This is an mmap-based ParallelZipFile implementation since Python's ZipFile is currently (2022-01-01) not thread safe.
Gotchas:
- Only reading is supported. Writing zip archives is not supported.
- Only a very limited subset of the zip specification is implemented ("good enough" for my use cases).
- By default, file integrity (CRC32) is not checked.
- There probably are bugs. Use at your own risk.
Example
Example for reading and checking file integrity of files in a zip archive in parallel using a ThreadPool. Just copy parallelzipfile.py into your project directory and you are good to go.
import zlib
from multiprocessing.pool import ThreadPool
from parallelzipfile import ParallelZipFile as ZipFile
def do_something_with_file(info):
"""Checking file integrity."""
data = z.read(info.filename)
computed_crc = zlib.crc32(data)
assert computed_crc == info.CRC
with ZipFile("example.zip") as z:
with ThreadPool() as pool:
pool.map(do_something_with_file, z.infolist())Benchmark
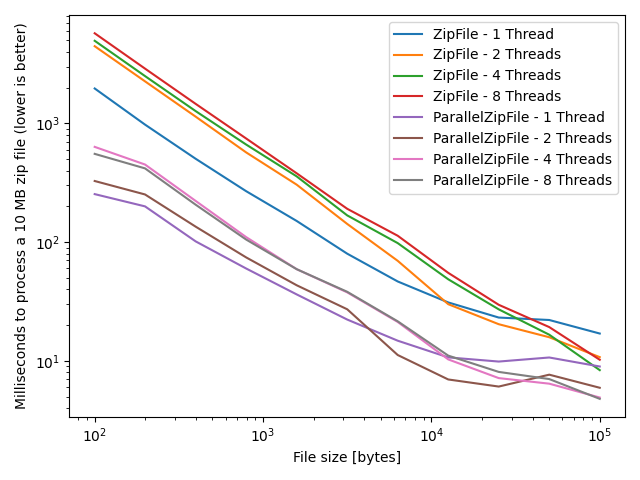
This plot shows how long it takes to process a 10 MB zip archive containing files of increasing size with 1, 2, 4 or 8 threads using ZipFile or ParallelZipFile. The zip archive contains fewer files as the file size of the contained individual files grows to keep the total size of the zip archive approximately the same (header sizes not considered).
- For very small files, single threaded performance is higher than multi-threaded performance, but multi-threaded performance is higher for medium to large files.
- ParallelZipFile is faster than ZipFile with almost any number of threads. The difference decreases with larger files.
- The optimal number of threads depends on the file size.
- This is a logarithmic plot, so differences are larger than they might appear at first glance.
Benchmark details
Benchmarks were run on an Intel Core i5-10300H processor (4 cores) on Xubuntu 20.04. Results are the average of ten runs (median looks about the same). All data is "hot", i.e. cached in RAM.
TODO
Find out why single threaded performance is higher than multi-threaded performance for small files. The following points have been investigated so far:
- Congestion due to dict lookup of ZipInfo objects - roughly the same performance when using a cloned dict for each thread.
- Reading of End-of-Central-Directory header not parallel - only makes up a very small percentage of total running time.
- Using processes instead of threads - much slower due to overhead of starting a new process.
- Thread scheduling overhead - processing multiple files at once with each thread performs about the same.