![]()
![]()
pytreedb is a Python software package providing an object-based library to provide a simple database interface and REST API of vegetation tree objects that were captured as 3D point clouds. The main objective is to provide a Python library for the storage and sharing of single tree-based point clouds and all relevant (forest inventory) tree measurements. The tree data include all tree related information, measurements, metadata, geoinformation and also links to the 3D point clouds linked in any file format (e.g. LAS/LAZ). GeoJSON including all tree-related information is used as data format for data exchange and visualization with other software (e.g. direct import into most GIS). Thereby view and modification of the tree datasets (*.geojson) is straightforward.
MongoDB is used as database backend via the PyMongo driver. This enables scaling to large global datasets, e.g. connecting to MongoDB Atlas Cloud for big datasets. Working only locally using a local MongoDB installation is also possible, if the database is only needed during runtime of data processing and sharing on the Web is not required.
Main Features
pytreedb has three main components and usage directions:
- Python library: In case you need to access the tree database in your Python scripts during runtime of data processing and analysis.
- REST API: In case you want to provide your datasets to any software over a REST API. The
pytreedbserver application is using the Flask framework for local(host) usage and we provide instructions to setup for production deployment with Apache WGSI. Further info on the REST API ofpytreedbcan be found here, e.g. including setup of server and usage of API keys. - Web frontend: In case you want to share your valuable tree data to the community. Based on the REST API we showcase in this repository how a Web frontend can be easily implemented, which provides several query options, data export and also map views of query results. A showcase presenting the tree data of Weiser et al. 2022 is given on http://pytreedb.geog.uni-heidelberg.de/.
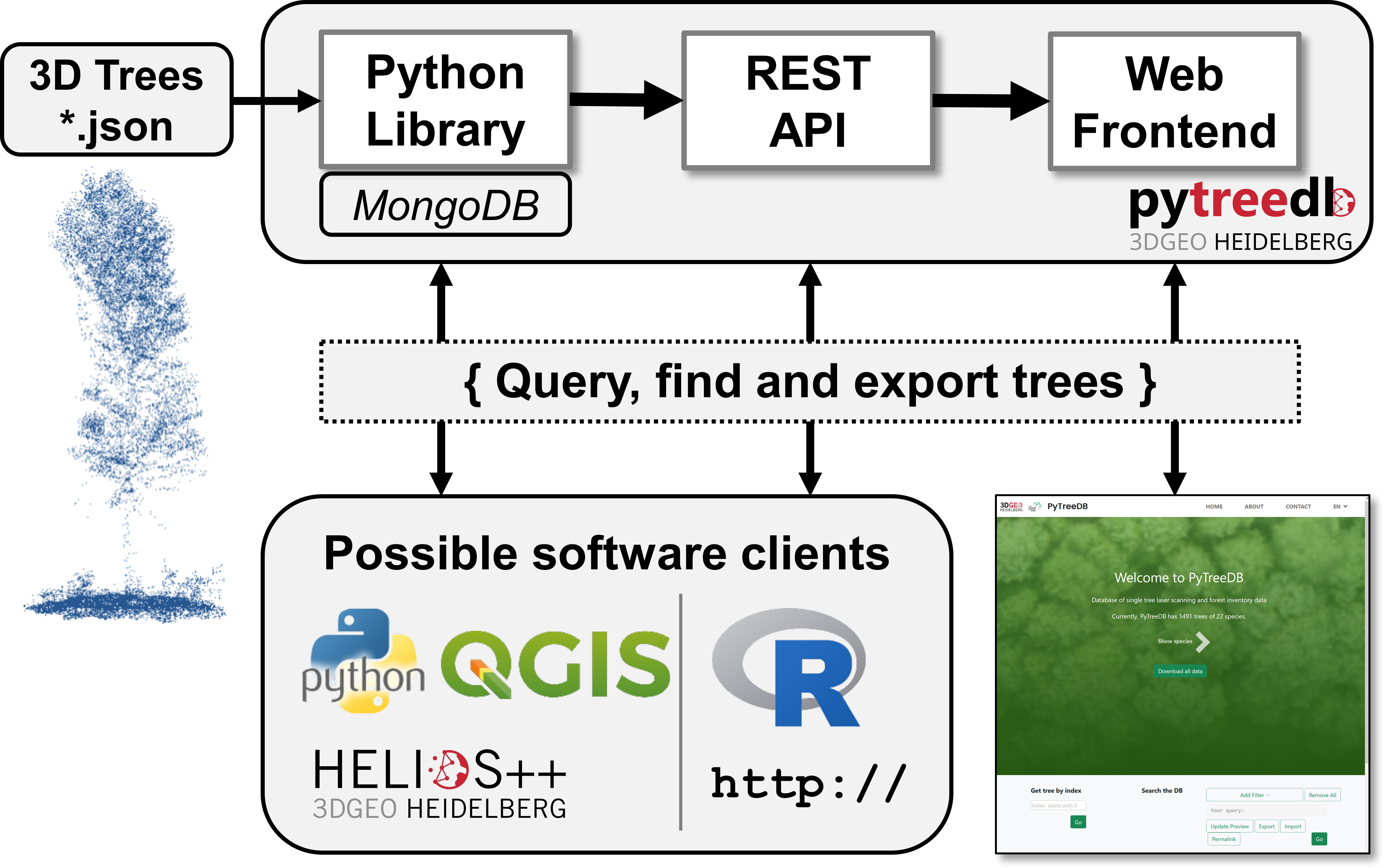
The PyTreeDB class is the starting point and the core component. It is responsible, e.g., for
- data import, data export, data validation, automatic sync with MongoDB
- all kind of queries.
The Python REST interface and all clients, such as the web frontend, simply use the methods and functionality of the Python class.
The main concept of the pytreedb software was explained in a scientific talk by Bernhard Höfle at the 3DForEcoTech Workshop in Prague in 2022:
💻 Download and Installation
Installation
Install and update using pip for 1) core library and 2) server library using the core library:
1) Core library
$ pip install -U pytreedb
2) Server library
$ pip install -U pytreedb-server
Alternative Installation
Clone this Repo and Use Anaconda Environment
Clone this repository with git clone and use it as your working directory.
Simply use the given Anaconda environment file environment.yml provided in this distribution, which contains all dependencies to run and build resources.
$ conda env create --file environment.yml --force
Instead, you can also install the dependencies from the requirements file with pip.
$ python -m pip install -r requirements.txt
or the entire package:
$ python -m pip install .
Finally, if you want to contribute to the library's development you should also install its additional Python dependencies for testing and documentation building:
$ python -m pip install -r requirements-dev.txt
Connect to MongoDB (localhost / server / Atlas cloud)
pytreedb requires a working connection to a MongoDB database. It does not matter where the MongoDB is running as connection is simply made via pymongo (see code in examples and our Jupyter notebooks). We successfully tested localhost, server and MongoDB Atlas cloud connections. For your own MongoDB installation, just follow the official installation instructions).
The required MongoDB connection with credentials is made with a .env file (yes, the file has no name) that you place in the folder of your Python scripts or search path. dotenv is used for providing credentials - 1) URI to server, 2) database and 3) collection name - outside your source code (see sample.env as template).
Example .env file for connection to local MongoDB installation. ℹ️ Replace
CONN_URI = "mongodb://127.0.0.1:27017/"
CONN_DB = "<database_name>"
CONN_COL = "<collection_name>"Example CONN_URI in .env file for connection to MongoDB Atlas cloud where the respective settings need to be replaced with yours:
CONN_URI = "mongodb+srv://<username>:<password>@<your_cluster_details>.mongodb.net/<database_name>?retryWrites=true&w=majority"Software Dependencies
All dependencies (i.e. required third-party Python packages) are listed in the Anaconda environment.yml definition and can be installed with conda / pip. When creating the conda environment from our definition file, all dependencies are resolved.
Documentation of Software Usage
PyTreeDB class 🐍
As a starting point, please have a look to the examples and Jupyter Notebooks available in the repository. Further, each of the subfolders contains a README.md with respective details on the repository section.
Run it as a API server 💻
In order to provide a REST API to share your tree data you can use pytreedb in server mode. After installation of the pytreedb-server Python package you can follow the instructions here webserver/README.md.
Run it as a web server and frontend
An example web frontend instance is running here: http://pytreedb.geog.uni-heidelberg.de/. The respective instructions and codes to install a webpage via the pytreedb-server Python package can be found in the webserver code section of pytreedb: pytreedb/webserver. Web frontend codes can be easily adapted to your needs - see web programming codes in static and templates.
Use it as via the REST API also from other programming languages (e.g. R stats)
Straightforward access from any programming language is made possible via the REST API. We provide examples scripts for http API access, e.g. for R statistics in examples_api. The R function example allows simple query and also download of the LAZ files for all trees of the query result.
GeoJSON Format and Template
An example tree is given in data/geojson/AbiAlb_BR03_01.geojson and the GeoJSON template for tree objects is defined here pytreedb/db_conf.py.
The single tree information (incl. URLs to the point clouds) has to be provided as GeoJSON file per tree. We use a straightforward format that is a valid GeoJSON and can be opened with any GIS software. The main idea of the pytreedb GeoJSON format is to define a minimum set of tree metadata, which can be extended by any further data that is needed by the user. Thus, it is just required that your GeoJSON file complies with the minimum set to enable import into the database. The PyTreeDB class offers the method validate_json to check the validity of the file. Also the import of files checks the validity automatically and will only import tree objects that are conformal with the defined template. The used GeoJSON template can also be modified for your use case and application. Note that modification (e.g. removal of mandatory fields from our template) will - most probably - require modifications for the API and web frontend component.
Published Test Data
In this repository we provide metadata (incl. links to point clouds) of 1481 trees that have been captured with airborne (ALS), UAV-borne (ULS) and terrestrial (TLS) laser scanning as well as field inventory data. Please check our data publication by Weiser et al. 2022 in Earth System Science Data (https://doi.org/10.5194/essd-14-2989-2022) for full details.
The test data is provided in data as 1) single GeoJSON files and as ZIP archive, and 2) also as serialized and zipped pytreedb database dump files that can be directly imported and used to start the API server.

Citation
Please cite the following publication when using pytreedb in your research and reference the appropriate release version. All releases of pytreedb are listed on Zenodo where you will find the citation information including DOI.
Höfle, B., Qu, J., Winiwarter, L., Weiser, H., Zahs, V., Schäfer, J. & Fassnacht, F. E. (2023). pytreedb - library for point clouds of tree vegetation objects (1.0.0). Zenodo. https://doi.org/10.5281/zenodo.7551310
@software{hofle_bernhard_2023_7551310,
author = {Höfle, Bernhard and
Qu, Jiani and
Winiwarter, Lukas and
Weiser, Hannah and
Zahs, Vivien and
Schäfer, Jannika and
Fassnacht, Fabian E.},
title = {{pytreedb - library for point clouds of tree
vegetation objects}},
month = jan,
year = 2023,
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.7551310},
url = {https://doi.org/10.5281/zenodo.7551310}
}Funding / Acknowledgements
The initial software development was supported by the DFG - German Research Foundation (Grant no. 411263134) within the research project SYSSIFOSS.
![]()
Contact / Bugs / Feature Requests
You think you have found a bug or have specific request for a new feature. Please open a new issue in the online code repository on Github. Also for general questions please use the issue system.
Scientific requests can be directed to the 3DGeo Research Group Heidelberg and its respective members.
📜 License
See LICENSE.md