-
Right now the tokenizer decode method supports only a single instance at a time. I think it would be good to have `batch_decode` function and also support `skip_special_tokens` and `clean_up_tokenizat…
-
Hi, thank you very much for your excellent work !
I try to run the code using ChatGLM2, but the following error occurs:
Loading checkpoint shards: 100%|████████████████████████████████████████████…
-

* LLama-3 fine-tune problem:
When I use the Llama-3 configs, it encounters the load error while loading …
-
In `test_fstring` the test `test_comments` fails. We need to check if is due to regular tokenization problems and the test needs updating or we need to fix something regarding comments in f-strings
-
I am trying to use nnsight to load new LLMs, such as Qwen/Qwen2-VL-7B-Instruct.
qwen2_vl_model = LanguageModel("Qwen/Qwen2-VL-7B-Instruct", device_map="auto", dispatch=True)
The nnsight repor…
-
String with non-alphanumeric formatted content which has a next-char of an alpha-numeric is tokenized as `text` node, instead of into a series of format nodes as expected.
Problem reproduced on [Co…
-
Hi,
My software verification process got failed due to not requesting for AVS and CVV verification. The review team explained the app is not requesting for CVV and AVS verification.
Actually I des…
-
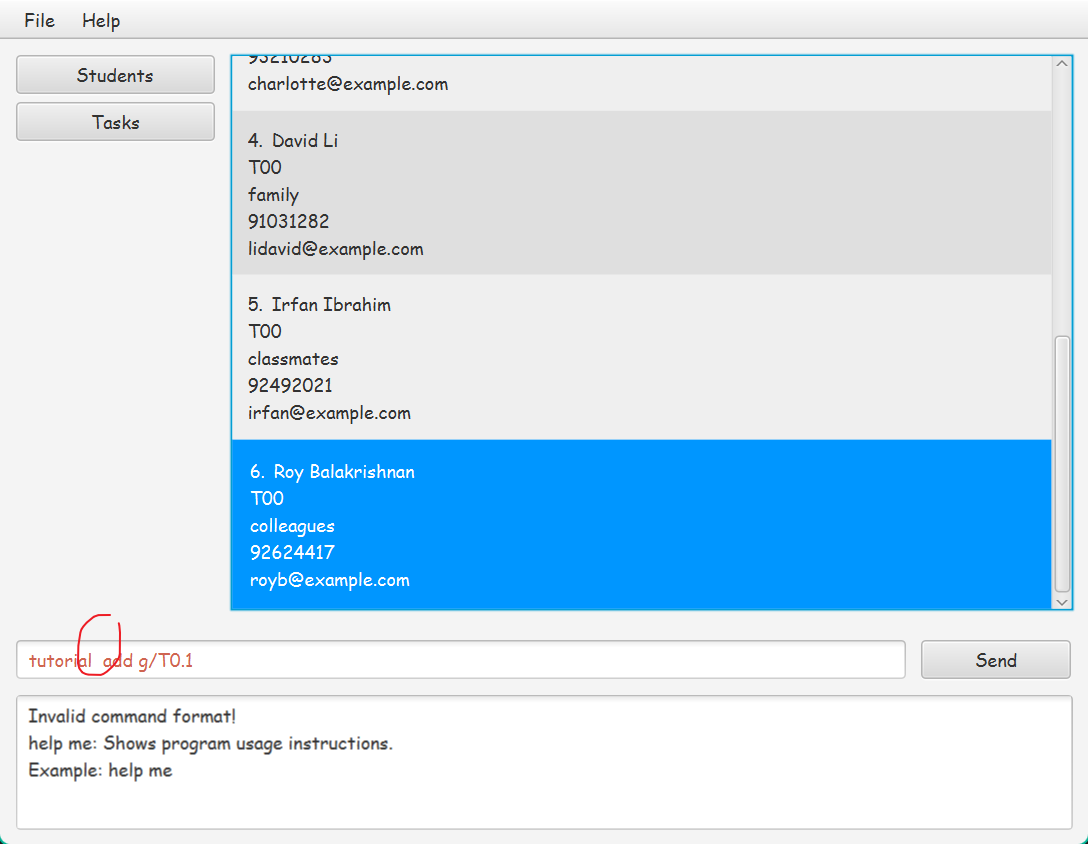
How to reproduce:
1. `tutorial add g/T0.1`
The tokenization does not work properly
…
-
- [x] Create README.md for dataset
- [x] Data Acquisition
- [ ] Data Cleaning
- [ ] Tokenization
- [ ] Artist Statistics
- [ ] n songs
- [ ] dates released
- [ ] vocabulary sizes
…
-
I think `dask` is a good solution because it has a nice API and can be used in a cluster.
The easiest and most effective parallelization is to map words after tokenization.