | arXiv | Project | HuggingFace Demo | Checkpoints
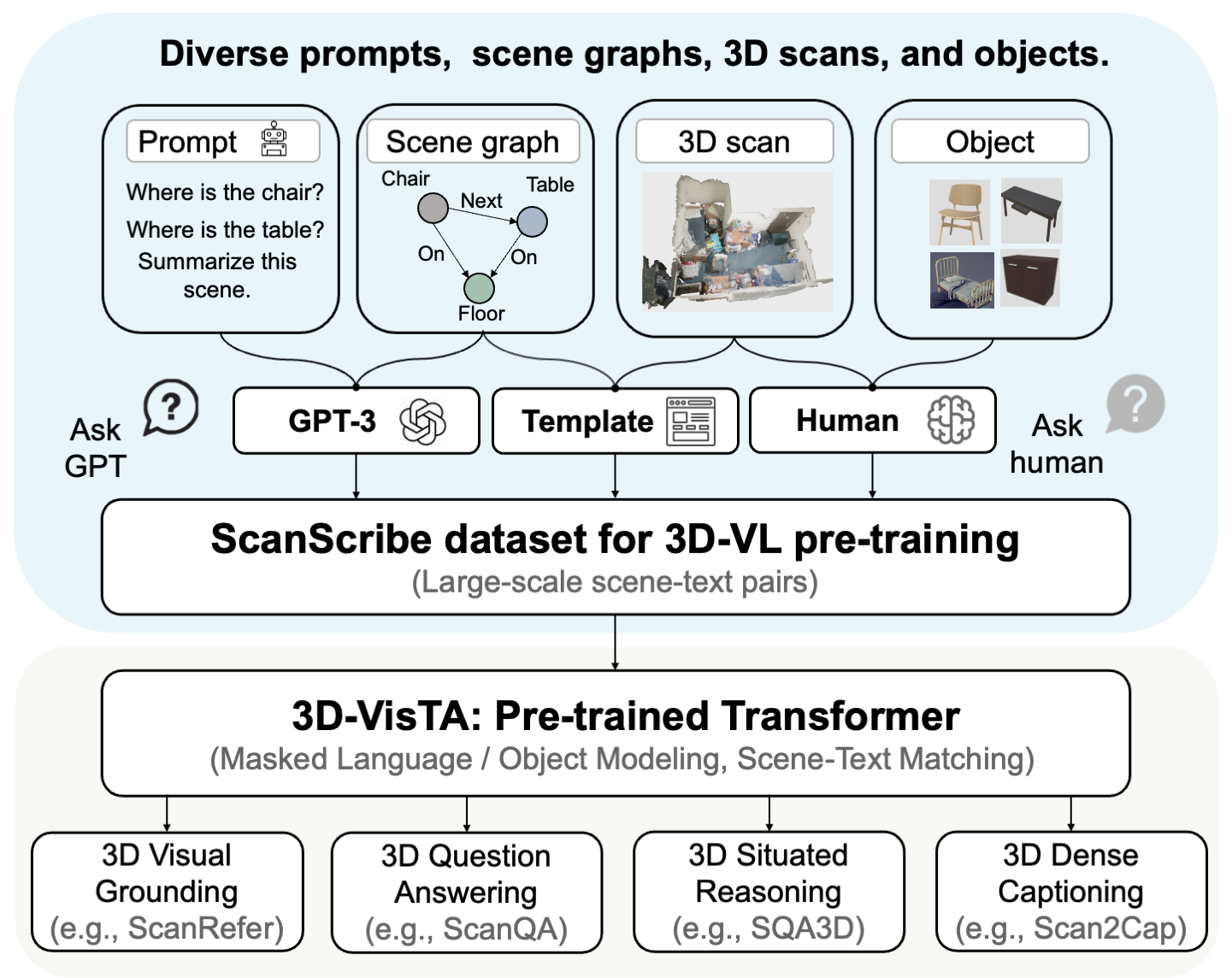
Abstract
3D vision-language grounding (3D-VL) is an emerging field that aims to connect the 3D physical world with natural language, which is crucial for achieving embodied intelligence. Current 3D-VL models rely heavily on sophisticated modules, auxiliary losses, and optimization tricks, which calls for a simple and unified model. In this paper, we propose 3D-VisTA, a pre-trained Transformer for 3D Vision and Text Alignment that can be easily adapted to various downstream tasks. 3D-VisTA simply utilizes self-attention layers for both single-modal modeling and multi-modal fusion without any sophisticated task-specific design. To further enhance its performance on 3D-VL tasks, we construct ScanScribe, the first large-scale 3D scene-text pairs dataset for 3D-VL pre-training. ScanScribe contains 2,995 RGB-D scans for 1,185 unique indoor scenes originating from ScanNet and 3R-Scan datasets, along with paired 278K scene descriptions generated from existing 3D-VL tasks, templates, and GPT-3. 3D-VisTA is pre-trained on ScanScribe via masked language/object modeling and scene-text matching. It achieves state-of-the-art results on various 3D-VL tasks, ranging from visual grounding and dense captioning to question answering and situated reasoning. Moreover, 3D-VisTA demonstrates superior data efficiency, obtaining strong performance even with limited annotations during downstream task fine-tuning.
Install
-
Install conda package
conda env create --name 3dvista --file=environments.yml -
install pointnet2
cd vision/pointnet2 python3 setup.py installPrepare dataset
-
Follow Vil3dref and download scannet data under
data/scanfamily/scan_data, this folder should look like./data/scanfamily/scan_data/ ├── instance_id_to_gmm_color ├── instance_id_to_loc ├── instance_id_to_name └── pcd_with_global_alignment -
Download scanrefer+referit3d, scanqa, and sqa3d, and put them under
/data/scanfamily/annotations
data/scanfamily/annotations/
├── meta_data
│ ├── cat2glove42b.json
│ ├── scannetv2-labels.combined.tsv
│ ├── scannetv2_raw_categories.json
│ ├── scanrefer_corpus.pth
│ └── scanrefer_vocab.pth
├── qa
│ ├── ScanQA_v1.0_test_w_obj.json
│ ├── ScanQA_v1.0_test_wo_obj.json
│ ├── ScanQA_v1.0_train.json
│ └── ScanQA_v1.0_val.json
├── refer
│ ├── nr3d.jsonl
│ ├── scanrefer.jsonl
│ ├── sr3d+.jsonl
│ └── sr3d.jsonl
├── splits
│ ├── scannetv2_test.txt
│ ├── scannetv2_train.txt
│ └── scannetv2_val.txt
└── sqa_task
├── answer_dict.json
└── balanced
├── v1_balanced_questions_test_scannetv2.json
├── v1_balanced_questions_train_scannetv2.json
├── v1_balanced_questions_val_scannetv2.json
├── v1_balanced_sqa_annotations_test_scannetv2.json
├── v1_balanced_sqa_annotations_train_scannetv2.json
└── v1_balanced_sqa_annotations_val_scannetv2.json- Download all checkpoints and put them under
project/pretrain_weights
| Checkpoint | Link | Note |
|---|---|---|
| Pre-trained | link | 3D-VisTA Pre-trained checkpoint. |
| ScanRefer | link | Fine-tuned ScanRefer from pre-trained checkpoint. |
| ScanQA | link | Fine-tined ScanQA from pre-trained checkpoint. |
| Sr3D | link | Fine-tuned Sr3D from pre-trained checkpoint. |
| Nr3D | link | Fine-tuned Nr3D from pre-trained checkpoint. |
| SQA | link | Fine-tuned SQA from pre-trained checkpoint. |
| Scan2Cap | link | Fine-tuned Scan2Cap from pre-trained checkpoint. |
Run 3D-VisTA
To run 3D-VisTA, use the following command, task includes scanrefer, scanqa, sr3d, nr3d, sqa, and scan2cap.
python3 run.py --config project/vista/{task}_config.ymlAcknowledgement
We would like to thank the authors of Vil3dref and for their open-source release.
News
- [ 2023.08 ] First version!
- [ 2023.09 ] We release codes for all downstream tasks.
Citation:
@article{zhu2023vista,
title={3D-VisTA: Pre-trained Transformer for 3D Vision and Text Alignment},
author={Zhu, Ziyu and Ma, Xiaojian and Chen, Yixin and Deng, Zhidong and Huang, Siyuan and Li, Qing},
journal={ICCV},
year={2023}
}