-
Hello, I would like to ask why the choice of glove embeddings is Common Crawl and the choice of agwe embeddings is librispeech in the code. Shouldn't the choice of glove embeddings also be librispeech
-
## 0. Paper
@inproceedings{vulic-mrksic-2018-specialising,
title = "Specialising Word Vectors for Lexical Entailment",
author = "Vuli{\'c}, Ivan and
Mrk{\v{s}}i{\'c}, Nikola",
…
a1da4 updated
3 years ago
-
All word models logic currently happens entirely in python, with vector-related logic handled by gensim.
We might consider storing this data in elasticsearch instead. Basically, you could make a `p…
-
We could do things without a vector database in order to simplify things, here's how:
A new issue is posted
We ask ChatGPT to extract a word list of the most "important" (i.e. unique adjectives?) …
-
Hi all — thanks for all your work on this package and documentation. I’m just getting into word embeddings and all of your resources have been incredibly helpful.
I was excited to see the new “get…
-
在wikipāli1.0阶段,我们实现了 #14 相似句功能,
## 发现的问题
1. 对于长度差距较大的相似句,比如一句拆解成两句的,无法识别(例句待补充)
2. 对于重复出现的句子,会用`…pe…`来把重复部分省略,而在实际翻译的时候,需要补出对应内容
3. 当前算法是单线程,没有实现多线程
## 未来展望
1. 升级算法,针对问题1实现匹配
2. 能够把含有`…pe…`和不…
-
Hello, thank you for your great work, may I ask what part of the implementation code of the Noise-Aware-Masking module, thank you
-
Hello!
Thank you very much for the work being done on this package. It has helped me tremendously.
I am finetuning the model on custom data, using the triplet function. It has worked like a char…
-
### Describe the problem
# Reviewing and verifying the translations submitted by the external contributors.
While the translations are submitted by the community, the software vendor is still both…
-
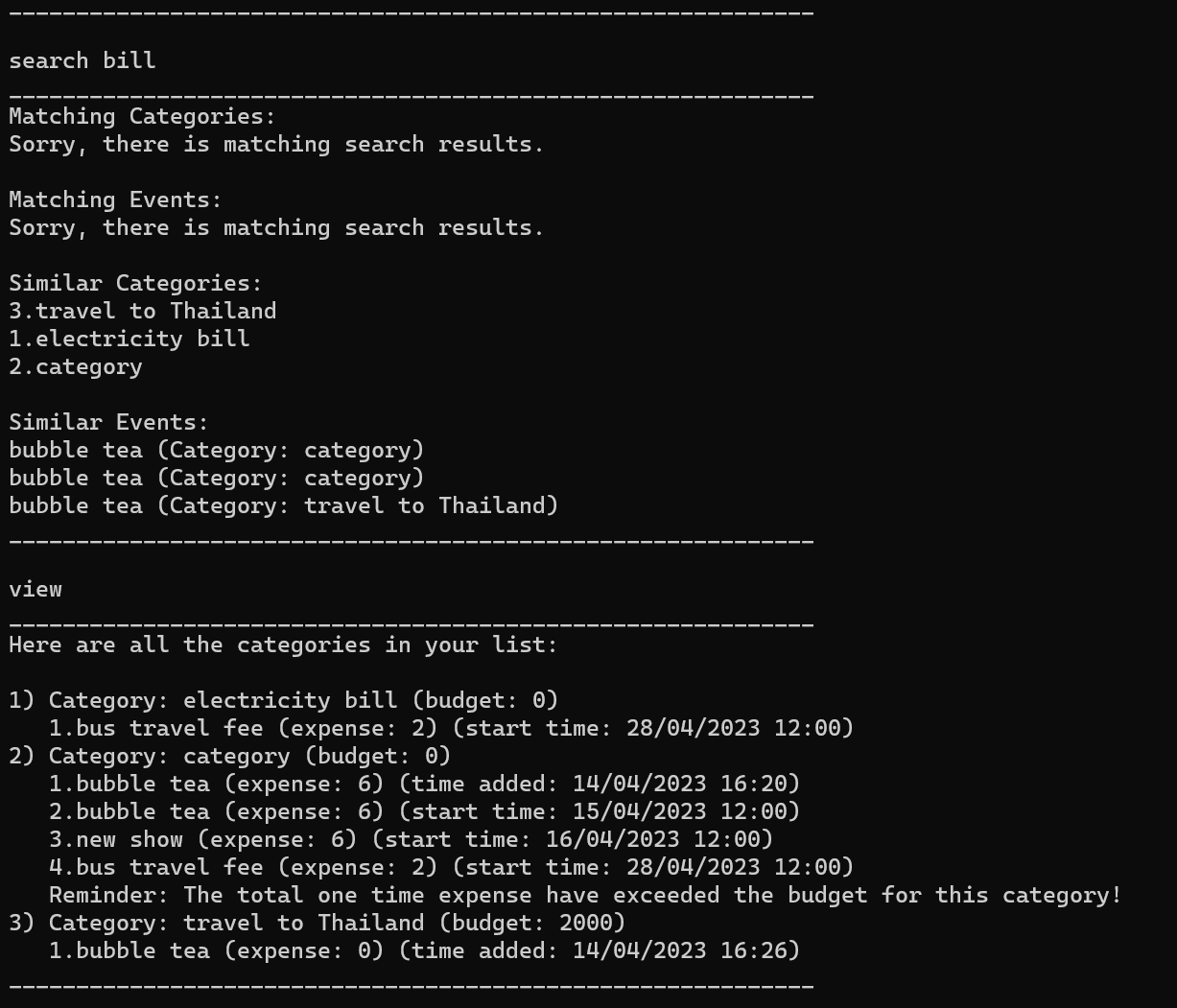
Search function has a feature showing similar category, but the similarity…